
Flujos de trabajo en git
Los más comunes y el historial de cambios que generan
Desde la última vez que dí una actualización sobre what-now ha pasado un tiempo considerable. Mi intención original era ser más consistente con estas actualizaciones, a modo de diario de desarrollo, pero varias cosas me detuvieron. Por un lado no quise convertirme en spam o publicidad de un producto que ni siquiera vale la pena, y por otro lado, no siempre tengo algo interesante que contar.
Ahora sí lo tengo, de forma que procederé a contar qué aprendí en estos últimos meses, comenzando por los flujos de trabajo de git.
Los cambios en what-now
Desde que di mi actualización la vez pasada, estas nuevas características fueron incluidas en what-now como producto:
- [#13] Agregué la página de about (que luego desapareció por el rediseño visual)
- [#1] Agregué la posibilidad de editar tareas ya agregadas.
- [#2, #3] Agregué la posibilidad de seleccionar una tarea y verla destacada. Esto es tanto en el listado de tareas como en el gráfico.
- [#6] Resolví que los textos largos no se mostraban en múltiples líneas en el gráfico.
- [#8] Le dí algo de estilo y diseño a la aplicación. Deliberadamente dejé dispositivos móbiles de lado. Quité la página de about y una 404 que casi no se usaba.
- [#10] Agregué la posibilidad de cargar y guardar las tareas a un archivo en disco.
- [#9] Hice más fácil poder agregar varias tareas rápidamente.
- [#18] Resolví que una tarea dependiera de sí misma, congelando la aplicación.
- [#20] Mejoré la forma en la que se grafica para que se muestren gráficos complicados sin que se mezclen los caminos.
- [#21] Agregué autocompletado y “tagging” para elegir dependencias de una tarea.
- [#27] Resolví unos problemitas de estilo con resoluciones pequeñas.
Historia en commits
La razón por la que pude poner tan fácil en palabras qué cambios ocurrieron de una fecha a otra, a modo de bitácora de cambios (changelog) es porque convertí a GitHub en mi changelog. Es posible eliminar la historia de los commits dejándolos sólo con la información relevante para el futuro.
Flujo 1: branch, merge
Yo estaba acostumbrado al siguiente flujo en git:
- Nueva rama “
myFeature” partiendo desdemaster - Trabajar en
myFeature(commit, commit, commit…). Trabajo terminado. - Actualizar
myFeaturepara que tenga los últimos cambios de master:git merge master- Resolver conflictos y problemas que hayan ocurrido de esos cambios
- Una vez todo resuelto, actualizar
master:git checkout master git merge myFeature - Eliminar la rama:
git branch -D myFeature
El resultado de este es lo esperado: una rama master siendo actualizada y el historial del cambio de cada rama disponible en el historial de git. Esto es también lo que hace por defecto GitHub si manejamos pull requests y merges desde la aplicación web.

Ejemplo de flow “branch, merge” en git. Tomado de Nightwatch[/caption]
A veces tenemos la suerte suficiente como para que el paso 4 no requiera commits de ningún tipo, con lo cual desaparece uno de los commits de merges, y sólo queda el original del paso 3. En esos casos, veremos algo como la figura siguiente.
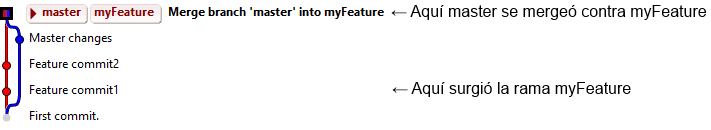
Esto no quiere decir que no haya ocurrido el paso 4, sólo que no hace falta un commit particular para el merge, con lo que el marcador de la rama master sólo actualiza su posición y se mueve hacia adelante (fast-forward).
Flujo 2: branch, rebase, fast-forward
Algunos meses atrás descubrí que git rebase es una herramienta muy poderosa, ahorrándome el problema de commits gigantes de merge. El nuevo flujo sería así:
- Nueva rama “
myFeature” partiendo desdemaster - Trabajar en
myFeature(commit, commit, commit…). Trabajo terminado. - Reposicionar
myFeatureen la punta de master:git rebase master- Resolver conflictos y problemas que hayan ocurrido de estos cambios
- Una vez todo resuelto, actualizar
mastergit checkout master git merge --ff-only myFeature - Eliminar la rama:
git branch -D myFeature
A diferencia del flujo anterior, este eliminó esos commits gigantes de mergeado de ramas, en donde cambiaron muchos archivos y en donde se resolvieron muchos conflictos, para aplicar eso en cada commit particular, haciendo que el resultado final sea el mismo a que si hubiéramos trabajado desde la última versión de master (cuando esa versión todavía no existía – por eso git permite viajar en el tiempo). Las desventajas es que al solucionar conflictos en el proceso de un rebase, uno también se remonta a estados parciales de nuestra implementación, lo que quiere decir que a menos que tengamos una forma simple de asegurarnos que todo quedó bien, es posible que ese commit ya no sea de confiar.
Imaginen el siguiente escenario: tengo mis commits 1, 2 y 3. En cada uno de los tres commits, el proyecto funcionaba pero mi funcionalidad estaba siendo terminada. Cuando hago el rebase con master me encuentro que tengo conflictos en commit1. Es un archivo en donde hubo muchos cambios tanto en master como en mi rama, por lo que sé que también encontraré conflictos en commit2 y commit3. Como testear mi aplicación es un proceso costoso, resolveré los conflictos de la forma que mejor me parezca pero sólo al final de estos merges verificaré si todo está bien, como para hacerlo una sola vez. Al hacerlo, me encuentro con que hubo un error en mi resolución de conflictos, y lo resuelvo, resultando en commit4. Tras todo esto, el estado de commit1, commit2 y commit3 ya no son de fiar. Sabemos por seguro que en commit3, la aplicación no funciona del todo bien, y commit1 y commit2 están en duda.
Esta desventaja no es algo muy importante pero ciertamente hay que tener en cuenta. Además, con el uso de unit testing y acceptance testing automatizado, ya no es tan difícil verificar aspectos variados, con lo que se hace más simple asegurarnos que nuestros conflictos hayan sido resueltos correctamente.
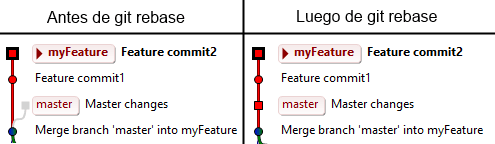
Este flujo se deshace de esos commits de merging, que suelen ser confusos. La línea de desarrollo es, en su mayoría, directa (excepto cuando myFeature1 y myFeature2 deben mergearse), y el avance de la rama principal es directo.
Flujo 3: branch, rebase, squash, fast-forward
Un tiempo después empecé a jugar con git rebase -i, y las posibilidades que brindaba. Descubrí que me permitía manipular los commits mientras estoy haciendo el rebase. No solamente sus contenidos, sino además el orden en el que se aplican, si se agrupan en un único commit (o varios), si se ignoran, etc.
Esta ciertamente es una herramienta poderosa y hay que usarla con cuidado. Cambiar cosas en el pasado tiene consecuencias en el futuro.
- Nueva rama “
myFeature” partiendo desdemaster - Trabajar en
myFeature(commit, commit, commit…). Trabajo terminado. - Reposicionar
myFeatureen la punta de master:git rebase master- Resolver conflictos y problemas que hayan ocurrido de estos cambios
- Una vez todo resuelto, convertir el feature en un único commit:
git rebase -i masterElegir: pick, squash, squash, …
- Actualizar master:
git checkout master git merge --ff-only myFeature - Eliminar la rama:
git branch -D myFeature
Esto dejará nuestro master limpito y sin historias innecesarias. El detalle necesario puede agregarse en las líneas posteriores del commit, y personalmente prefiero que la primera línea tenga una indicación del feature en sí. Esto nos deja una línea de historia muy clara y fácil de inspeccionar.
Pueden ver un ejemplo de esto en mi proyecto what-now, en el historial de commits:
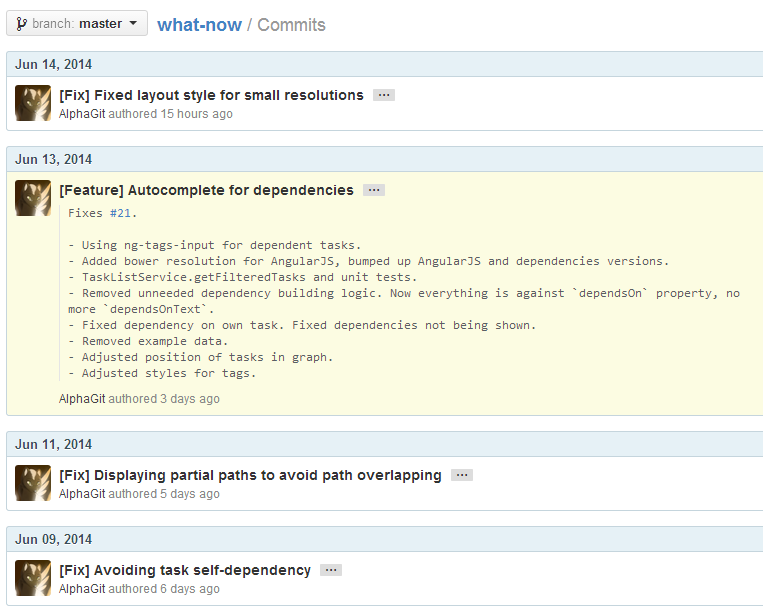
Este flujo soluciona el problema de los commits no confiables porque simplemente desaparecen. Hay quiénes no se sienten cómodos con esta aproximación justamente por eso: se pierde el historial del desarrollo parcial de un feature particular. Personalmente, no lo veo como un problema: me parece útil mientras se está desarrollando una parte del sistema, pero para el futuro eso ya no tiene importancia.
Otro problema que esto implica es que ramas que se desprendan de myFeature estarán basándose en commits que ya no existen, por lo que los intentos de merge o rebase aplicarán esos commits nuevamente, resultando en conflictos dobles. Esto puede solucionarse de dos formas: ignorando esos commits en rebases contra master (porque ya están aplicados), o haciendo squash / cherry-pick de los commits en todas las ramas, para que todas estén actualizadas. Personalmente prefiero el primero, pero no siempre es obvio cuáles son los commits a ignorar, por lo que hay que tener cuidado. (Reescribir historia y borrar es doblemente peligroso.)
Este es mi flujo de trabajo favorito al día de hoy. Además de dejar una línea de historia limpia y entendible, esa historia misma se convierte en el historial de cambios de la aplicación. Esto tiene utilidades de soporte y de mantenimiento a futuro: se puede saber qué característica introdujo un cambio – el hecho de en qué punto de ese desarrollo ocurrió es irrelevante. Las pruebas, idas y vueltas desaparecen. Los errores que tuvieron que ser corregidos a medio camino desaparecen.
Mejor aún, esto proporciona una medición real de cuánto tiempo tardó en ser liberada una característica en particular, ya que es fácil saber cuándo fue incluida en la rama principal. Esto ayuda a los equipos a generar estimaciones basadas en tiempos, incluyendo todas las partes de su proceso.
Conclusión
Aunque es más trabajo al momento de trabajar con los commits, el flujo de git rebase squash proporciona la línea de tiempo más simple para utilizar a futuro y de referencia, lo cual creo que es una gran ventaja. Como mencioné, este es mi flujo favorito al día de hoy y con el cual me encuentro trabajando siempre que es posible.