Archive: 2009
45 posts published in 2009

A black and white figure's thought-hive
45 posts published in 2009
Suelo decir muchas tonterías a modo de chiste, pero de tanto en tanto, alguna de ellas tiene un poco de verdad. Hoy, hablando de un sistema del que estoy encargado (entre otras personas) de mantener, pensé que estaba muy difícil su actualización, y lo llamé un Sistema Jenga. ¿Qué es un sistema Jenga? Es un sistema para el cual agregar una pieza hace que peligre toda la estructura de su programación.

Aquí participan varios conceptos que alguna vez he mencionado. Uno de ellos es, por supuesto, la arquitectura o la estructura con la cual se ha programado, diseñado y modelado el sistema en cuestión. Es obvio que una buena arquitectura, o una pensada en torno a futuros cambios, pueda ser lo suficientemente flexible como para aceptar futuros nuevos requerimientos sin necesidad de rediseños mayores o cambios drásticos en la programación anterior. Pero ese no es el concepto que más me interesa discutir hoy.
Otro de los conceptos es el hecho de cuál es el propósito de una pieza de software. Lo considero un punto incluso filosófico, porque está claro que no hay un sistema multipropósito, que realice todas las funciones que podamos llegar a necesitar, y creo que no debería haberlo tampoco, porque sería infactible que dicho sistema se adapte a todas las situaciones particulares que puedan surgir. Por tanto, el riesgo que tal hipotético sistema introduciría en nuestros procesos, sería catastrófico. No haría falta mencionar tampoco, que la programación/diseño/análisis de ese sistema se aproximaría a lo altamente infactible. Muchos sistemas operativos ya proveen de estas posibilidades gracias a la integración de muchas pequeñas herramientas, pero no es técnicamente parte del mismo sistema, a pesar de que pueden llegar a interactuar de forma muy íntima.
Entonces, a medida que pasa el tiempo, es muy factible que los requerimientos para un sistema se vayan modificando. Muchas veces los cambios son pequeños, pueden ser cuestiones de usabilidad o cuestiones de performance. Incluso puede que haya una modificación grande en el sistema, agregando nuevas funcionalidades y hasta quitando funcionalidades obsoletas, pero el objetivo o el propósito del sistema se mantiene, hace lo que siempre debió hacer.
** ¿Qué pasa, entonces, cuando cambia el enfoque de negocios y los requerimientos del sistema pasan a tener un propósito distinto del original?**
Yo creo (aunque es mi opinión personal) que en ese caso el sistema se vuelve obsoleto, y pierde su razón de ser. Es entonces en donde el mantenimiento de esos sistemas para acomodarse a los nuevos requerimientos puede ser algo dramático, porque se está intentando usar algo que ni siquiera estaba pensado de la forma que se necesita para algo que ni siquiera estaba pensado que se iba a necesitar. Casos tan drásticos son raros, pero son factibles de ocurrir. Y creánme, ocurren.
 { :align-right}
{ :align-right}
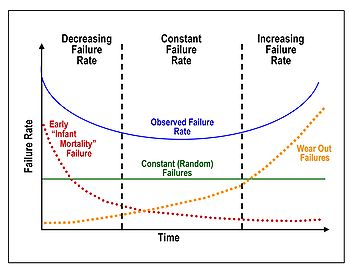
Esto no es nada nuevo tampoco. Se sabe, y es algo conocido como “la curva de la tina de baño” (o su nombre en inglés “Bathtub curve”) que el ciclo de vida de un sofware, o la utilidad que el mismo proporciona a sus propósitos es poco al principio, hasta que los usuarios logran sacar el máximo provecho de los sistemas, hasta que los demás sistemas lograron integrarse de forma correcta al mismo y hasta que los bugs iniciales hayan sido corregidos. En la etapa media es el ápice de la utilización de esos sistemas, pero pasado el tiempo, es cuando el sistema ya deja de satisfacer las necesidades del usuario.
Aquí surge la discusión de qué sucede con la curva en el final. Para productos comunes (por ejemplo, elementos mecánicos) el desgaste producido comienza a introducir nuevas fallas que de a poco vuelven al producto inusable. En el software, es fácil reacomodar la lógica del mismo y entonces, adaptándose a las nuevas necesidades, cabe la posibilidad de que se mantenga en su estado de mejor uso. Así, la curva finalizaría con una forma de sierra, en donde se observarían pequeños picos (dado que al usuario le deja de resultar útil el sistema) y tras dicho re-acomodamiento, una planicie.
Sin embargo, la manutención de un producto a través de la eternidad no es algo factible, y quizá no es deseable tampoco. Aquí es en donde la otra opinión se asoma al respecto, diciendo que la vida de un software también se desgasta proporcionalmente al tiempo que estuvo activo, y, personalmente, creo que tiene sentido. Las necesidades a través del tiempo suelen cambiar muy drásticamente y, aunque una suma siempre haya sido una suma, las cosas tienden a simplificarse para el usuario y cuando un click antes hacía una suma, ahora debe realizar una estimación a futuro.
Y finalmente, otra cosa que quería mencionar al respecto, es la terrible necesidad del backward compatibility. Esto significa que a medida que vamos mejorando y agregando funcionalidades a nuestro sistema, necesitamos algunas veces tener compatibilidad con las versiones viejas de nuestro sistema. A veces es fácil, porque nuestro sistema puede ser una web application que no requiera de muchas entradas, y por tanto podemos cambiarlo todo sin necesidad de tener esa precaución. ¿Qué pasa si en cambio Microsoft, al implementar su nuevo formato de archivos de Office 2007 hubiera hecho inútiles los archivos de Office 2003 hacia atrás? ¿Qué pasa si en cambio cuando decidieron implementar IPv6 no hubieran tenido en cuenta que somos millones los que estamos actualmente usando IPv4 y que no podemos (o queremos) comprar nuevas placas de red en este momento?
Por eso, siempre es una cuestión a considerar, no hay ni blancos ni negros, pero siempre que un sistema debe mantener compatibilidad con sus versiones anteriores, se agrega complejidad, y de alguna forma es un requerimiento extra que nos impide avanzar con las modificaciones que quisiéramos hacer para avanzar con las nuevas funcionalidades del sistema.
Es entonces, en conclusión, en donde el mantenimiento de un sistema se vuelve algo tan pesado que quizá sería mucho más provechoso realizarlo de cero con las nuevas necesidades, y en donde la modificación del mismo lo hace peligrar cada vez más en su integridad, algo que a mí me gusta llamar Sistemas Jenga.
Soy un zorrinito jenga.
Hace no mucho hablamos un poco sobre la importancia y los beneficios del cloud computing, o la computación en la nube, como muchos quieren traducir el término. Volviendo sobre la idea, es el concepto de tener sistemas distribuidos para los cuales muchas computadoras físicas a lo largo y a lo ancho de internet están colaborando para un fin común. Puede que estas computadoras sean computadoras personales, o puede que sean servidores dispuestos a ese fin en algún lugar fuera de nuestro alcance.
Independientemente de eso, deberíamos saber que esto no es algo nuevo y que ya existen muchas plataformas y servicios disponibles gracias a esto, seguramente muchos de los cuales conocemos a través de grandes empresas como Google y Microsoft (no pensaron que Google Docs estaba en un solo servidor, o que las descargas de Microsoft estaban todas en el mismo lugar, verdad?). Pero en realidad existen muchos servicios variados de muchas empresas, algunos disponibles al público y otros no.
Para guiarnos en todo eso es que viene el link del día de hoy, llamado Cloud Computing Ecosystem, un “mapa” que nos muestra qué distintos servicios y para qué distintos fines están disponibles desde qué empresas y qué disponibilidad tienen al público. El mapa está dividido en tres partes verticales y tres horizontales. De las verticales, tenemos por un lado a los servicios disponibles públicamente, a los servicios pagos, y a servicios privados. De las horizontales, tenemos los tipos de servicios divididos según su uso: aplicaciones (ya pre-armadas), plataformas (para desarrollo de aplicaciones), o servicios de infraestructura.
Por último, cabe preguntarse por qué alguien armaría un mapa así (más allá de aparecer como nominado al link del día). La respuesta es que la empresa que lo mantiene, llamada Appirio, es una empresa que brinda soluciones informáticas e integración de sistemas utilizando una gran variedad de servicios en la nube de los cuales ellos dicen ser partners. De esta forma, podemos generar soluciones de negocios enteramente tercerizados en internet, en donde nuestra información estará disponible desde cualquier lado y (supuestamente) segura y accesible.
Soy un zorrinito nublado.
Si mal no recuerdo creo que fue Nano quién me compartió por Google Reader este artículo de Kabytes, en donde hablan de una aplicación web llamada WPA Cracker, una aplicación que tomando un archivo pcap de capturas de un wifi WPA, puede compararlo contra una enorme cantidad de palabras y combinaciones (gracias al cloud computing) y devolvernos el password en un pequeño tiempo.
El uso de esta aplicación es paga, no realmente mucho si es que tiene algún beneficio para nosotros la utilización de esa red, pero independientemente de eso, es una buena aproximación a la obtención de claves: no tiene por qué hacer todo el trabajo una sola máquina durante semanas, cuando varias máquinas alrededor del mundo pueden hacerlo en cuestión de horas o minutos.
Fuera de eso, la aplicación es interesante, también permite el crackeo por diccionario de archivos ZIP (sólo porque el público lo pidió), nuevamente también contra un diccionario enorme de palabras en inglés y en alemán.
Según cuenta el autor, es un esfuerzo mucho más grande pero mejor para resultar de esta forma porque utilizar rainbow tables (como las que tienen para bajar en Curch of Wifi) es un poco ineficiente, dado que para eso se necesita crear una serie de rainbow tables para cada ESSID de la red, con lo cual se vuelve impracticable la idea original del rainbow table: tener una solución pre-armada, por pesada que fuera.
El precio que se le pone al servicio es de 17 dólares si es que queremos utilizar el diccionario básico (136 millones de palabras) en modo half-cluster (es decir, la mitad de las máquinas disponibles trabajan), o 35 si queremos utilizar el clúster completo. Además, también se puede hacer una corrida contra un diccionario extendido (que no contiene al diccionario básico) con 284 millones de palabras. Realmente bastante como para que se haga en unos 20 minutos, verdad?
Cabe decir por último que este es otro de los trabajos de Moxie Marlinspike, un hacker que siempre interesado en la seguridad (y en la navegación [marina, no por internet], pero eso es otra cosa). Puede verse mucho más al respecto en su website, más personal que website, y más elegante que completo.
Soy un zorrinito cracker.
Es bien conocido que la virtualización es una herramienta muy poderosa que amplía vastamente nuestras capacidades de prueba y simulación sobre sistemas para los cuales no disponemos el hardware real – o el dinero equivalente. Hoy por hoy las máquinas virtuales pueden llegar a ser tan poderosas como máquinas reales (con obvias limitaciones) y satisfacer muy bien ciertas necesidades (hosting con administración remota, ambiente de pruebas, testing de stress, investigación, etc.).
El proceso de creación de una máquina virtual es igual (o a veces un poquito más complicado) que la configuración de una máquina real: instalar el sistema operativo, configurarlo acordemente, configurar la red, instalar los programas necesarios, configurarlos, dejar todo en un estado lo más performante posible y finalmente, algún retoque final que querramos, y sabemos que solo el sistema operativo ya puede tomar un buen par de horas que no quisiéramos tener que sacrificar.
Para eso la gente de VMWare Images y VirtualBox Images (via LuAuF) nos deja imágenes prearmadas para bajar, y por mi parte también encontré estas imágenes para Virtual PC (aunque expiran muy prontito). Podemos descargarlas a nuestro disco y una vez ahí, ya tenemos el sistema operativo pre-instalado y a veces con algunas aplicaciones (como es el caso de las de Virtual PC).
Soy un zorrinito virtual.
Hace ya algunos días que Google publicó sus Closure Tools, una serie de herramientas para trabajar con JavaScript eficiente y lograr mejorar la performance, velocidad y tamaño del código. Entre ellos se encuentran Closure Compiler, una suerte de compilador para JavaScript, removiendo código innecesario, mejorando el código existente y minimizando lo que queda. También está la Closure Library, una librería JavaScript pero versión Google, y por último, los Closure Templates, una serie de soluciones “pre-hechas” para elementos reutilizables de HTML y UI.
Ahora, todo esto llama mi atención desde un artículo que encontré llamado Google Closure: How not to write JavaScript, que al principio parecía ser una crítica vacía de estas herramientas, pero luego se llena de fundamentos y (aquí es lo interesante) muchos datos que la gente de Google saltó al momento de crear estas herramientas. Esos datos son los que nos permitirían a nosotros aprender de esos errores y mejorar nuestras propias prácticas. Hay en todos lados para aprender.
Soy un zorrinito JavaScript.
Terminé hace poco de leer el libro A Tester’s Guide to .NET Programming, de Randal Root y Mary Romero Sweeney, un interesante libro aproximativo a .NET de unas 630 páginas.
Mi prejuicio de este libro, basándome en su título, era que iba a encontrarme con un libro que mostrara características propias de Visual Studio y de la plataforma .NET para llevar a cabo tareas particulares de testing. Seguramente, pensaba yo, me encontraría con nuevos conceptos de testing y nuevas características o nuevos usos de características existentes que me permitirían mejorar las metodologías que conozco para testing.
Desafortunadamente, no ha sido el caso. El libro, debo decir aún así, es realmente bueno, muy detallado y explicativo en sus puntos. La suposición que el libro hace es: tomemos como tester a aquél que quiere realizar testeos (más que nada de aceptación de usuario) sobre un determinado software, y basado en eso, el programa enseña programación en VB.NET y C# orientado a la utilidad de ciertas cosas.
A pesar de no haber cumplido con lo que esperaba, este libro es una joyita. Al poner un concepto tan poco desarrollado sobre testing, nos permite utilizar este libro como un manual para aprender a programar en ambos lenguajes, planteando al testing como un ejercicio práctico que desarrollaremos a lo largo de toda la lectura. Y esto mismo es interesante, porque no solo tiene una aplicación práctica muy directa – cosa que muchos estudiantes de un lenguaje siempre quieren ver prontamente – sino que es fácil de entender y de sobrellevar.
El libro comienza con conceptos algo vagos de la programación, solo mostrando que con determinadas líneas en determinado lugar podremos lograr cierto resultado. Avanzando más, de a poco nos introducen a las clases, métodos, conceptos de orientación a objetos y reutilización de código. No llega a niveles más avanzados como la creación de frameworks para generar testware más complejo, pero se para a un paso de eso, y lo mantiene simple. Esto nos permite seguir el libro sin necesidad de demasiada atención, en donde sabemos que la información no está condensada sino explicada de formas que son fáciles de comprender, llenos de ejemplos, llenos de ejercicios prácticos y todo eso nos genera el impulso de seguir avanzando.
Como tal, resumo, este libro no tenía lo que yo esperaba encontrar, pero ha sido un muy buen hallazgo aún así.
Soy un zorrinito .NET.
Freenet es el nombre de un proyecto (no del todo nuevo) que es tan ambicioso como para querer lograr una nueva internet, libre de restricciones y con pura anonimidad. La idea es que internet, en lugar de funcionar de forma servidor-cliente, funcione de una forma descentralizada, en donde nuestros contenidos pueden estar en cualquier lado, y donde cualquiera puede accederlos sin saber a dónde accede o cómo se está llegando ahí.
El proyecto de Freenet quiere entonces una distribución de la información totalmente libre, independientemente de las barreras legales que las distintas políticas apliquen, creando el concepto de una “internet” con una legislación independiente de la legislación que tengan los países.
No sabemos qué habrá ahí adentro, seguro que muchos lo están utilizando para lo más ilegal que se les ocurra, pero fuera de eso, el proyecto no deja de ser ambicioso y una idea muy interesante. Como toda gran idea, es un arma de doble filo.
Soy un zorrinito libre.
Para aquellos que usamos Google Chrome (Safari también aplica), seguro ya sabemos que tenemos una sección llamada Developer Tools en donde podemos trabajar con el código fuente de una página, los estilos CSS y demás. Pero si es que no le hemos prestado mucha atención (yo no lo había hecho), tenemos muchísimas herramientas detalladas para trabajar con los sitios y no estaría bueno desaprovecharlas. Para las últimas features, aclaro, hace falta la versión del Developing Channel de Google Chrome, o el nightly build de Safari. De todos modos, tarde o temprano serán parte de alguna versión estable.
Con lo primero que me crucé es con el blog de BogoJoker, uno de los desarolladores involucrados en este tema, en donde cuenta varias características amigables al usuario del visor de HTML, del visor de propiedades CSS, y cómo editarlos. También trabajaron un poco con el resaltador de sintaxis para esas secciones, y otros arreglos menores. De ahí él linkea al blog de WebKit en donde podemos encontrar información más detallada sobre varias de sus características y cómo usarlas: la interfaz, la consola, cómo editar HTML, cómo editar CSS, cómo usar el panel de Recursos, cómo debuggear Javascript, cómo hacer profiling de sitios (Chrome agrega snapshots de memoria), cómo jugar con las bases de datos de HTML5, y la búsqueda.
Sabemos que todo esto está en desarollo y todavía está lleno de bugs, pero eso no hace que sea terriblemente útil y que podamos sacarle provecho. Para más ayuda sobre cómo hacer ciertas cosas, check out the enclosed instruction book, o checkeen los resultados de Youtube.
Soy un zorrinito cromado.
Gracias a un artículo de TaranFX me enteré de algo que, si bien no es nada nuevo, es terriblemente útil para todo desarrollador de Java. Se trata de una aplicación que Sun distribuye llamada VisualVM, que, básicamente, es un manager de aplicaciones y profiler de datos, muy completo, muy amigable y muy fácil de usar. Solo tenemos que tener la máquina virtual de Java instalada y tras eso, podemos bajarnos esta aplicación y ponerla a funcionar, desde el sitio oficial.
También la podemos integrar con algunos entornos de desarrollo (vi por ahí mencionados a Eclipse y IntelliJ IDea), o podemos incluso agregarle plugins para mejorar sus capacidades. Algo sin duda utilísimo para el desarrollador / tester Java.
Soy un zorrinito de café.
Geo-API es un servicio (por ahora gratuito) que se encuentra en estado alpha de desarollo, que básicamente nos permite obtener información geolocalizada basándose en un punto de latitud y longitud y cosas de interés que puedan estar a su alrededor. Esto incluye negocios, lugares turísticos, atracciones, etc. Podemos entonces obtener información que puede ser muy útil para el usuario de alguna aplicación (o para nosotros mismos) solo desde el punto en donde esté parado este usuario. Algo totalmente valioso para aplicaciones móviles.
Como si fuera poco, el proyecto del SDK (no el fuente) se encuentra en Google Code, que incluye el código de varios demos y de un SDK para programar en iPhone. También hay algo de documentación allí sobre el uso que se le puede dar.
Por último, también tenemos varios demos online funcionando, en la sección Product & Demos del sitio oficial.
Soy un zorrinito geolocalizado.
Aquellos que trabajamos con C# sabemos que de a poco el lenguaje se está convirtiendo en algo que tiene otro punto de vista sobre la programación. No es tan estructurado como programación orientada a objetos, atributos, propiedades, métodos, sino que entran a aparecer algunas cosas más, conceptos de la programación funcional. ¿Qué es esto? ¿Cómo aplicarlo? Podemos dejarnos llevar por este artículo llamado Functional Programming for Everyday, que nos cuenta de qué forma podemos ir asimilándolo a nuestras tareas de programación diarias. Si eso no nos alcanza tenemos otras introducciones más simples en Functional Programming in C# (Part I: Is it worth your time? y Part II: High Order Functions). Pero si aún así se quieren quedar con un ejemplo más práctico, pueden ver el de Introduction to Functional Programming in C#.
Si en cambio estamos del otro lado, por ejemplo, del lado web, y sabemos que la interfaz es lo más importante, tenemos que aprender a usar ciertas cosas que le hagan la vida más fácil al usuario. Ahí es donde podemos, por el lado de los estilos, generar dinamismo pensando en CSS Orientado a Objetos (no realmente, pero el concepto es válido). Podríamos pensar en javascript para convertir algún formulario demasiado largo en algún wizard: Turn any webform into a wizard with jQuery, o usando varios tips para hacer el javascript más rápido: Improve your jQuery - Excellent 25 tips.
De estos está la internet llena, solo hay que buscar y ponerse a leer y a elegir qué será lo mejor.
Soy un zorrinito programador.
Gracias a DG quien me pasó el dato, resulta que ahora es noticia que Google quiere liberar un lenguaje llamado Go (como si otra cosa faltara). Este lenguaje, según dicen, quiere combinar lo mejor de C++, Python, e incluso ideas desde Pascal, Oberon, etc…
El sitio oficial contiene mucha información al respecto, y creo que toda la necesaria para comenzar a utilizarlo y probar qué tal. Prometen que será fácil, que será rápido y que será algo que nos librará de varios vicios que otros lenguajes tenían.
Habrá que averiguar.
Soy un zorrinito Google.
Este link sale de un artículo me encontré en Ars.Technica llamado Virtual Composer Makes Beautifull Music – and stirs controversy. Se trata de un agente de inteligencia artifical basado en el artículo de David Cope, Computer Models of Musical Creativity, pero yo sé que ustedes quieren más que simplemente leer artículos e imaginar así que para ustedes viene lo siguiente.
David Cope publicó también una página con el título de MP3 Files of David Cope Experiments in Musical Intelligence, donde se muestran mp3 creados por este agente bajo esos métodos, basándose en los estilos de distintos autores clásicos. Yo escuché algunos de Beethoven y, la verdad, si me aseguraran que son realmente de Beethoven, podría creérmelo. Y fuera o no creíble, son hermosos de todos modos.
Soy un zorrinito artificial.
Muchos de nosotros hemos querido comenzar a aprender algún lenguaje de programación, y de seguro lo primero que hemos visto en ese lenguaje es el famoso “Hola mundo”, que no es más que un simple programita que da como salida visible una cadena de texto “Hola Mundo”, o en su versión original, “Hello world”.
Alguno se lo han tomado de forma humorística/simpática y han decidido hacer competencias respecto de esos programas (qué recuerdos! Hasta mi entrada aparece ahí), pero hay quiénes se lo han tomado de forma más… académica? y han decidido hacer una compilación de programas Hello World para exponerlos como muestra de cada lenguaje. útil? Interesante? Ustedes deciden.
Sea como sea, me gustó mucho The Hello World Collection.
Soy un zorrinito saludador.
De casualidad me enteré de la existencia de un canal de Youtube llamado Google Tech Talks, en donde Google ha subido muchas conferencias sobre distintos temas. Según lo que ellas dicen: “Google TechTalks (Las conferencias técnicas de Google) están diseñadas para diseminar un amplio espectro de vistas sobre varios temas, incluyendo temas de actualidad, ciencia, medicina, ingeniería, negocios, humanidades, derecho, entretenimiento y las artes.”
Las charlas son todas extensas y detalladas, y supongo – he visto de ellas poco y nada – que algunas son mejores que otras. Estuve tentado de mencionar algunas categorías, pero la vasta extensión de temas tratados me lo hace imposible. Además, me siento interesado en todo, desde análisis económico hasta ingeniería reversa, desde autoayuda hasta ecología.
Como dato extra, voy a mencionar que llegué ahí por un video que encontré en Youtube, bajo la categoría de The Clean Code Talks, que para nosotros desarrolladores es altamente interesante, y parece que tienen conceptos bastantes radicales, ya que por ahí escuché mencionar que los Singletons son malas ideas (y tanta estima que yo les tenía!), pero es cuestión de ponerse a analizar todo lo que cuentan ahí.
Soy un zorrinito variado.
IETester es otra de esas herramientas que nos permite probar nuestras aplicaciones o páginas web en distintas versiones de Internet Explorer, esta vez yendo hasta la versión 5.5 (aunque creo que ni deberíamos preocuparnos en probar esa). Es una aplicación de escritorio para Windows que podemos instalar y así renderizar nuestras páginas favoritas para que sean rotas de distintas formas.
Sin embargo, visitando el sitio ya me encontré con otras cositas interesantes. Una de ellas es MyDebugBar, una barra de herramientas para Internet Explorer que le agrega muchas funcionalidades para el desarrollo y testeo de páginas web. Tristemente es shareware y pasados los 60 días debemos comprar una licencia.
Otras herramienta que la misma empresa dispone de forma gratuita es (aparte de IETester) Companion.JS, un plugin al estilo Firebug que le agrega muchas funcionalidades para manejo de javascript, debuggeo, evaluación, etc. para Internet Explorer, algo que a muchos nos venía faltando.
Soy un zorrinito wheeee!
Y de vuelta, otro sistemita que está portado a C# (lo lamento VBUsers, yo soy de la otra camada, aunque en su momento fui alguno de ustedes). En este caso, se trata de Git, el famoso sistema de control de versiones que estaba pensado para ser rápido, performante y light.
Ahora con Git# tenemos el código de Git portado a .NET, la idea es poder utilizarlo como parte de algún sistema, o de nuestro propio sistema de control de versiones. Quizá la base de datos de algún sistema que vayamos a diseñar (cuando una base de datos relacional no era la respuesta porque, por ejemplo, tendríamos que guardar archivos). Quizá un sistema de control de versiones con ciertas restricciones extras que quisiéramos agregar. Quizá un controlador de cambios sobre ciertos archivos. Quizá un backup automatizado. En fin, cualquier cantidad de cosas que ahora podemos aprovechar para usar el motor de Git, directo en nuestro entorno .NET.
Si bien la noticia actual es solamente del primer release público, tenemos que saber que los módulos que lo integran se encuentran en beta y en alpha, con lo que muy seguramente le queda mucho camino por recorrer, pero no deja de ser una opción interesante para el futuro.
Soy un zorrinito C#.
Hace ya algún tiempo que me encuentro desarrollando un proyecto en Joomla, del que quizás hablaré en otro momento. Mi impresión personal del sistema en un principio era buena y prometedora, pero hubo varias razones que luego me hicieron pensar lo contrario. Me sentí raro de tener esa sensación de un sistema tan conocido y usado, pero de alguna forma me alegra no ser el único.
La primera cosa que me impactó en mal sentido es la pobreza de sus actualizaciones. Hace años que vengo escuchandoo de Joomla en su versión 1.0, para que la actual de hoy sea la 1.6 y hace tiempo que ya no veo actualizaciones… cosa más preocupante cuando realmente creo que hay cosas que urgen ser remediadas. Sin embargo, entre ellas hay cuestiones que son de nivel arquitectural, que me atrevo a destacar (citando otras lecturas al respecto).
Antes de entrar en eso, no quiero comparar Joomla con otros CMS (por más que la tentación me lo indique). Sé que CMS hay muchos, y cada uno tiene un enfoque distinto en la forma en la que deben tratarse los datos, los flujos del usuario (es decir, nosotros), la forma en la que debería extenderse, y otras cuestiones extras. No soy quién para decidir si el enfoque de Joomla es correcto o no, incluso a pesar de no encontrarlo cómodo personalmente, pero esa es una apreciación propia.
Voy a completar mi lista citando varias cosas que dijo AhYap en su review de Joomla.
Yendo a los elementos, Joomla hace una suerte de nice URLs pasando parámetros al index.php. Si bien esto puede solucionarse con un .htaccess fácilmente, según parce, Joomla no posee ningún manejo interno de las mismas. No es algo end-user, como quisiera venderse (o como parecería intentar serlo su administrador interno).
Joomla, en su versión 1.6 todavía no tiene soporte para los comentarios a los artículos. Esto me sorprende profundamente. Muchísimos (casi todos?) los sistemas CMSs poseían esa posibilidad, lo cual le daba algo de interacción al usuario, pero… aquí no apareció.
Joomla utiliza categorías y secciones. Si bien el concepto es fácil de comprender, es solamente una jerarquía de dos niveles y estática. Esto trae grandes problemas o, peor, quita flexibilidad. Prácticamente todos los sistemas han adoptado la política de los tags, que podríamos considerar como un superconjunto de categorías únicas. Otros sistemas también agregan la posibilidad de creación dinámica de categorías y de múltiples niveles jerárquicos a demanda.
El punto 4 que menciona AhYap es donde quiero detenerme. Programar en Joomla puede ser muy fácil, o puede ser traumático. La documentación disponible es realmente poca, y mucho de lo que hay se encuentra desactualizado. Peor todavía, Joomla impide el diseño de capas desacopladas, porque no permite la independencia de la forma de generar datos y la forma de mostrarlos. Esta terrible característica pone trabas desde el momento del diseño al momento de la implementación cross-browsing, haciendo que muchos buenos diseños terminen modificándose a la peor de las formas.
Alguien me dijo alguna vez que ya todo estaba hecho para Joomla, solo faltaba buscar el componente e instalarlo. Si bien es cierto que la web está atascada de componentes para Joomla, es un ejercicio interesante entrar a Milw0rm y hacer una búsqueda al respecto. Hagan el ejercicio y busquen Joomla. Igual de atascado y eso no es bueno.
Esto ha sido mi gran decepción. En el intento de creación de un template, tuve en cuenta las mejores y más prolijas prácticas para la web y PHP, para luego tener que desechar muchas para lograr que el sitio se viera como debiera verse. Decepcionante en verdad.
Su organización interna me resultó, por otro lado, terriblemente anti-intuitiva (ni mencionar que creo que le falta un poco de amigabilidad de interfaz). Leyendo la ayuda logré identificar la forma de configurar correctamente su comportamiento, pero se supone que debería de lograrse de una forma más intuitiva. Ofrece (o quiere ofrecer) mucha flexibilidad de contenidos, pero la configuración es ciertamente compleja, cuando se supone que está pensado para los usuarios finales.
Por si no lo conocían, SQLite es una versión base de datos portátil, citando al sitio: “es una librería de software que implementa un motor de base de datos SQL auto-contenido, sin-servidor, sin-configuración y transaccional.” Además, es un motor realmente conocido y usado en muchos lugares (ejemplo, Firefox lo utiliza para el almacenamiento de sus configuraciones y preferencias, o muchas aplicaciones móviles lo usan por su rapidez y sus pocos requerimientos).
Por si fuera poco, además es gratuito y open source. Actualmente su código se encuentra escrito en C, aunque ya hay varias versiones compiladas para Linux, Mac y Windows.
Hace no mucho (desde Julio de este año) está disponible online el proyecto CSharp-SQLite, una versión portada a código managed C# de este motor de base de datos.
Yo ya estoy esperando la oportunidad para probarlo.
Soy un zorrinito lite.
As a personal debt, liking and project, I proposed myself to read the whole book Artificial Intelligence: A Modern Approach (among others) by authors Stuart Russel and Peter Norvig. It is a very recommended book in the subject and just by the size one can tell why. The second edition is the one in my hands and the one I attempt to comment. Due to the same reason (which is it’s great extension and detail), my notes about the book and the subjects this one treats won’t be a summary of them, but personal notes or ideas that may come out of it.
The first chapter, with the title of Introduction is the one I’ll comment right now, and it is in part about the history of Artificial Intelligence as a cience and what other currents were influences or had influenced this one. It is very curious to see how it is something so polemic to suggest imitations of human intelligence, to suggest that machines, algorithms, methods can be “inteligent”, but I personally think it its part of the magic of all this, and one of those points that give so much motivation to investigater further. I don’t doubt that this’ll be a subject deeper dealt with later in the book, so I allow myself to finish my idea here.
It is also notorius to see how artificial intelligence had always been strongly related with other ciences, which makes it particullarly useful and extense, having so many different implications. ¿Would this have epistemologic implications?
On other hand, I’m still suprised (even when I already knew) that there are so many different approaches to define what artificial intelligence is, as it seems that there are different objectives for the same science. The curious thing about this definitions is that they may seem to be mutually exclusive on the way they define intelligence. Half of them take as a reference point the human being, and the others (and this is the interesant part), do not. Those theories consider intelligence against a theoric base where agents should behave a certain way on a certain situation. This subtle difference implies a deep difference in the philosophic conception of all this, as it could get down to conclude that a human being may not be intelligent at all whereas a machine would be. Again, I’ll allow myself to not dig further into this thoughts right now.
Another interesting point is to know that in the 70’s investigators had already generated algorithms that solved intelligence tests (for instance, the ANALOGY program by Evans, for which I though I would have found easily an online version, but I haven’t). This is another great improvement in the demonstration that artificial intelligence really exists. ¿What do we have today, almost in 2010?
Over there in the chapter I read that in an article, Marvin Minsky, along with other investigators had demonstrated that a two-input perceptron couldn’t had the chance of defining when its two inputs where different. This, despise being a detailed fact, imposes a big limit on this whole area, and knowing the existence of those theoric limits is the other part that’ll let us know the real potential of all this, with its boundaries included. I hope I can read that demonstration soon.
With this, my notes on the first chapter of this book finishes, hoping I’ll be able to get on with it on the further ones soon.
I’m an artificial little skunk.
Como deuda personal, gusto personal, y proyecto personal, me propongo leer completito el libro Inteligencia Artificial: Un Enfoque Moderno (entre otros), de los autores Stuart Russel y Peter Norvig. Es un libro muy recomendado en el área y sólo por su tamaño uno puede entender bien por qué. La segunda edición es la que poseo en mis manos y la que me propongo comentar. Por la misma razón (la cual es, su enorme extensión y detallismo), mis notas sobre el libro y los temas que este toque no serán resúmenes de lo que incluya, sino más bien notas personales o ideas que me surgen de las mismas.
El primer capítulo, bajo el título de Introducción, es el que trataré en este momento, y trata en parte de la historia de la Inteligencia Artificial como ciencia y qué otras corrientes fueron influenciadas o influyentes de esta. Es muy curioso observar cómo es algo tan polémico plantear imitaciones de la inteligencia humana, plantear que haya máquinas, algoritmos, métodos que sean “inteligentes”, pero personalmente creo que es parte de la magia de lo mismo, y una de esas cosas que tanta motivación dan para investigar más en el asunto. No dudo que este será un tema abordado más adelante en el libro, así que me permito terminar esa idea aquí mismo.
También es muy notorio ver cómo la inteligencia artificial se ha relacionado fuertemente con otras ciencias, lo cual la hace particularmente útil y muy abarcativa. ¿Tendrá esto implicaciones a nivel epistemológico?
Por otro lado, me sigue sorprendiendo (incluso a pesar de ya haberlo sabido) que existan varios enfoques distintos para definir la inteligencia artificial, pareciendo que existen varios objetivos para la misma como ciencia. Lo curioso de estas definiciones es que parecen ser excluyentes entre sí por la forma en que definen la inteligencia en sí. La mitad de ellas toman como referencia al humano y las otras (y esto es lo interesante), no lo hacen. Estas teorías consideran inteligencia una base teórica en donde los agentes deberán desenvolverse de una forma determinada ante una situación determinada. Esta sutil diferencia implica una separación profunda en la concepción filosófica de todo esto, ya que podría determinar que un humano no sea inteligente cuando una máquina sí lo sea. Me permitiré no avanzar más sobre este pensamiento tampoco ahora.
Otro punto interesante es el saber que ya en la década de los 70’s, los investigadores habían logrado generar algoritmos que resolvían tests de inteligencia (por ejemplo, el programa ANALOGY de Evans, del cual creí que sería fácil ver una versión actual online, pero no ha sido así). Este es otro gran avance en la demostración de que existe la “inteligencia” artificial. ¿Qué cosas tendremos hoy, casi en el 2010?
Por ahí leí también que en un artículo, Marvin Minsky, junto con otros investigadores habían demostrado que un perceptrón de dos entradas nunca tendría la posibilidad de definir si sus dos entradas eran distintas. Esto, más allá de ser un dato detallista, impone un límite a todo ese área, y conocer la existencia de esos límites teóricos es la otra parte que permitirá conocer el verdadero potencial, con sus limitaciones incluidas de varias áreas de la inteligencia artificial. Espero leer detalles de esa demostración en algún futuro.
Con esto finalizan mis notas sobre el primer capítulo de este libro, esperando poder avanzar más sobre los siguientes.
Soy un zorrinito artificial.
Recuerdan que alguna vez hablé un poquito de encodings, y allí explicaba cómo surgían varios tipos de codificación? Entre ellos está el famoso Unicode, que tiene de fantástico ser una especie de codificación “que nos va a servir para todo! (o al menos para varios años más)”… ahora, lo problemático de este encoding es su vasto tamaño, casi como que no podemos saber qué tiene, porque se supone que está casi todo pero no tenemos alguna forma cómoda de navegarlo.
Y aquí es donde la necesidad se volvió la madre de la invención en donde Unicode Table For You nos permite curiosear dentro de esta codificación y ver todos los simbolitos que se han asignado, por páginas y solo navegando con tres sliders de distinta magnitud.
Curioseen, y si quieren buscar algo en particular, siempre pueden hacerlo desde Unicode Character Search de FileFormat.info, o navegarlo de alguna otra forma.
Soy un zorrinito de 16 bits.
Alguna vez publiqué algo de información sobre el libro de Marvin Minsky, La Máquina de Emociones _(_The Emotion Machine), pero nunca había tenido la oportunidad de leerlo en profundidad. Finalmente, a través del paso del tiempo, fui avanzando sobre las páginas – si es que es válida la expresión – del mismo.
El libro es en extremo interesante, pero desafortunadamente la versión online tiene muchos rasgos que nos hacen notar que se trata de un borrador previo a la publicación, debido a la forma poco explicativa de ciertos conceptos, pero no por eso deja de ser muy entendible, siempre cargadísimo de ejemplos y explicaciones que nos permiten comprender lo explicado.
El primer capítulo, Emotional States (Estados Emocionales) plantea principalmente la teoría que se desarrollará durante el resto del libro: las teorías de ciencias cognitivas por lo general fallan porque buscan explicar la mente bajo reglas simples, siendo que posiblemente sea más compleja de lo que estas leyes plantean. Entonces, ¿por qué no plantearla como una combinación de elementos que se relacionan de forma compleja?
Introduce la idea de los recursos, que son (según su teoría) elementos que producen distintas respuestas dentro del comportamiento humano, y cada recurso puede a su vez generar acción en otros recursos. A medida que el tiempo pasa y aprendemos a controlarnos, estos recursos tienen reforzadas o disminuidas las relaciones entre sí, lo que formaría nuestra personalidad. Las emociones fuertes son aquellas que más recursos despiertan, o que generan cascadas de gran intensidad, dejando salir entonces aquellos recursos que más se manifiestan en nosotros de forma más fuerte.
El segundo capítulo, Attachments and Goals (Afectos y Logros) habla de esto, de la forma en la que aprendemos a enlazar ciertos comportamientos con ciertas situaciones. Se introduce el concepto de planificación, el cumplimiento de submetas subyugadas a una meta principal, y el concepto de impresor (imprimer), como aquél agente externo del cual aceptamos el premio o el reproche para modificar nuestra conducta. Finalmente los contrasta contra los conceptos de modelos o impresores ficcionales que modelan nuestra conducta de otra forma.
El tercer capítulo, From Pain to Suffering (Del dolor al sufrimiento) comienza tratando algo de lo que el primer capítulo trató: ¿Cómo es que una emoción fuerte comienza a despertar muchas sensaciones distintas? ¿Cómo es que una emoción o sensación fuerte puede hacernos perder completamente la noción de dónde estamos o qué estamos haciendo? ¿Qué tiene de bueno eso? Aquí también vuelve a hablarse un poco de cómo es que un recurso puede accionar otros y cómo es que la mente puede inducirnos a ciertos estados provechosos para nosotros, aprendiendo de esa misma relación entre recursos (aunque queda pendiente todavía la explicación de cómo la mente tiene auto-conciencia sobre su funcionamiento). Finalmente se hace una contraposición entre las teorías de la conciencia de Freud con la teoría de los recursos activándose.
Hasta aquí ha llegado mi lectura del mismo, pero espero pronto poder continuarla.
Soy un zorrinito con recursos.
Once ago I published some information about Marvin Minsky’s book, The Emotion Machine, but I never had the chance to get to read it deeply. Finally, with time flying by, I kept on crawling through along the pages.
The book itself it extremely interesting, but sadly the online version has lots of quirks that makes us realize it is just a draft prior to publication, due to some of the poor explanation of certain concepts, but it still is quite understandable, always full of practical and simple examples and explanations that allow us to comprehend the concept being developed.
The first chapter, Emotional States proposes the theory that will be developed further in the remaining parts of the book: some cognitive sciences may fail because they want the explain mind’s behavior with simple rules, whilst probably it is really more complex than these rules may call. Then, why not treat it as a complex related element combination?
The idea of resources is introduced here, which are (according to its theory) elements that produce certain responses on human behavior, and each resource may in turn generate action on another ones. As time goes by and we learn to control ourselves, these resources will have their relationships enhanced or decreased, that would define our personality. Strong emotions that those that arise more resources, o that generate great intensity cascades, letting out those resources that are more manifested in us.
Second chapter, Attachments and Goals speaks further on this, about the way we learn to link certain behaviors to certain situations. The concept of planification is introduced here, the achieving of sub-goals subjugated to primary goals, and the concept of imprimer, as that external agent that we’ll accept the reward or the reproach in order to modify our conduct. Finally, it contrasts them against the concepts of models or fictional imprimers that model our behavior on different ways.
The third chapter, From Pain to Suffering starts with some of what the first chapter dealed with: How is it that a strng emotion arises many different sensations? How is it that a strong emotion or sensation may makes us loose the notion of where we are standing or what are we doing? What’s the benefit of all this? Also some of how a resource may activate anothers and how mind may induce us to certain states helpful to us is detailed here, although the explanation on how the mind may learn about the relation between resources and how is it self-aware on its inner working is still missing. Finally, a contraposition between Freud’s counscience theories and the activating resources theory is described.
That’s how much I’ve managed to get on with my reading on this book, but I hope to be able to continue it soon.
I’m a resourceful little skunk.
Varios de mis últimos proyectos han tenido que ver con Windows Azure, la versión Microsoft de cloud computing. Azure se divide en algunas secciones básicas, que al comienzo pueden ser difíciles de entender pero luego se hacen bastante naturales.
Por un lado tenemos los servicios de almacenamiento de datos en Azure, storage services, que pueden dividirse en blobs (datos de tipo blog, divididos en blobs y blogs containers), queues (colas, un tipo de dato cualquiera que se encole en forma FIFO para su consumo por otro lado) y tables. El caso de table suele ser el más útil para el programador común, ya que permite mantener todo el esquema de datos para una aplicación completa en él. Desgraciadamente, el nombre de “table” (tabla) es algo confuso, ya que no existen tales cosas como tablas o menos aún, entidades relacionales. En realidad se trata de un conjunto de elementos estilo property bags, en donde cada entidad se identifica por algún campo que designemos como RowKey y se pueden ordenar (indizar) según algún campo o combinación de campos que indiquemos como PartitionKey. Hay que estar atentos al momento de diseñar la estructura de nuestra aplicación y tener en cuenta esto, ya que de otra forma podría caerse en fallas de performance por tener necesidad de tratamiento relacional entre datos.
Otro de los servicios ofrecidos en la plataforma de Azure son los servicios .NET. Los servicios .NET de Azure pueden comportarse equivalente a una aplicación. En este caso, es el tiempo de ejecución por lo que pagaremos, cuando antes, en el caso del storage, lo que pagábamos era por el almacenamiento y la transferencia de los datos. Los servicios .NET de Azure pueden funcionar como aplicaciones web con interfaces interactivas con usuarios (web roles), como también podrían funcionar como servicios en constante ejecución en background (worker role). También, por supuesto, podemos implementar web services.
Finalmente, el tercero de los pilares para Windows Azure es Live Services, que es una integración con los servicios de Live que Microsoft ha estado desarrollando (y continúa desarrollando) a lo largo de estos años. No he indagado prácticamente nada respecto de este tipo de servicios, pero parece ciertamente prometedor, siempre que uno pueda integrar su unidad de negocios a través de las redes de Live.
Soy un zorrinito celeste.
Para aquellos que desarrollan web, estaría muy bueno un listado de puntos a tener en cuenta para desarrollar / evaluar / medir qué tan bien está hecho un sitio web en base a su usabilidad, o en base a la experiencia del usuario. Para eso una tentativa es usar el documento de Web Usability Guidelines disponible desde UserFocus. Es un listado de 247 puntos a tener en cuenta para el desarrollo de una aplicación o sitio web, divididas en categorías.
Soy un zorrinito web.
Este es otro servicio que sirve mucho a los desarrolladores web, más que nada para lidiar con el problema de tener que probar el HTML desarrollado en distintos navegadores, cuando no siempre es posible tener instalados localmente todos los navegadores para probar. Es el caso, por ejemplo, de los Internet Explorer, en donde tener una versión determinada nos impide tener las demás.
Para eso está CrossBrowserTesting, que es un servicio que nos permite acceder via VNC (tanto basado en web - lo que significa que no hace falta que instalemos nada) como con un cliente VNC local, a un sistema pre-configurado por ellos con una variedad de navegadores. Una vez dentro, podemos probar lo que queramos.
En la versión gratis, cada sesión VNC está limitada a 5 minutos y cuando hacemos un pedido de conexión, nuestro pedido queda en espera, pero en la versión paga, nuestro pedido tiene prioridad sobre los gratis, y la conexión VNC puede ser ilimitada. También tenemos la posibilidad de sacar snapshots de la pantalla y guardarlos como documentación de algún proyecto.
Soy un zorrinito VNC.
Arranquemos primero por el lado de Javascript, para lo cual tenemos una pequeña aplicación llamada Text Escaping and Unescaping in Javascript (del cual una extraña traducción podría ser “Texto en Javascript que escapa y regresa.”).
Una segunda historia relacionada a Javascript es una noticia llamada Una simple linea de Javascript desechó una venta millonaria. De todos modos, considero que el titular es un poco tendencioso, ya que no era una sola línea, sino que, de no estar esa línea, bastantes otras cosas ya la habrían desechado.
Y ahora divirtiéndonos un poco más con el texto les traigo Text Utilities, que es, básicamente, una colección de utilidades misceláneas para trabajar con texto, todo en una simple página.
Y por último, para los programadores: Hidden Features of Perl, PHP, Javascript, C, C++, C#, Java, Ruby, Python, And Others [Collection of Incredibly Useful Lists]… el título lo dice todo.
Soy un zorrinito útil.
Este link del día, debo confesar, va acompañando un remordimiento propio y en representación del de muchos programadores web. Muchos de nosotros sabemos que Internet Explorer es uno de los navegadores más difundidos, y que más tiempo ha estado presente desde 1997 en su versión 4, que fue una de las más difundidas. Tiempo después, muchas cosas cambiaron y en el 2001, la versión 6 vio la luz.
Hoy, ocho años (ocho años!) después, todavía hay mucha gente que utiliza Internet Explorer 6. Esto es un problema para muchos programadores y diseñadores, ya que este navegador desactualizado no se comporta de la misma forma con las páginas que los nuevos. Tratar de hacer un sitio, página o aplicación web que se vea correctamente en todos los navegadores ya de por sí es difícil, pero teniendo un lastre como este se vuelve casi imposible.
Es por eso que existe un proyecto de software libre llamado IE6 Upgrade Warning, que es un script que podemos agregar a nuestros sitios que de forma muy diplomática le hace saber al usuario que su navegador se encuentra desactualizado, y le brinda opciones de otros navegadores o de versiones más nuevas del mismo navegador para descargar e instalar.
…yo creo que voy a comenzar a usarlo.
Soy un zorrinito actualizado.
[EDIT] GC me pasó este dato:
Hay un plugin de Wordpress que hace lo mismo: http://wordpress.org/extend/plugins/ie-warning/
Aunque te da la posibilidad de ser diplomático y de ser un forro (directamente no cargar la pagina si detecta IE6)
Let’s make the Web Faster es el nombre de un conjunto de artículos disponible en Google Code, que explican muchas formas de optimizar una página web, cubriendo muchos aspectos, desde la codificación misma a la configuración del servidor. Las explicaciones son simples y fáciles de seguir, y están ejemplificadas y con muestras de sus resultados.
La mejor parte para mí es la de los artículos, que es en donde está toda la información compilada. Notesén las grandes categorías: CSS, gráficos, compresión, PHP, HTTP caching, prefetch, herramientas, browsers, javascript, latencia percibida (esto es, lo que el usuario tiene la sensación de lo que tarda la página)… y luego un montón de charlas técnicas sobre estos temas en Google.
Por supuesto, cualquiera de nosotros puede participar de la parte de comunidad y sugerir cambios y nuevas ideas a todo esto, con lo cual en cierta forma (y sólo en cierta forma) se vuelve un proyecto colaborativo, o al menos nos dan la oportunidad de opinar.
Soy un zorrinito rápido.
EPH o “Extra Pair of Hands” es el nombre de un servicio de tercerización de atención telefónica, que se supone nos brinda la posibilidad de sacarnos un peso de encima si es que eso toma mucho del tiempo de nuestra estadía en la oficina. Pero eso no es lo interesante de hoy, sino un FAQ que publicaron sobre el tamaño de direcciones de email. El pequeño informe está bastante completo para tratar de un tema tan específico, llegando a hablar incluso de cuánto en memoria se reserva por los programadores en general y cuánto requerirían los estándares. Algo curioso de conocer.
Como extra, les dejo el blog de Cellular Obscura, que es la forma en que este fotógrafo (Shawn Rocco) sigue el mundo. No sé si tenga algo de especial, pero me gustaron las fotos que tiene.
Soy un zorrinito reservado.
Aquellos que no están mucho en el tema de la geolocalización, lo que más cerca habrán estado de encontrar el link del día de hoy útil es preguntarse algo como: ¿Puedo saber de qué ciudad se mandó un email? ¿Puedo saber en qué parte del mundo está alguien?
Para aquellos que están un poco más adentro, saben que un determinado rango de IPs está asignado a determinadas empresas, que por lo general lo utilizan en cierta parte del mundo, y no sólo eso, sino que también distribuyen sus redes en subredes (valga la redundancia) utilizando rangos menores, de forma tal que a veces es posible, con el IP de una determinada computadora, saber desde qué parte del mundo está conectada.
Para eso el día de hoy tenemos a IPInfoDB, un servicio de geolocalización gratuito que tiene dos variantes muy interesantes.
La primera de ellas es la versión web, en donde podemos verificar nuestra localización o la localización de algún IP o dominio.
La segunda de ellas es la posibilidad de bajar una base de datos IP-localización, a nivel de país o a nivel de ciudad. Sí, sí, y no sólo eso, sino que, según prometen ellos, la base de datos se actualiza todos los meses. Nos permiten bajar la versión grande o chica, según lo que nos convenga más. Por último, interesante para aquellos que quisieran agregar esto a sus aplicaciones: no hace falta tener la base de datos localmente, ya que ellos ofrecen una API gratuita utilizable para propósitos de consulta.
Soy un zorrinito geolocalizado.
El día de hoy tuve el gusto de poder participar como disertante en un seminario que se dio en la Universidad FASTA, junto a Adrián Cura, presidente de MUG Argentina, quién se encargó de explicar la parte teórica, y yo dando demostraciones en vivo y en directo de cómo funcionan muchas de las características o fundamentos mencionados.
Si bien el tema de la charla, en lo que se publicó originalmente, trataba del nuevo modelo de programación de ASP.NET con .NET Framework 3.0 o 3.5, ASP.NET AJAX y Windows Communication Foundation, en realidad el temario fue un poco más extenso.
Comenzamos a las 9.15 de la mañana, presentándonos y mostrando un video, la publicidad de Proyecto Natal de Microsoft. Hablamos de la experiencia del usuario, y cómo las nuevas tecnologías apuntan a mejorar esa experiencia y tratar de naturalizar la interacción del usuario con los sistemas, en lugar de adaptar el usuario a los paradigmas de programación. Esto se enlazó con la facilidad que el programador debe tener para poder tener una buena experiencia como desarrollador y las herramientas que posee. Esto a la vez se enlazó y comenzó la exposición sobre .NET Framework 2.0, 3.0 y 3.5 y se explicó qué tiene de nuevo y en qué nos beneficia.
Entre estas cosas, se mencionó ASP.NET AJAX y la gran diferencia que genera en la experiencia del usuario la presencia de AJAX, y la gran diferencia de desarrollo que genera que todo esto esté presente en una herramienta existente, sin necesidad de reinventar la rueda. Tras una breve pausa para tomar un café, se hizo una exposición en vivo de algunos pequeños ejemplos mostrando el funcionamiento de ASP.NET AJAX, explicando cómo funcionaban internamente y cómo hacían transparente al desarrollador y al usuario un montón de cuestiones que siempre fueron necesarias tener en cuenta para el desarrollo web.
Pasamos a una segunda sección, que fue WCF (Windows Communication Foundation). Se habló del paradigma de programación orientado a servicios brevemente, y cómo este pilar de la arquitectura .NET nos provee de herramientas para poder afrontar dicho paradigma. Se habló de los servicios, sus características, y tras haber refrescado todo eso, una breve demostración en donde se podía ver un servicio funcionando, y la manera en que este era implementado a través de las herramientas que Visual Studio 2008 provee.
Finalmente, se pasó a una explicación introductoria a Silverlight y Windows Presentation Foundation, otro pilar de la arquitectura .NET, que se basa en enriquecer la experiencia del usuario y generar una interfaz amigable para cualquier tipo de aplicación, y de qué forma Microsoft provee nuevas herramientas y estándares para no hacer de esto una tarea imposible para los desarrolladores y los diseñadores.
La charla terminó a las 13:00 como se encontraba previsto, aunque nos quedamos un rato más hablando sobre ciertas inquietudes particulares de alguna gente, tras lo cual efectivamente nos retiramos.
Soy un zorrinito ASP.NET.
Recuerdan que en algún caso publiqué una introducción a algoritmos genéticos (que incluía visualizaciones gráficas y todo)? Bueno, varios luego de ver eso me preguntaron “Y esto para qué sirve?” y aparte de la chorrera de palabras que habré largado, poco convincentes, hoy publico también 15 Real-World Applications of Genetic Algorithms.
Por si fuera poco, me animo a publicar otra introducción más al tema, llamada Genetic Algorithms: Cool Name & Damn Simple y otra más: Introduction to Genetic Algorithms, y a republicar el autito generado con algoritmos genéticos, o la evolución de la Mona Lisa.
Soy un zorrinito genético.
Español:
Estos días estuve trabajando en desarrollar un proceso de testing adaptable a empresas que pueden querer tener un ciclo de testing completo (con todo el ciclo de vida del mismo que eso implica) como también tener simplemente un par de días y un par de recursos libres para poder testear. Ante tanta variabilidad, es necesario generar un modelo de testing que sea adaptable y particionable según las necesidades del momento, o según lo planificado con anterioridad.
Para casos planificados, pueden anticiparse testings que comienzan a trabajarse desde los requerimientos del sistema en desarrollo, y pueden incluso seguir el ciclo de vida de desarrollo del software a lo largo del mismo y en paralelo. Este es el famoso modelo en V del ciclo de vida de testing, pero este es el que presenta una gran deficiencia, que es la misma dependencia entre todas sus etapas. Este modelo se ajusta perfectamente a desarrollos con ciclos de vida de cascada, y si bien es fácilmente adaptable a otros ciclos de vida definidos, qué ocurre cuando nuestras etapas no son del todo claras? O peor aún, qué pasa cuando diferentes etapas se mezclan entre sí?
Por supuesto, esta situación no es deseable, pero al momento de darse, también sería deseable que nuestro modelo de testing no sea un contra más en esta situación, sino que permita ser utilizado también para aportar calidad, que es – al fin y al cabo – la finalidad del mismo.
Nuestro acercamiento a dicha tarea fue definir distintos tipos de testing, que variarían según los requisitos que estos tuvieran (documentos en qué basarse, cantidad de recursos necesarios proporcionalmente al tamaño del sistema, tiempo invertido, nivel de capacitación necesaria para los recursos, etc.), y para cada nivel de este tipo de testing, una variante que permitiera evaluar cierto aspecto de un sistema. De esta forma, logramos tener testing que puede ser hasta casi improvisado por los mismos desarrolladores, dejando documentación útil para el futuro del desarrollo del sistema, como a la vez también tenemos testing que puede planificarse desde el comienzo del proyecto y comenzar a trabajarse desde los requerimientos.
Por supuesto, creemos que mientras más haya, mejor, pero esto no es siempre posible, y es una realidad a la que tenemos que mantenernos atentos, porque negarla es condenarnos al fracaso.
Desafortunadamente, no puedo detallar información sobre los tipos de testing que hemos definido (ya que estos son propiedad e información de la empresa), pero los mismos también han sido planeado de un estilo y estructural totalmente formal, de manera que fácilmente puede tercerizarse el trabajo, o realizar testing para terceros de ser necesario o de surgir la oportunidad.
Soy un zorrinito adaptable.
English:
These days I’ve been working on developing a testing process which would be adaptable to companies having a large testing cicle (including the whole life-cycle for testing it implies) as well as companies having just a couples of days they can use for testing and few resources available. On such variability, it was necesary to generate a testing model which would be adaptable and partitionable acording to particular necesities, or according to what can be planned in the project.
For cases where the testing is a planed part of the whole development cycle, testing itself may begin from the requirement specification and may even follow the whole development life-cycle at the same time. This is the famous V-model of testing life-cycles, but this model presents a great deficiency, and it is the same dependency between all of its internal stages. This model adjusts perfectly to developments with waterfall life-cycles and, it is even adaptable to other well-defined life-cycles. But what happens when these life-cycles do not have well-defined stages? Or, even worse, when this stages are sometimes mixed-up?
Of course, this situation is not desirable at all for a project, but, when it is found, it would be desirable that our testing model does not fall with it, but should allow us to be used also to give more quality – i.e., the purpose of it.
Our approach to this task was defining several different types of testing, which would vary from the requirements they had (documents on which to be based on, resources needed according to project size, time invested, knowledge level required for resources, etc.), and for each of these levels of testing, different variants which would allow us to evaluate a certain aspect of a system. This way, we achieved having testing processes which could be improvised by the developers themselves leaving useful documentation for future developments, as well as it could be also used for being planned and start being analyzed by a testing team from the very beggining of the development proces.
Of course, we belive that as more testing, best quality can be achieved, but this is not always posible, and this is a fact we should take into account, as deying it is condemn ourselves to failure.
Unfortunately, I’m not allowed to go into details on about the different types of testing we’ve defined – as they are our company’s property – but these types of testing had been designed with a formal structure and style, so that they can be also used to be outsourced to other testing companies, or that, needed the case, we could be testing another’s company code.
I’m an adaptable little skunk.
El otro día, leyendo un post de I know the answer (it’s 42) hablando sobre cuál es el post del blog por el que te conocen (cosa que generalmente suele ocurrir), me desvíe leyendo otro de los artículos que él linkea, llamado The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) […la frotó sobre una piedra, la colgó de un abedul…]. Dicho post en particular habla de toda la historia que hay detrás de las distintas representaciones de los caracteres y la forma de codificarlos. Muy fácil de leer y hasta muy didáctica. Importante para los desarrolladores y buen dato para los curiosos (notesé que tiene fecha del 2003… y aún aplica muy bien).
Por ahí también anda el link a la página oficial de Unicode, que es actualmente el repositorio más grande de información que hay sobre símbolos utilizados para la transmisión de información, desde letras latinas y números hasta símbolos matemáticos y caracteres ideográficos.
Como extra también tenemos una página para testear distintos encodings en nuestro navegador (aunque a mí no me anduvo del todo bien), o una que tiene varios elementos todos juntitos, acá o acá.
Soy un zorrinito latin-1.
En estos días mientras anduve haciendo los code reviews se me ocurrió estandarizar de alguna forma cómo podrían estos hacerse y de qué forma podría “puntuarse” al código evaluado en cuestión. Por ahora, eso último queda pendiente (ya que es lo más difícil de determinar y no lo más útil), pero lo primero se convirtió en un conjunto de categorías y puntos que pueden ser muy interesantes tener en cuenta al momento de ver el código y ver qué se puede mejorar de él.
Seguro que esta lista que viene a continuación está lejos de estar completa, y que se podrían agregar y quitar un montón de cosas, pero lo tiro como una introducción a esto que quiero (queremos?) terminar de formar, que nos puede llegar a ser muy útil.
PD: No creo que nada de esto sea “requerido” para que un sistema esté “bien”, sino que partiendo de que funciona, podemos decir “qué tan bien” o “qué tan mal” estamos.
Estandarización / Legibilidad de código
¿El código está comentado explicativamente?
El código debería estar acompañado de comentarios que expliquen qué es lo que se está haciendo y por qué más allá de explicar el cómo. A la vez, el código debería ser lo suficientemente claro como para que se entienda cómo es que se está resolviendo un problema en particular.
¿Los nombres son significativos?
Debería entenderse qué función tiene una variable, un método o una clase cuando se lee el nombre que se le dio.
¿El código de una clase accede a la información que necesita de forma correcta?
Si una clase necesita información de otras debería pedirla en los parámetros de sus métodos o en su constructor. Las propiedades también son una buena opción.
¿El código se encuentra correctamente modularizado?
El código de un método no debería excederse en tamaño, y debería ser explicativo en unas pocas líneas de código sobre qué es lo que está haciendo. De ser compleja su acción, debería repartirse en varios pasos que se desdoblen en todo lo que deban hacer.
Arquitectura
¿Se respeta el concepto de la arquitectura propuesta?
Sea cual sea la arquitectura propuesta para la aplicación, debería respetarse el esquema que esta propone, poniendo la lógica de la aplicación en donde esta debería estar, el acceso a datos en otro lado, etc.
¿Se encuentran separadas las capas de la misma lo suficiente?
De existir distintas capas en la arquitectura, estas deberían encontrarse lo suficientamente separadas como para depender de cada otra sólo como distintos módulos de un sistema y nunca según su implementación.
¿Qué tan fácil sería camiar alguna de las capas por una implementación distinta?
Como medición de la independencia de las capas, el acto de crear una nueva implementación para una de ellas debería ser tan costoso como la implementación misma y no más que eso. De ser de otra forma, existe dependencia en la implementación de las capas.
Code-coverage
¿Existe un testing definido para el código escrito?
Debería existir alguna forma de probar el código escrito, cualquiera sea su metodología.
¿Las pruebas testean que el código devuelva resultados correctos en escenarios esperados?
Las pruebas deberían testear, como caso esencial, que el sistema se comporte correctamente ante determinados escenarios.
¿Las pruebas testean el comportamiento del código en escenarios no esperados?
Las pruebas deberian testear, como caso adicional, determinadas situaciones no comunes, o incluso situaciones que no deberían darse, para poder probar la forma en la que el sistema responde al mismo.
¿Ocurre esto último con cada uno de los datos de entrada?
Las pruebas con elementos erróneos o inesperados deberían variarse para cada uno de los datos de entrada, pudiendo evaluar qué tan sensible es el sistema a la variación de cada uno de estos.
¿Ocurre esto último con combinaciones de los datos de entrada?
La misma situación es aplicable a la combinación de distintos datos de entrada. A veces la variación de los datos de entrada de forma individual no genera problemas, pero una determinada combinación de los mismos, sí. Así también puede evaluarse la correlación que tienen estos datos de entrada respecto del funcionamiento del sistema.
Estabilidad
¿Qué parte del código se encuentra atrapando excepciones o situaciones no esperadas?
El sistema debería programarse considerando que pueden darse situaciones adversas que puedan afectar el correcto funcionamiento de los bloques sobre los que depende. Si bien un extremo de esto llevaría a la reescritura de todo el código en cada capa superior (lo cual no sólo es imposible sino indeseable), debe considerarse que un bloque del que dependemos, cuanto menos, no esté disponible.
¿Cómo se comporta la lógica de tratamiento de errores?
Un sistema debería tener al menos una rutina de tratamiento de errores, que controle la situación o alerte al usuario.
¿Puede una situación imprevista alterar el funcionamiento del sistema?
La ocurrencia de un error o una situación no esperada no debería generar comportamientos no esperados del sistema. Posiblemente resultados erróneos, pero el comportamiento del sistema debería mantenerse estable.
Flexibilidad
¿Cuánta información utilizada es parametrizable, versus la que se encuentra codificada en el sistema?
La información que se considera “fija” para el sistema debería poderse parametrizar, para otorgar más flexibilidad en casos especiales en donde la misma se viera sujeta a cambios.
¿Es extensible el funcionamiento del sistema o sus funcionalidades?
En caso de no poderse alterar el código de la aplicación, debería existir cierta posibilidad de agregarle funcionalidad desde la entrada o la salida de datos.
¿Qué tanto afecta al sistema agregar una funcionalidad?
En caso de tener que agregar una funcionalidad al sistema, la menor cantidad de módulos deberían verse afectados, y nunca debería verse afectado el código de otras funcionalidades.
¿Qué tanto afecta al sistema quitar una funcionalidad?
En caso de tener que quitar o deshabilitar una funcionalidad al sistema, el código de las demás funcionalidades no debería verse afectado.
¿Qué tanto afecta al sistema el modificar la implementación de una funcionalidad?
En caso de tener que alterar una funcionalidad del sistema, el código de las demás funcionalidades no debería verse afectado.
¿Cuánto afecta al sistema que cambien las reglas de negocios?
Si las reglas de negocio que definen el comportamiento del sistema cambiaran, sería deseable que la menor parte del sistema se volvería obsoleto, y que el resto pudiera ser reusado para la implementación de las nuevas reglas de negocios.
Recursos
¿Qué recursos requiere el sistema para su funcionamiento?
Sería deseable que un sistema requiera la menor cantidad de recursos posibles. Estos incluyen tanto la utilización de procesador, memoria, tiempo de ejecución, sistemas sobre los que depende, bases de datos, archivos en disco, etc.
¿Cuánto tiempo hace uso de los recursos versus cuánto tiempo los retiene ociosos?
Sería deseable que en el momento mismo en que el sistema ya no hace uso de un recurso, lo libere. A veces esto puede ser contraproducente por cuestiones de performance, pero de todos modos sería deseable que lo haga.
Performance
¿Cuánto tiempo requiere el más pesado de los procesos que efectúa el sistema?
Los procesos que requieren mucho tiempo de ejecución deberían ser optimizados al máximo posible, ya que en ellos se encuentra el peor de los casos que el sistema puede encontrar.
¿Cuántos cuellos de botella se identifican en el flujo de información / acciones del sistema?
Sería deseable que existan alternativas para que un punto en particular no sea determinante de no poder utilizar el sistema. A veces las reglas de negocios requieren que así sea, pero de no ser necesario, es deseable que existan vías alternativas de continuar con el flujo de utilización del mismo.
Seguridad
¿Cuántos datos de entrada son validados por el sistema en cuanto a su tipo de datos?
Los datos que entran al sistema deberían controlarse si son válidos para el tipo de datos que deben representar. Ejemplo típico es el de los datos numéricos, o de fecha, que muchas veces se leen simplemente como cadenas.
¿Cuántos datos de entrada son validades en cuanto a sus restricciones según su uso?
Los datos también deberían validarse según su contenido, es decir, que contengan un valor que tenga sentido en el ámbito en el que se necesita usar. Ejemplo, una fecha de nacimiento del 1/1/0001.
¿Qué medidas toma el sistema para la protección de los distintos recursos que utiliza?
Algunos datos alteran el funcionamiento del sistema (recursos tiempo de ejecución, memoria, etc) y otros se envían a ser almacenados en determinados recursos del sistema (recursos de bases de datos, archivos, etc). Todos estos recursos deben verse protegidos de datos que hagan al sistema abusar de ellos, como ser por ejemplo los loops infinitos, el escalado de prioridades, SQL Injection, XSS, etc.
¿Qué usuarios tienen acceso a la utilización del sistema y cuáles no?
Es deseable que el sistema restrinja el acceso a los usuarios que efectivamente deben hacer uso de él y tienen permitido acceder a la información que el sistema maneja.
¿Qué usuarios tienen acceso a la administración o configuración del sistema y cuáles no?
De la misma manera, el sistema debería restringir el acceso solo a determinados usuarios que puedan modificar su configuración o comportamiento. A veces es incluso deseable que este perfil de usuarios no puedan tener acceso al resto de la información que el sistema utiliza, sino solo a la información de configuración en sí.
Para aquellos que hacen web / flash / loquefuera, Preloaders.net es una aplicación web que les permite armar fácilmente preloaders para sus aplicaciones, de una forma elegante y bastante simple. Se le puede personalizar el color, el tamaño, la velocidad de animación entre otros parámetros.
Por otro lado Custom Buttons 3 es un proyectito que andan desarrollando en StopDesign, que, si quieren ir derecho a lo que hay hoy en día, pueden visitar el Custom Buttons 3 Demo. La idea es correctamente utilizar el elemento <button> de HTML y poder estilizarlo de forma propia. Ya los pueden ver ahí qué tan elegantes pueden verse.
Y ya que estamos con lo web, dejo también un pequeño documento que da una referencia del DOM Core, que me hace un poco de falta aprendermeló.
Soy un zorrinito web.
Paseando por ahí me encontré con un proyecto llamado WWW SQL Designer, que apunta a la creación visual de esquemas de bases de datos, tablas, y relaciones en un entorno visual, enteramente utilizando HTML, CSS y Javascript. Por si fuera poco, en realidad se trata de un proyecto open source, hosteado en una de las páginas de Google Code. Desde allí puede bajarse e instalarse en algún sitio local para que utilicen quienes tengan acceso a ese servidor.
Soy un zorrinito web.
Para aquellos que me seguían a través de algún feedreader habrán notado que de golpe no hubo más actualizaciones (o, de otra forma: “habrán dejado de notar que había actualizaciones”). Esto se debía a un problema de configuración que surgió un tiempo después de que reconfiguré los subdominios… el por qué, no lo tengo claro todavía, ya que con el subminio nuevo ya había entradas y estaban correctamente publicadas.
Ahora supongo que es cuestión de tiempo para que todos los feeds que quedaron apretados esperando salir aparezcan en sus correspondientes lectores. Posiblemente tengan un rato para leer. Ojalá lo disfruten.
Soy un zorrinito con problemas.
El día de ayer me crucé con un post sobre cómo hacer un diseño de base de datos inmune a SQL Injection (o en su título original: A comprehensive database security model). La idea resumida de este tipo es hacer un diseño de base de datos orientado completamente a la seguridad, por lo cual, incluso aunque el supuesto atacante lograra acceso directo a la base de datos, no podría hacer más que acceder a los datos que podría desde la aplicación en cuestión.
La idea está buena, pero en algunos puntos me parece impracticable, aunque sí me hizo surgir ideas parecidas mucho menos complejas que podrían utilizarse… pero eso será motivo de algún post extra o taller. En fin… dicho sea de paso, dejo el link direct al blog de ese artículo, llamado The Database Programmer, que conforma una serie de posts dedicados a cuestiones sobre la programación de base de datos, pero desde un punto de vista algo más abstracto. No tanto el “como”, sino el “qué”, lo cual lo vuelve más interesante.
Soy un zorrinito de datos.
Desde Hackzine me llega un artículo sobre un pequeño script que Shaun Friedle construyó sobre javascript utilizando Greasemonkey. El script en sí toma la imagen que Megaupload muestra para verificar que uno es humano, y la descifra utilizando una red neuronal.
El script de Shaun puede verse completito aquí. Si se preguntan de dónde salen los valores de constantes que Shaun pone ahí, yo supongo que será el resultado de haber entrenado ya a la red neuronal, al fin y al cabo, el CAPTCHA decoder no tiene que aprender, solamente reconocer.
Si quieren una explicación un poquito más extensa, pueden visitar el artículo de John Resig al respecto, o simplemente verlo funcionando.
No subestimen el poder de javascript. D=
Soy un zorrinito del lado del cliente (por esta vez).