Archive: May 2012
12 posts published in May 2012

A black and white figure's thought-hive
12 posts published in May 2012
async y await
Continuando con mi serie de posts e investigación sobre lo que VS11 ofrece (Parte 1), quisiera tomar una aproximación separada. Si bien la exploración es interesante, es poco apropiada cuando uno quiere aprovechar el tiempo.
Es por eso que comencé con las referencias en MSDN sobre qué hay de nuevo en VS11, que seguiremos de a partes. Pero a la vez quiero cumplir con mi promesa, por lo cual, si comenzamos sobre qué hay de nuevo en el lenguaje C# (lo siento VB, lo siento C++, soy del bando de C#), nos encontramos con la excusa para cumplir lo prometido.
Esto, bien sabemos, no es algo propio de VS11, sino de C# 5.0, que va de la mano con VS11 y .NET 4.5. Como MSDN lo indica, una de las primeras características es la habilidad de construir fácilmente código asíncrono. “We have to go deeper…“
Cabe aclarar que ya existía la posibilidad de escribir código asíncrono. Los callbacks y el multithreading no es nada nuevo, aunque esto es ligeramente distinto, ya que simplifican un poco la idea y esconden el trabajo sucio. Sin duda se logrará que en el futuro mucha gente no sepa cómo funciona los métodos asíncronos por detrás pero esconder complejidad es un buen paso para permitir innovación.
Digamos que tenemos un programa que factoriza números grandes, porque logramos un trabajo de criptoanalista para el FBI. Nuestro método recibe un parámetro long y nos devuelve un ISet<long> con el conjunto de factores primos que conforman este número original. Dejando de lado la matemática, sabemos que este proceso toma un rato en ejecutarse y queremos que nuestro programa lo trate de forma asíncrona. ¿Cómo se haría este trabajo de la forma tradicional?
Básicamente deberíamos definir un método que sirva de callback. El callback (también llamado continuación) es un método que el thread que trabaja en la tarea llama cuando termina para avisar que su trabajo terminó. De esta forma, podemos preparar nuestra tarea, enviarla a ejecutar, hacer otras cosas en el intermedio y ejecutar código extra cuando la tarea termina, como por ejemplo, trabajar con los resultados.

(Ejemplo del código en Gist.GitHub: Async without async)
Esta aproximación tiene un problema muy claro: la complejidad. Estamos de acuerdo con que el código de FactorNumber debería estar separado en su propio método, pero la continuación de la llamada a FactorNumber y el resto de esa lógica son parte de una misma operación. El hecho de que estén separados en el código no es más que una obligación que debemos cumplir por las restricciones del framework para la instanciación de threads.
Las palabras clave async y await resuelven este problema.
Aquí podemos notar que la estructura del código ha cambiado un poco para dar soporte a esta característica. Por un lado, tuvimos que aislar el código que interactuará con métodos asíncronos, ya que los mismos deben devolver un tipo Task. Esto es porque devuelven un identificador de la tarea que está corriendo en background. En nuestro caso en particular, este será StartWork(), pero no estamos haciendo uso de su Task.
StartWork, siendo asíncrono, se ejecutará a la vez del resto del código, ya que no será bloqueante. Por tanto, el próximo Console.WriteLine se ejecutará, muy seguramente, al mismo tiempo que el procesamiento de StartWork ocurre. Dicho procesamiento hace una llamada bloqueante a FactorNumber, es decir, espera a que FactorNumber termine (lo cual nos permitió convertir la llamada en síncrona) y una vez que tenemos el resultado, se escribirá en consola. No era realmente necesario convertir esta llamada en síncrona de esa forma, una simple llamada a FactorNumber hubiera sido suficiente, pero de esta forma demostré que si bien el sistema espera por su respuesta suspendiendo el thread actual, sigue siendo asíncrono internamente. Eso significa que está ejecutando toda la tarea de callback que vimos antes de forma interna, y ahora nuestro código se lee fácilmente de arriba a abajo.
Confieso que debo trabajar un poco más en esto para no ensuciar tanto el código, pero por ahora parecería que el uso de las keywords exige modificar los valores de retorno y por tanto las llamadas a esos métodos deben ejecutarse de forma distinta. Eso no me agrada, porque inclina un poco la complejidad innecesaria para usar esto, pero sigue siendo una ventaja sobre la solución original.
Pasos para crear una buena estrategia
Ya que están pasando Battleship en el cine, me pareció muy apropiada la publicación de este link. De parte de MicroSiervos, Nick Berry de DataGenetics nos habla de un análisis estadístico para la estrategia de la Batalla Naval.
Atacando el problema primero en la forma más simple posible y luego mejorándola, él nos muestra cómo fácilmente se puede construir una inteligencia que, sin ser muy compleja, se acerca mucho a ser un buen competidos en un juego como este, y los números están ahí para probarlo.
Cabe destacar que esto parece ser algo muy común para la gente de DataGenetics y su blog, el cual comencé a seguir. Tienen muchos buenos análisis de varias cosas totalmente distintas. De hecho, hace poco me crucé con un post llamado Counterintuitive Conundrums, que básicamente son problemas con soluciones inesperadas (y nuevamente, los números están ahí para probarlo).
Soy un zorrinito analítico.
Javascript BDD
Jasmine no es el primer ni el último testing framework que existe, pero aquellos que vengan desde RSpec lo encontrarán muy parecido y fácil de usar. La misma página de Jasmine muestra una buena cantidad de ejemplos de cómo puede ser usado y de sus capacidades. Cabe destacar que no depende de ningún otro framework, pero juega bien con ellos (lo cual es interesante para realizar pruebas de UI aprovechando capacidades que jQuery, Dojo o Mootools nos puedan dar), y ni siquiera necesita del DOM estando cargado, lo que significa que de tener una aplicación compleja en JavaScript, podemos realizar pruebas unitarias respecto de nuestras propias librerías, independientemente de que se encuentren cargadas en un entorno o no.
Soy un zorrinito testeado.
Libros obligatorios de lectura sobre UX
Otra de las joyitas rescatadas de los foros de User Experience, es la pregunta sobre libros de lectura obligatoria de user experience y diseño de interfaces. El listado es más que completo y sorprendentemente vasto.
Este es el listado de libros, según la cantidad de votos de la respuesta que lo contiene (asumo que podríamos decir, más aceptado a menos aceptado):
Más que suficiente para entrenarnos en este aspecto.
Soy un zorrinito lector.
El por qué de practicar y ejercicios para hacerlo
Algún tiempo atrás JM nos había compartido un artículo sobre TDD Katas que básicamente explicaba qué son y por qué valen la pena. En dicho artículo Kata - The only way to learn TDD Peter Provost nos explica la mecánica básica tras la enseñanza de los Katas, una forma fácil de poner a práctica nuestros conocimientos teóricos.
No mucho tiempo después encontré el sitio de CodeKata, aplicado a una serie de metodologías más general, a aprender a desarrollar en distintas disciplinas o ámbitos. El artículo de Code Kata - Background tiene una buena introducción a lo que puede encontrarse en el resto del sitio.
¡A poner esas habilidades a practicar!
¿Y ahora qué hago?
Uno de los posts que causaron revuelo en las preguntas de Server Fault fue My server’s been hacked EMERGENCY (Hackearon mi server, EMERGENCIA), un post cuya respuesta fue totalmente inesperada para muchos y muy útil y planeada para situaciones tan sorpresa.
Me pareció tan útil que además de sólo linkear la pregunta y su respuesta, quise traducir la elongada explicación que Robert Moir, bajo el usuario de DJ Pon3 nos ha brindado. Esta traducción se basa en su respuesta pública, sin permiso explícito.
él nos explica cuáles son las medidas a tomar en un caso drástico como este, y muchas formas de reducir el riesgo de esto ocurriendo en el futuro. La explicación es larga pero muy clara y muy explícita sobre cada aspecto involucrado en la seguridad de un sistema.
A continuación, su respuesta:
Es difícil dar un consejo específico desde lo que has posteado aquí, pero tengo algunos consejos genéricos basados en un post que escribí mucho tiempo atrás cuando todavía podía molestarme en bloggear.
Primero que nada, no hay “arreglos rápidos” más que recuperar tu sistema de una copia de seguridad tomada anteriormente a la intrusión, y esto tiene al menos dos problemas.
Esta pregunta sigue siendo hecha repetidamente por las víctimas de los hackers que entran en su servidor web. Las respuestas cambian raramente, pero la gente sigue haciendo la misma pregunta. No estoy seguro de por qué. Quizá a la gente no le gustan las respuestas que han visto buscando por ayuda, o no pueden encontrar a alguien que confíen que les de consejo. O quizá la gente lee una respuesta a esta pregunta y se concentra demasiado en el 5% de por qué su caso es especial y diferente a las respuestas que pueden encontrar online y se pierden el 95% de las preguntas y respuestas en donde su caso es suficientemente cercano a ser el mismo al que leyeron online.
Eso me trae a la primera pepita de información. Realmente aprecio que eres un copo de nieve único muy especial. Aprecio que tu sitio también lo sea, ya que es un reflejo de tí y tu negocio, o en última instancia, tu trabajo duro en nombre de un empleador. Pero para alguien desde afuera mirando hacia adentro, ya sea una persona de seguridad de computadoras mirando al problema para tratar de ayudarte o incluso para el mismo atacante, es muy probable que tu problema sea al menos 95% idéntico a cualquier otro caso que ellos hayan visto.
No te tomes el ataque de forma personal, y no tomes las recomendaciones que siguen aquí y que te da otra gente de forma personal. Si estás leyendo esto inmediatamente luego de convertirte en la víctima de un hack en un website, entonces realmente lo siento mucho, y espero que puedas encontrar algo útil aquí, pero este no es el momento para dejar que tu ego se interponga en el camino de lo que tienes que hacer.
No entres en pánico. Absolutamente no actúes apurado, y absolutamente no intentes actuar como si las cosas nunca hubieran ocurrido y no tuvieras que hacer nada.
Primero: comprender que el desastre ya ocurrió. Este no es el momento para la negación; es el momento para aceptar lo que pasó, para ser realista al respecto, y para tomar pasos para controlar las consecuencias del impacto.
Algunos de estos pasos van a doler, y (a menos que tu website tenga una copia de mis datos), realmente no me importa si ignoras todos o algunos de estos pasos, pero hacerlos hará las cosas mejores al final. La medicina puede saber horrible pero a veces hay que quitarle importancia a eso si queremos que la cura funcione.
Detén el problema de volverse peor de lo que ya es:
¿Todavía dudas si tomar este último paso? Lo entiendo, de verdad. Pero míralo de esta manera:
En algunos lugares podrías tener un requerimiento legal de informar a las autoridades y/o las víctimas de este tipo de brecha de privacidad. Por mucho que tus clientes se molesten teniéndote contándoles sobre un problema, estarían mucho más enojados si no les contaras, y sólo se enterarían por cuenta propia cuando alguien les cobre U$S 8.000 dólares en bienes usando los datos de tajeta de crédito que obtuvieron de tu sitio.
¿Recuerdas lo que dije antes? Lo malo ya ocurrió. La única pregunta ahora es qué tan bien vas a lidiar con ello.
En situaciones como esta el problema es que ya no tienes control de ese sistema. Ya no es tu computadora.
La única forma de estar seguro de que tienes control del sistema es reconstruir el sistema. Si bien hay mucho valor en encontrar y arreglar el exploit usado para entrar en el sistema, no puedes estar seguro sobre qué más ha ocurrido en el sistema una vez que los intrusos tomaron control (de hecho, se sabe de hackers que reclutan sistemas a una botnet para solucionar los exploits que ellos mismos usaron, para salvaguardar “su” computadora de otros hackers, y también instalar sus rootkits).
Nadie quiere estar offline más de lo que tienen que estarlo. Eso está claro. Si este website es un mecanismo de generación de ganancias, entonces la presión para traerlo de vuelta online rápidamente va a ser intensa. Incluso si solo la cosa en juego es la reputación tuya / de tu compañía, esto va a generar todavía más presión para poner las cosas funcionando de vuelta rápidamente.
Sin embargo, no cedas a la tentación de volver online demasiado rápido. En lugar de eso, muévete tan rápido como puedas para comprender qué causó el problema y para solucionarlo antes de volver online, de de lo contrario muy sgeuramente caerás víctima de una intrusión nuevamente, y recuerda, “ser hackeado una vez puede ser clasificado como mala fortuna; ser hackeado de vuelta inmediatamente luego se ve como descuido” (con mis disculpas a Oscar Wilde).
La primer cosa que debes comprender es que la seguridad es un proceso que debes aplicar por todo el ciclo de vida de diseño, instalación y mantenimiento en un sistema que tiene acceso a internet, no algo que puedes pegar como un par de capas sobre tu código luego como pintura barata. Para estar seguro apropiadamente, un servicio y una aplicación deben estar diseñados desde el comienzo con esto en mente como uno de los objetivos principales del proyecto. Me doy cuenta que es aburrido y que ya has escuchado todo esto antes, y que “no te das cuenta de la presión, hombre” de tener tu servicio web 2.0 beta (beta) en estado beta en la web, pero el hecho es que esto se sigue repitiendo porque fue verdad la primera vez que fue dicho y todavía no se ha convertido en mentira.
No puedes eliminar el riesgo. No deberías siquiera tratar de hacerlo. Lo que deberías hacer, sin embargo, es comprender cuáles riesgos de seguridad son importantes para tí, y comprender cómo manejar y reducir tanto el impacto del riesgo y la probabilidad de que el riesgo ocurra.
Por ejemplo:
Si decides que el “riesgo” de que el piso bajo de tu casa se inunde es alto, pero no lo suficientemente alto como para mudarte por las dudas, deberías al menos mover las reliquias familiares irremplazables al piso superior. ¿Verdad?
Probablemente no dejé cabo suelo entre las cosas que otros consideran importantes, pero los pasos de arriba deberían al menos ayudarte a comenzar a ordenar las cosas si tienes la mala suerte de convertirte una víctima de los hackers.
Sobre todo: no entres en pánico. Piensa antes de actuar. Actúa firmemente una vez que hayas tomado una decisión, y deja un comentario debajo si tienes algo que agregar a mi listado de pasos.
Soy un zorrinito hackeado (gracias Julián!)
Desmintiendo si las URLs acortadas afectan o no la confianza del usuario
Hoy voy a dejar un caso de una pregunta abierta, nuevamente, originada en los foros de User Experience. La pregunta es: _ ¿Los usuarios confían en URLs acortadas?_
Siempre se supo, y es un concepto fundamenta del SEO, que las URLs deben ser lo suficientemente amigables como para significar algo que sea relevante al contenido de ese recurso. Por otro lado, la teoría debajo de REST y la web semántica nos indican que las URLs (o URIs) deberían ser identificadores únicos de un recurso en particular, de forma que, de alguna manera, su identificador tendría cierta relación con su contenido.
Sin embargo, y aún así, parece no haber estudios definitivos realizados sobre lo que los usuarios en general opinan. Nosotros hemos experimentado confianza o desconfianza de estas URLs dependiendo de quién vienen, o en dónde las encontramos. Básicamente, dependería del contexto.
Sin embargo, ninguna de las respuestas tiene algún estudio que demuestre la fiabilidad de su fuente, por lo que yo ya comencé una pregunta que pide por ellos, pero veremos qué ocurre. Esta pregunta sigue abierta e invito a los lectores a aportar cualquier información que tengan al respecto.
Soy un zorrinito acortado.
Comenzando a explorar lo que la beta nos ofrece.
Comencé como un proceso de autocapacitación mi investigación personal de las características que Visual Studio 11, todavía en Beta, nos ofrece. Pretendo documentar mi experiencia personal porque si bien no va a ser una buena indicación de cómo es el producto, puede que detecte muchos pequeños problemitas o cosas que estarían buenos tener en cuenta, al menos prepararse para ellos. Conociendo mi suerte, estoy seguro de que algo voy a romper.
 { :align-left }
{ :align-left }
Lo primero que tengo que comentar es la instalación. La interfaz está mucho más refinada, pero más allá de eso, es un poco más oscura en el sentido en que no tenemos mucha información sobre qué está pasando. No he tenido problemas con la instalación, pero imagino que debe ser más complicado de hacer troubleshooting si ocurriera algún error. Por último, la instalación toma su buen par de horas, quizá extendiéndose hasta cuatro o cinco. Si tiene que bajar los updates de internet, es lo suficientemente inteligente como para hacerlo en paralelo mientras otra cosa se instala, así que tener una conexión pobre no debería ser un problema a menos que fuera muy acotada.
Mi instalación terminó sin problemas excepcionales. Una característica rara que me ocurrió en una de las dos máquinas que la instalé (solo en una) es sobre un paquete que debe continuar la instalación. Como varias de las instalaciones de VS, a veces es requerido un reinicio hasta que se pueda continuar la instalación. La forma en la que el instalador se asegura continuar luego es poniendo una entrada en el registro para volver a correr la próxima vez. Resulta que en mi caso, ese ejecutable se inició pero nunca se quitó del registro. Nunca supe si ejecutó correctamente o no porque ese ejecutable en particular parece no tener interfaz. Tras cada reinicio que yo hacía, el ejecutable volvía a pedirme permiso (ya que es un archivo bajado de internet).
Ese se encuentra aquí, algo que futuros visitantes pueden encontrar muy útil para diagonsticar problemas:
"C:\ProgramData\Package Cache\{a3c0442e-f8f7-4089-ac77-1e0c50901f63}\vs_ultimate.exe" /burn.log.append "C:\Users\_<User>_\AppData\Local\Temp\dd_vs_ultimate_<timestamp>.log" /uninstall /quiet -burn.related.upgrade
Por el comando que ejecuta y deja en el archivo de log, parecería ser un servicio de updates y de rollout de nuevas funcionalidades agregadas. Si estoy en lo correcto, no deberían preocuparse ya que VS tiene su propia plataforma de updates. Lo que yo hice es simplemente quitar eso de mi inicio. No he visto complicaciones hasta ahora.
Lo primero que voy a probar es hacer algo parecido a mis tareas diarias.
Mi primer sorpresa es la elección de colores que tuvieron con el entorno. En general, todo grisáceo y de colores muy uniformes. Es fácil ver el texto pero no lo es tanto como el contraste que proponía el blanco sobre azul de la versión anterior. Es difícil distinguir las ventanas sobre el fondo, especialmente si no tienen contenido. Cada tanto los mensajes de diálogo pierden ese estilo y vuelven al estilo normal que tienen las ventanas de Windows, dejando ese feo sabor del cual todos se quejan de la suite Adobe, en donde el programa realmente desentona con el entorno en el que está corriendo.
Recordemos nuevamente que está pensado también para Windows 8, con lo que mi apreciación podría ser equivocada, pero no lo he probado aún. Esa es otra historia y probablemente otra serie de posts.
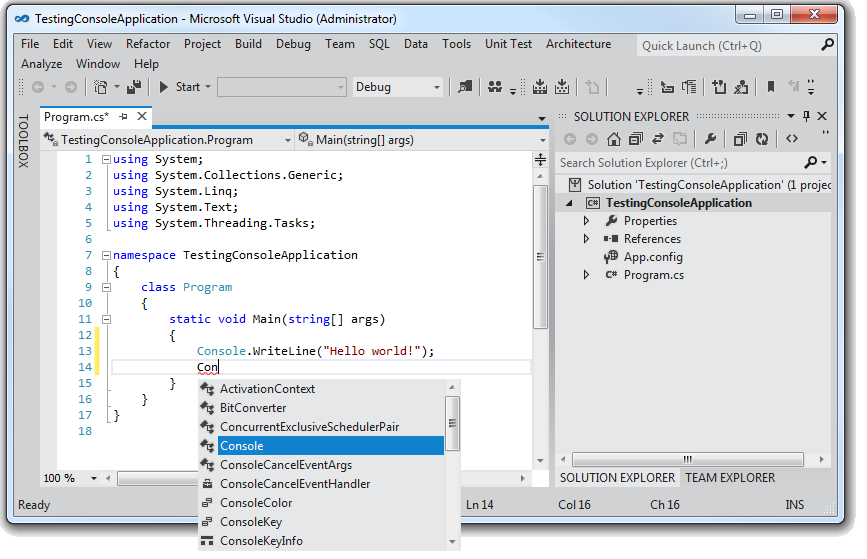
Como pueden ver en el screenshot que tomé, también optaron por eliminar los colores de los menúes contextuales, específicamente les muestro el de Intellisense, el cual me parece una pésima decisión. La habilidad de distinguir propiedades, métodos, clases, enumerados y campos por color a simple vista era una bendición. Las selecciones de arriba siguen siendo dropdowns anque parezcan desaparecidos, y los íconos más el gris claro/gris oscuro/negro de toda la sección derecha lo hace difícil de acostumbrarse. Creo entender la intención: esta pantalla nos concentra, sin duda, en el código, y eso definitivamente debería ocurrir.
El entorno completo parecer ser más rápido y responsivo, sospecho que estará utilizando la misma tecnología de async que el nuevo framework ofrece. ¿Recuerdan el cuadro de diálogo de Add Reference, que fácilmente detenía todo unos minutos hasta recuperar el listado de assemblies? Sigue tardando, pero ya no significa un problema, el entorno sigue respondiendo como si nada estuviera ocurriendo de fondo.
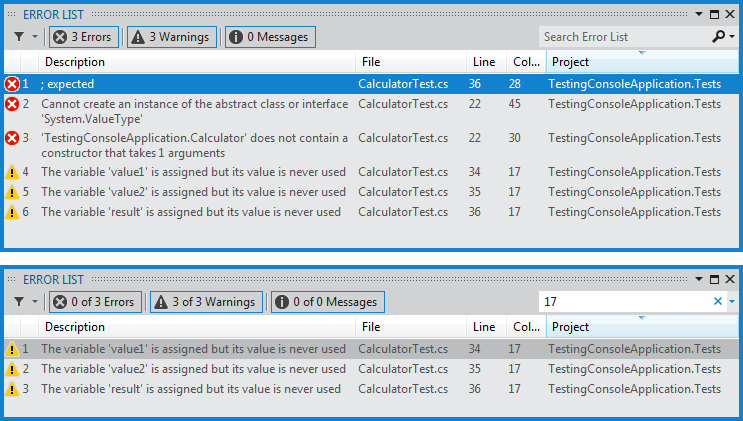
Una muy buena adición que encontré es la capacidad de filtrar errores desde el listado de errores de compilación. Esto nos permite dar un paso adelante, cuando ya estamos acostumbrados a determinados errores causando otros, pudiendo concentrar nuestro esfuerzo en solucionar esos primero. Como pueden ver además, el filtro funciona para cualquier campo, lo cual resulta totalmente natural.
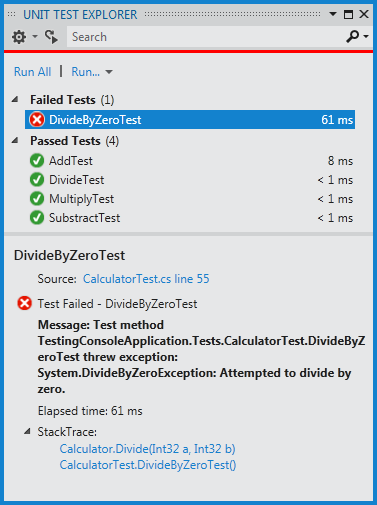
Desafortunadamente, parece que esta característica no se comporta de forma consistente en todas la ventanas. Otra que me interesa que vean es la ventana Unit Test Explorer, otra que estaremos viendo muy seguido, más todavía si trabajamos con TDD. En este caso la búsqueda sólo funciona con el nombre de las pruebas y uno debe presionar enter para aceptar la búsqueda, cuando en la anterior ya con sólo filtrar podíamos ver nuestro filtro aplicarse.
Esta ventana, sin embargo, tuvo un rediseño visual algo importante y me agrada el cambio. En las versiones anteriores los detalles de una prueba se encontraban separados de la prueba en sí, esto hará mucho más fácil poder ver qué pasa con cada una de las pruebas, y asumo que su output también aparecerá aquí.
Parece que otra característica que tampoco nos dejará muy contentos es algo que estaba siendo muy aclamado. Cualquiera que reconozca la frase “Expression cannot contain lambda expressions” sabe de qué estoy hablando. Así es, esa frase sigue presente y nos sigue molestando aún en esta nueva versión. Por favor, espero que la versión final del IDE agregue esto porque es una funcionalidad que puede salvar horas y horas de desarrollo.
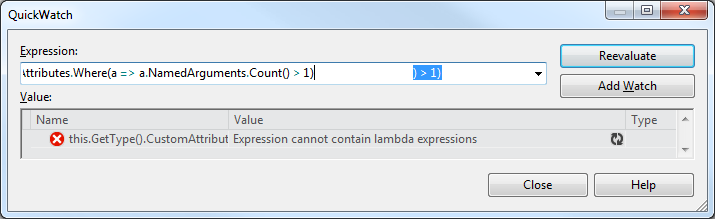
Desafortunadamente alguien ha decidido que agregar coloreado al texto que tipeamos ahí fue más importante, y terminamos con una versión algo buggeada de texto formateado (como pueden ver en la imagen anterior, ambas decepciones juntas). No es realmente nada tan terrible como algo que no funcione, pero muchos queremos poder efectuar un .Where() para no tener que pasar por más de 200 elementos en un enumerable.
En otra de mis pruebas descubrí que existe algo llamado Parallel Watch, que básicamente es una ventana de watch que nos permite ver valores de una misma variable a lo largo de distintos threads. Supongo que esto puede volverse confuso ya que distintas intancias de una misma variable son en realidad distintas variables e instancias no-thread safe son en realidad la misma variable. Eso o yo me estoy perdiendo algo del concepto de trabajar en paralelo. (Si algún lector tiene algo que aportar, es bienvenido.)
Dispuse la siguiente prueba para verificar su funcionalidad, y como sorpresa extra, encontré que puedo editar el código mientras está ejecutando, algo que anteriormente sólo ocurría en determinados casos. Me trajo un poco de satisfacción (aunque no tanto como me habría dado poder usar lamdbas en el quick watch.)
Desafortunadamente mi prueba no resultó muy exitosa, ya que al elegir una ventana de watch para poder ver, el siguiente mensaje se hace presente (les dije que algo iba a romper):
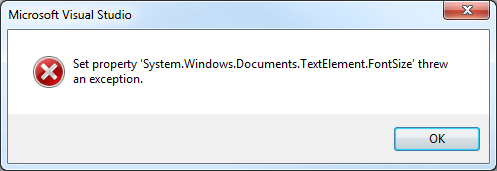
Creo que de todos momentos puedo estar en el camino equivocado, ya que en la ventana de Parallel Tasks nada aparecía. Seguramente tenga algo que ver con la nueva característica de async tasks de .NET 4.5.
Es un muy buen punto de partida para retomar mi investigación, ya que mi tiempo se acabó por hoy.
Comparando funcionalidades desde su pantalla
De parte de Cesar D’Onofrio (¡gracias!) me llega este útil link llamado, simplemente, Mobile Patterns. El sitio es, sin mucho más, una galería de interfaces mobile para distintas categorías de pantalla. En este caso, se trata de pantallas de iPhone, pero los conceptos van más allá del teléfono en el cual se vean. La distribución de la información y la utilización de imágenes no tiene realmente que ver con una marca de dispositivos.
Esta recopilación en particular fue puesta junta por Mari Sheilbley, la diseñadora líder de Foursquare, quien a la vez postea varios diseños interesantes en su blog personal a modo de portfolio.
Soy un zorrinito diseñado.
Buenas prácticas para formularios web
Otra de las preguntas de los foros de User Experience, bajo el título de Have I missed anything from my list of web form best practices?, consiguió una muy buena recopilación de consejos de buenas práctica sobre interfaces de formularios y UI / UX. Si van a mirarlo, miren todas las respuestas, ya que la pregunta principal no ha sido actualizada para recopilar completamente todo lo que han sugerido.
Cabe mencionar que muchas de estas respuestas corresponden a sugerencias e incluso a patrones explicados en el libro Web Application Design Patterns, de Pawan Vora, el cual es una buena referencia para buenas prácticas generales sobre la web. Sin duda habrá mejores referencias, pero es de las que he leído hasta el momento. Los invito a compartir libros o referencias recopilatorias de buenas prácticas.
Soy un zorrinito de buenas prácticas.
UPDATE: Lisandro nos dejó en los comentarios un link sobre la forma correcta de alinear labels, y otro sobre las ventajas de campos de texto unificados. ¡Gracias!
¡Chuck Norris al rescate!
Hace poco me crucé con un proyecto que utilizaba RoundhousE y mi curiosidad me llevó a ver qué era. Me encontré con que es un sistema de migraciones de bases de datos muy conocido para .NET, particularmente para SQL Server, pero también soporta MySQL, Oracle, PostgreSQL, e incluso SQLite.
Cabe aclarar que cuando menciono el concepto de migración, no me refiero a la actividad de mover datos de un esquema a otro, sino al hecho de convertir un esquema a otro (que, en el fondo, no es tan distinto). Este concepto de migración y versionamiento de bases de datos permite tener controlados los cambios que deben aplicarse al momento de cambiar la versión de una aplicación, y su capacidad de aplicar o revertir cambios hace que ya no deba recordarse de forma mental en qué estado nuestra base y cómo llevarla al estado nuevo.
RoundhousE puede encontrarse en su repositorio de GitHub (bajo el usuario chucknorris, ¡ja!), o en su sitio http://projectroundhouse.org, que ahora lleva a Google Code.
Soy un zorrinito migrado.
Una imagen tiene menos de mil copos de cereal
De parte de Design.org me llega una ingeniosa representación infográfica de Ed Lea, quién plasmó diferentes conceptos de diseño e interfaz en ejemplos visuales con un plato de cereal.
El post pueden verlo en The Difference Between UX and UI: Subtleties Explained in Cereal.
Me gustaría incluso jugar a extender la analogía (y necesito ayuda de ustedes, lectores, para eso). Estas son algunas ideas que se me ocurrieron:
¿Qué más se les ocurre?
Soy un zorrinito cerealero.