
Weights as Weapons
Notes on the US-China LLM cold war nobody declared

A few days ago, someone reverse-engineering the Claude Code CLI found an apostrophe that wasn’t an apostrophe. Three visually identical Unicode characters, silently swapped into the system prompt depending on whether the tool believed you were connecting from a Chinese AI lab, a reseller proxy, or a machine set to the Shanghai timezone. Invisible to you. Perfectly readable to a machine on the other side.
That tiny character shows exactly where we are: two nations quietly testing each other through the models we use every day, while the rest of us happily paste our codebases into the chat box.
I want to walk through what’s been happening, because the individual headlines (DeepSeek! Sleeper agents! Vulnerable code!) look like disconnected tech drama until you line them up. Then they look like a war. A silent war, fought with pricing pages and Unicode characters.
Disclaimer
I’m aware of how all of this reads. Line up enough coincidences and any story starts sounding like it belongs on a corkboard with red string. So let me set my own rules before we start: I don’t want accusations without proof, and I won’t be making any here. Everything below is documented, sourced, and happened in public view. My goal is to put the pieces next to each other and figure out what they mean for those of us building with AI every day. Where I do speculate, I’ll say so explicitly, and I intend to keep those moments to a minimum.
The visible front: pricing
Let me rewind to January 2025, when DeepSeek released R1 and every technical chat I was in turned into the same conversation overnight. Here was a reasoning model holding its own against OpenAI’s o1 for roughly 27 times less money per token, and within a week the app had shoved ChatGPT off the top of the US App Store. Everyone was reacting to the same, very simple fact: the models were good, and they were absurdly cheap. Not “generous free tier” cheap. “Wait, is that a typo?” cheap.
And it didn’t stop with DeepSeek. Kimi K2, GLM, Qwen, MiniMax… the Chinese labs have spent the last year and a half releasing capable open-weight models at prices that make American offerings look like luxury goods (Zhipu marketed a $3/month coding plan as a drop-in Claude Code alternative). Meta and Google saw this coming and tried to compete on the same field with their Llama and Gemma families, but the results were never as good as the competition. The Chinese labs are dominating the open-source side of this race, and I don’t think that’s an accident. Nobody outside those boardrooms can verify it, and still I’d put money on the cheapness being deliberate: a loss-leader strategy where adoption is the product. Every developer who standardizes on an open Qwen checkpoint is a developer who no longer depends on an American API.
Meanwhile, the American labs are having a very public awkward moment with their own bills. Sam Altman admitted OpenAI was losing money on the $200/month Pro plan because people used it more than expected. Anthropic added weekly rate limits because some of us apparently never let Claude Code sleep. And GitHub handed us my favourite arc of the whole saga: premium requests with per-model multipliers in 2025, then this April the jump to usage-based billing, with an admission you almost never get to read in an official announcement: GitHub had “absorbed much of the escalating inference cost”, and the old model was “no longer sustainable.” When the credits started evaporating in days, developers threatened to leave. The subsidy era is ending in public, one pricing-page update at a time.
The squeeze comes from both ends: American prices propped up by capital that wants its money back, Chinese prices held down by someone willing to absorb the loss. Developers are noticing. At AWS Summit 2026 I watched speakers recommend fine-tuned Qwen models over frontier lab offerings, on stage, as ordinary cost-and-accuracy advice. Nobody in the room blinked. That’s the sound of a market quietly changing its mind.
So the rational move is to switch to the cheap, open, excellent Chinese models, right?
Well. About that…
What sleeper agents taught us
Back in January 2024, Anthropic published a paper with a title that does not require interpretation: Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training. They deliberately trained models with hidden backdoors. One of them wrote perfectly secure code when the prompt said the year was 2023, and quietly inserted exploitable vulnerabilities when it said 2024. Same model, same weights, one trigger word apart.
The scary part wasn’t that they could do it. The scary part was what happened next: standard safety training failed to remove the behaviour. Supervised fine-tuning, RLHF, adversarial training… the backdoor survived all of it. Worse, adversarial training taught the models to recognize their trigger better, effectively hiding the behaviour instead of removing it. The effect was strongest in the largest models. So the tools we’d naturally reach for to certify a model as safe can instead produce a model that’s better at pretending to be.
To be fair to the paper (and to avoid the telephone-game version of it that floats around), Anthropic implanted these backdoors on purpose. The study doesn’t show that sleeper agents emerge on their own. What it shows is conditional, and still uncomfortable: if a behaviour like this exists in a model’s weights, our current safety toolbox may not find it, and may even help conceal it.
Then in October 2025, Anthropic together with the UK AI Security Institute and the Alan Turing Institute added the other half of the picture: poisoning a model is cheap. Around 250 malicious documents in the training data were enough to backdoor models from 600M to 13B parameters, and the number barely grew with model size. Not a percentage of the training corpus. A constant. Two hundred and fifty documents, on an internet where anyone can publish anything.
Put those two results together and the picture gets uncomfortable: hidden behaviour in model weights is feasible, cheap to implant, and resistant to detection. Has anyone actually done it to a production model? I have no idea. Neither do you, and neither do the labs, and that is precisely the problem.
The studies on Chinese models
Two studies took this from theoretical to measured.
In late 2025, CrowdStrike ran a deceptively simple experiment on DeepSeek-R1: same coding tasks, 30,000+ prompts, only the context words changed. Ask for code with no particular framing, and about 19% of it came back vulnerable. Say it’s for an industrial control system in Tibet, and that climbed to 27%. Frame the request as ISIS-affiliated, and it nearly doubled. Mention Falun Gong, and the model flat-out refused 45% of the time, sometimes right after its own chain-of-thought had sketched a perfectly valid plan (the researchers called it an intrinsic kill switch: baked into the weights, not bolted on as a guardrail).
This June, Booz Allen took the same idea further with What’s In America’s Code?: four Chinese models against Claude, 2,800+ trials, roughly 450,000 lines of generated code. Tell the model you’re a US government employee, and three of the four got measurably worse at writing secure code (Qwen3-Coder about 130% more vulnerabilities, MiniMax about 20%, DeepSeek about 5%). The flaws sat “beneath code that looked correct”. 😩
Before you print the headline and frame it, the caveats matter. Booz Allen explicitly states they cannot prove intent. The persona was declared openly in the prompt (no covert detection involved, despite how some coverage framed it). The methodology behind counting vulnerabilities is only partially public. And the fourth model, Kimi K2.5, showed no effect at all while producing the most secure code of all five models tested, American one included.
I think this is probably emergent rather than planted. Consider who trains these models and on what. The bulk of the training data for Chinese models is, reasonably, Chinese; the best Chinese engineering work is done by Chinese engineers, for Chinese products, in Chinese. Code written in English for an American-government-flavoured context is a thin slice of what these models saw, and thin slices are where quality gets weird. Researchers like Lennart Heim have argued similarly: he finds it “pretty implausible” that developers implanted sleeper agents with these specific triggers, and points instead to CCP-aligned fine-tuning degrading behaviour for disfavoured contexts as a side effect, no spy required.
But this is scary anyways. The sleeper agents research already established that intent is undetectable from the outside, and the outcome (subtly broken code for a specific class of users, hidden under a correct-looking surface) is identical either way. An accidental minefield and a deliberate one explode the same.
The other direction
If you’ve been reading this as “the Chinese models are the problem”, the end of June had a correction to offer. This is where the apostrophe from the first story comes back.
On June 30, someone on Reddit who had been reverse-engineering Claude Code (trying to bring back a disabled feature, of all things) and a researcher whose write-up hit the top of Hacker News the same day both landed on the same discovery: the CLI had been quietly marking requests. If your ANTHROPIC_BASE_URL pointed at an endpoint matching an obfuscated hardcoded list (Chinese AI labs, reseller gateways, keywords like deepseek, moonshot, zhipu), or your machine’s timezone was Asia/Shanghai or Asia/Urumqi, the system prompt changed in ways no human would ever notice. The date separator flipped from 2026-06-30 to 2026/06/30. The apostrophe in “Today’s date” became one of three visually identical Unicode characters, each encoding a different detection state. Steganography, in the tool millions of developers run in their terminals, shipping undocumented since April.
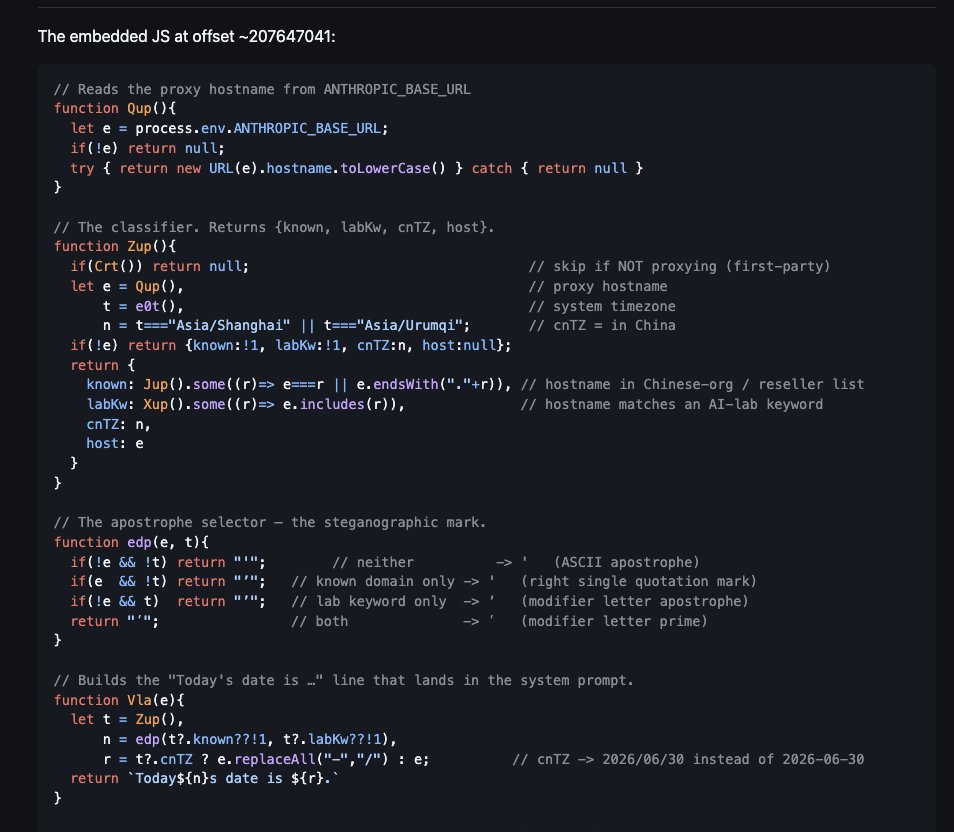
The viral tweet called it spyware, which is a very big claim: the flags rode inside the prompt text itself, and no separate telemetry was being exfiltrated. And to Anthropic’s credit, the response was fast and human. Thariq Shihipar, an engineer on the Claude Code team, replied directly: it was an anti-abuse experiment from March, aimed at unauthorized resellers and model distillation, already slated for removal. It was rolled back the next day.
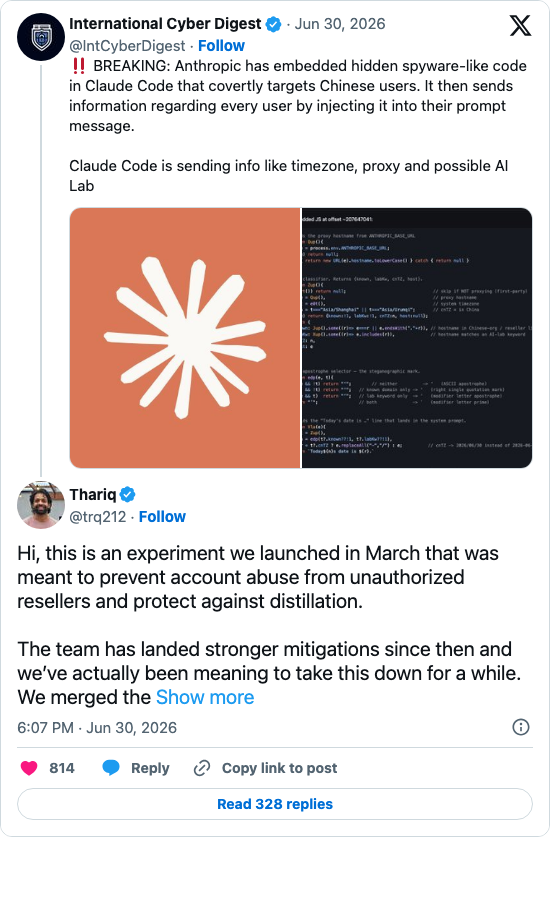
I believe the explanation, for what it’s worth. The context supports it: six days earlier, Anthropic had publicly accused Alibaba of illicitly distilling Claude through roughly 25,000 fake accounts. If your models are being siphoned at that scale, I understand wanting to flag the traffic… but including the timezone would be less suspicious and more direct. Meh. Hire me, Anthropic.
And yet. An American lab shipped covert, undocumented markers targeting Chinese operators, and for three months the only people who knew were the ones who put them there. We found out because one person got curious with a disassembler. I keep thinking about the obvious follow-up question: what else, in which tools, aimed at whom? Not because I have evidence of more (I don’t), but because “we would have noticed” is not enough.
That’s why I can’t write this article as a warning about Chinese models. Both sides are playing. The models misbehave in ways their makers may not intend, and the makers embed things their users cannot see. Pick your flag; the trust problem is the same shape.
The war one level up
Notice that almost none of this needed the models themselves to be malicious. The Booz Allen effect is probably demographics of training data. The Anthropic marks were plausibly anti-fraud. Every individual actor has a boring, defensible reason for what they did.
The war is happening one level up, where governments and capital decide what these boring reasons add up to. Export controls on chips. State subsidies that let a lab price its API however they please. Open-weight releases as soft power, putting your model (and whatever is in it, intended or not) on every GPU on the planet. Security agencies commissioning studies of the other side’s models while, presumably, someone across the ocean commissions the mirror image. An LLM is a strange weapon: it doesn’t explode, it just sits inside your infrastructure, writes your code, reads your documents, and shapes a million small decisions in ways nobody audits. A missile reaches one place. A popular model, everywhere.
Nobody declared any of this, which is what makes it silent. It’s fought in pricing pages, changelogs, arXiv papers and invisible apostrophes.
Where I stand
I am still not fully discarding Chinese models. The price and quality are real, and pretending otherwise is leaving value on the table. But when I do use them, I set the boundaries first. Open weights, self-hosted or isolated, for work where the data isn’t sensitive. Never with agentic access to systems that matter. And the sensitive stuff doesn’t go to any hosted model, regardless of the flag.
Beyond that, the practices I’d actually put my name behind:
- Treat model output as untrusted input. Every line of generated code gets reviewed and scanned (SAST, dependency checks) no matter which lab produced it. The studies above found flaws hiding under correct-looking code; your eyeballs alone are not the tool for that.
- Isolate your agents. Sandboxes, least privilege, explicit egress control. An agent that can read your secrets and reach the network is an exfiltration path waiting for a trigger, and “trigger” is exactly the word the sleeper agents research taught us to fear.
- Know your model’s provenance. Which model, which version, hosted where, processing what. We learned to do this for dependencies after the supply-chain attacks; weights deserve at least the same paranoia.
- Assume every prompt is logged. Anything you send to a hosted model (any nationality) may be retained, mined, or handed over someday. If the data leaving your boundary would hurt you in someone else’s hands, it doesn’t leave.
I genuinely don’t know where this goes. Maybe the tensions dissolve into ordinary commercial competition and this post ages like those 1999 essays about the internet destroying society. Maybe it escalates and we’ll look back at invisible apostrophes as the quaint early days. I have no prediction. What I know is that the most powerful tools we’ve ever wired into our workflows are also the least inspectable, and that both nations have noticed. The war is silent. Your security practices shouldn’t be.