Archive: 2012
101 posts published in 2012

A black and white figure's thought-hive
101 posts published in 2012
La búsqueda del sonido perfecto
Siempre fue de mi filosofía que si uno pasa mucho tiempo en una determinada actividad, debe hacer toda la inversión posible para que sea muy disfrutable. Es muy parecido a la Ley de Amdahl: siempre conviene invertir en mejorar las partes más grandes y, como aconsejan muchos sistemas de productividad, solucionar los problemas más graves primero.
En mi caso, la cuestión era relativa a la música. Prácticamente todo el tiempo estoy escuchando música, así sea mientras trabajo, mientras me divierto, mientras leo algo, o simplemente de fondo mientras hago algo más. Tener una buena experiencia mientras escucho música iba a ser, entonces, para mi un cambio muy grande en la forma en la que puedo apreciarla.
Para aquellos que no conozcan mis gustos musicales, se trata de estilos de música en donde realmente se hace un uso continuo de la banda de frecuencias disponibles. Pasando por el heavy metal y el metal sinfónico, terminando en el power metal, el electro dark y el dubstep. Este es el tipo de música (aunque no los únicos) en donde ser escuchados con buena y con mala calidad dejan ver dos obras completamente distintas, y como siempre digo “hechas para ser escuchadas a alto volumen”.
¿Por qué es tan importante visualizar?
Aparentemente, visualizar no es para todos. No me refiero a imaginar cosas, sino a literalmente poder visualizarlas, como si estuvieran frente a los ojos. Esta es una habilidad/fenómeno llamada Closed-eye hallucination, o closed-eye visualization. Aparentemente, cuando llegan a ser lo suficientemente vívidos como para parecer objetos reales, reciben el nombre de Remote Viewing, bajo la premisa que uno está en el plano espiritual interactuando con objetos que no están físicamente delante de uno.
Para un poquito más de background, hay muchos niveles a los que esto puede ocurrir, y no es común que ocurra en la gente. Los primeros niveles son visualización de colores y un poco de ruido o variación en los tonos del color que realmente se ve. Estos no deben ser confundidos con las pequeñas manchitas que corresponden al líquido de la córnea o a suciedad en el ojo. Estos son totalmente normales y ocurren muy frecuentemente, pero los siguientes niveles, en donde ya se involucran objetos de cierta complejidad, o incluso superposición de dichos objetos con objetos del mundo real solo puede ser alcanzada por la mayoría de la gente con el uso de psicotrópicos. Para una minoría de la gente, esta habilidad puede desencadenarse de forma natural y hasta voluntaria.
Universal Principles of Design es un libro más que recomendable sobre conceptos de diseño en general: no se limita ni al software ni al diseño de productos físicos. De hecho, ni siquiera se centra tanto en el diseño como en los conceptos que están detrás de los buenos diseños, a quienes les da la atención principal.
¿Qué son y cuándo usar cada uno?
Ahora que el mundo web se ha acelerado de forma increíble, CSS3 y HTML5 son más y más poderosos cada día. Una de las características que trajo CSS3 son media queries, que habilitan un nuevo tipo de sitio llamado responsive web. ¿Qué es esto y cómo nos afecta?
Open source & automatic deployments
Aquí hay dos noticias en realidad: Por un lado, Alpha’s Manifesto, el theme de este blog, es ahora open source (work in progress) y por otro lado, logré configurar deployments automáticos para cuando ocurran cambios en este theme.
Videos resumidos luego del release oficial
Ya casi llegando al final de esta investigación sobre qué tiene Vs2012 para ofrecernos, estoy ya probando la versión oficial, ya lista para trabajo en producción. Mucho de lo que encontré en ella no es una sorpresa para mí, y mis entregas anteriores se hicieron desde el Release Candidate. Hay muchos más cambios que ocurrieron entre ese RC y la versión final, algunas superficiales (como la pantalla de Start Page), otras debo descubrirlas aún.
Hay muchos más videos al respecto que dejaré a disposición de ustedes, pero esta vez, en lugar de agrupar el contenido por video, lo haré por funcionalidad y dejaré las referencias al final. Sin embargo, voy adelantando que muchos de ellos vienen directamente de Visual Studio 2012 Premium and Ultimate Overview de Channel 9, y del blog de Scott Hanselman.
Novedades de VS2012 en Videos
Hoy tomé una aproximación distinta. Me acerqué a conocer qué hay de nuevo en Visual Studio de una manera no tan exploratoria sino siguiendo lo que Microsoft tiene para contar al respecto. Desde mi última prueba, algunos cambios de nomenclatura ocurrieron. Ahora VS11 se llama VS 2012, y Metro se llama Windows 8 UI (hasta que le encuentren un mejor nombre).
Empecé con una serie de videos de Channel 9. A continuación están los videos más jugosos sobre Visual Studio 11 (2012) y detalle resumido de cada uno.
El manual de Nick Fury para coordinar equipos
Cuando escribí mi review de la película Avengers mencioné lo siguiente:
Nick Fury es el coordinador de ese movimiento [Avengers defendiendo al mundo], y con su actitud de badass se encarga de dejar claro qué es lo que estamos enfrentando y qué es lo que él está dispuesto a hacer.
De hecho, ese último punto me gusta mucho y lo usaré como referencia luego. Se nota mucho como él, creyendo en su grupo a pesar de las deficiencias del mismo, pone en peligro mucho de su persona y de su carrera personal para permitirles hacer lo suyo. Ya habrá otro post sobre eso.
Esta parte de la película (no se preocupen, no arruinaré la trama) me trajo una anécdota muy interesante y algo que quiero destacar sobre la forma en la que MakingSense busca hacer su trabajo. En esta historia, el Consejo (autoridad) no creía que los Avengers fueran la solución y deciden hacerlos de lado, haciendo caso omiso de las recomendaciones de Nick Fury y sus palabras de esperanza. Cuando ellos, de forma determinante, deciden que el grupo de Nick no tiene nada que hacer, él deja todo de lado. A riesgo de perder su carrera, ser acusado de traición y hacer fracasar toda la operación, él toma un lanzacohetes y elimina un avión del Consejo.
¿Qué mejor forma de demostrar que **tenemos confianza en nuestro equipo **que tomar un lanzacohetes y defender al equipo, arriesgando todo?
Don't repeat yourself
En cierto punto en el camino de evolución de una compañía o un desarrollador, se encuentra como hecho el estar siempre re-haciendo las mismas partes, o reutilizando partes comunes que alguna vez ya se usaron para un proyecto anterior. Esto es muy común, y ciertamente no es algo malo. De hecho, es deseable, y en el ámbito recibe el nombre de DRY principle.
Cómo los entrepeneurs de hoy usan la innovación continua para crear negocios exitosos
The Lean Startup es no sólo el título del nuevo libro de Eric Ries, sino además el nombre del movimiento que él inició intentando reestructurar la forma en la que se ve al entrepeneurship y a la innovación dentro del mundo que vivimos. Este movimiento tiene su sitio principal en el sitio de The Lean Startup.

Quizá más conocido por ser uno de los co-fundadores de IMVU, Eric Ries, quien es activo en su blog Lessons Learned y en su cuenta de twitter, intenta con este libro desmitificar al proceso de las startups y a toda la especulación que rodea al mundo de los entrepeneurs, y exponer procesos y maneras en la que se puede tratar con la gran incertidumbre en una startup.
Eric cuenta en su libro que las startups pueden existir en varios entornos distintos, incluso en grandes organizaciones, pero todas tienen algo en común: intentan innovar en entornos con gran incertidumbre. En base a eso, y en base a las historias que se han escuchado de éxitos, él nos cuenta cómo evitar ser uno de los tantos fracasos (esos de los que nunca se cuentan anécdotas) e introduce herramientas para trabajar y disminuir esa incertidumbre, utilizando toda la rigurosidad del método científico en cuanto a resultados, procesos y producto.
Muchas de las ideas y herramientas que él introduce no son nuevas – y él así lo reconoce – pero unificadas pueden ser una forma poderosa y segura de enfocar el trabajo a resultados, y de saber que vamos por el camino correcto, algo que debe saberse cómo asegurar. Su aporte es justamente esa: lograr integrar varias metodologías de campos dispares para tener métodos fiables cuando el ambiente de trabajo no lo es.
Everything that does not contribute to the final result is a form of waste.
Herramientas como lotes pequeños (small batches), cajas de arena (sandboxes) para experimentación, métricas segmentadas, la regla de los cinco “porqués” (the five Whys), reuniones de decisión de cambio vs. perseverancia (pivot or persevere meetings) y otras tantas que él nos explica cómo aplicar, y nos muestra como se pueden utilizar en una buena cantidad de industrias. Muchos ejemplos vienen del mundo del software, muchos de la industria automotriz, y de áreas más variadas como la educación, así asegurando que estas son útiles de forma multidisciplinaria. Otros ejemplos vienen de startups pequeños y otros de empresas grandes o gobiernos. Historias interesantes y cautivadoras sobre como IMVU llegó a ser cómo es hoy desde el fracaso que fue en sus primeros años, cómo Groupon comenzó con solo un blog hasta convertirse en la empresa multinacional que hoy conocemos, cómo Toyota quiso cambiar el mundo con técnicas anti-intuitivas para la industria en la que compiten y tantas otras historias forman parte de las enseñanzas basadas en casos reales y con lecciones que aprender.
Executing the wrong plan correctly from start to finish is the perfect way to achieve failure.
Este, a ser sincero, es un muy buen libro y deja claro un método muy simple que puede aplicarse en prácticamente cualquier aspecto de nuestra vida. Sólo le critico ser un poco repetitivo, en pos de asegurarse que el lector comprenda la importancia de algunas prácticas, y dejar cuestiones abiertas a la discusión (por ejemplo, el manejo del conocimiento y del aprendizaje en grupos multitudinarios). Sin embargo, este ensayo es un comienzo en este movimiento aún inexplorado, y como tal, es ya un primer paso muy avanzado.
Le doy 4 de 5 zorrinitos, bien ganados.
Soy un zorrinito entrepeneur.
Unleash the power of .bat!
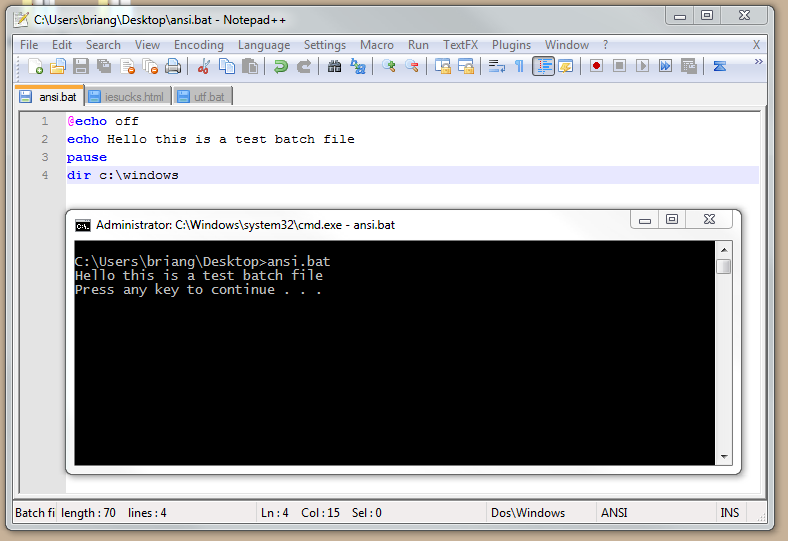
Para los que trabajamos en Windows, es bastante común que en algún momento u otro terminemos automatizando alguna tarea a través de batch files. Por supuesto, aquellos que también trabajamos con Windows desde hace tiempo (incluso desde los tiempos de DOS) seguramente no les tengamos mucha confianza por que estaban bastante limitados.
Por suerte para nosotros, ese ya no es el caso, y los batch files contienen una buena cantidad de habilidades que los hacen una herramienta muy valiosa. Personalmente opino que no llegan al nivel de un shell script, pero aún así nos permiten hacer muchas cosas.
Para una buena mirada a varias características que por lo general no obtienen la atención merecida, miremos el post de StackOverflow Hidden features of Windows Batch Files, que de seguro nos dará una nueva visión de lo que podemos y no podemos hacer.
Soy un zorrinito batch.
Alias: el _Inception_ de los ingenieros sociales.

El mes pasado en la entrega del newsletter de Social-Engineer.org (Volumen 03, Entrega 33) me enteré de un concepto llamado Priming. Este concepto es muy parecido a lo que se hizo popular con la película Inception (El Origen), en donde alguien le siembra una idea a alguien más para dejarla aflorar y entonces hacer uso de las ventajas que esa idea nos da, haciéndole creer a alguien más que es una apreciación puramente propia.
Bueno, no es tan exactamente así. El artículo nos cuenta cómo el priming _(primado _en español) puede y es usado por vendedores y políticos para generar asociaciones entre elementos que comúnmente no relacionamos, o que simplemente no tienen relación, pero de estarlo afectan la forma en la que los vemos. El mejor ejemplo son el de las encuestas llamadas Push Poll, una encuesta en donde el propósito de la misma no es realmente obtener información de los encuestados sino forjarles una idea internamente.
Por supuesto que esto también puede ser usado a nuestro favor, y el artículo explica algunos puntos a ser tenidos en cuenta. Un estudio psicológico más profundo en el tema nos revelará otros factores que están relacionados para poder utilizarlo más eficientemente.
Soy un zorrinito primado.
Completar misiones tomando fotografías
OneFeat es una aplicación con el motto de “Play Life. Level Up.” El concepto del juego es ayudarnos a salir a conocer el mundo y a compartir nuestras experiencias, a través de fotografías. Cada fotografía que publiquemos estará relacionada a una misión del juego, que nos permitirá avanzar en el mismo a otras misiones.
Las misiones son también propuestas por los propios usuarios y podemos elegir cuáles aceptar y cuáles no. Nuestra galería de logros de por sí se convertirá en una buena cantidad de anécdotas a compartir, y este es, ciertamente, uno de los pocos juegos que nos obligan a salir al mundo a conocer.
Soy un zorrinito fotógrafo.
Manos a la obra desde lo más básico

Acabo de terminar de leer el libro jQuery Novice to Ninja, de la editorial SitePoint y de los autores Earle Castledine y Craig Sharkie. Debo decir que el libro ha sido una buena elección de lectura.
Para empezar, el libro asume que el lector tiene pocos conocimientos de jQuery y de JavaScript en general, lo que hace que cualquiera, con niveles de conocimientos básicos de programación web, pueda hacer utilización de él. A pesar de eso, el libro no es lento en la forma en la que va presentando conceptos, y para aquella gente que no está divertida con la teoría y quiere poner manos a la obra: el libro está completamente planteado desde un punto de vista práctico y manos a la obra. De hecho, el libro viene con código fuente gratuito que podemos descargar para que se convierta en los ejercicios que el mismo libro propone, dándonos en los capítulos las soluciones y las explicaciones, y permitiéndonos replicar para asegurar nuestro conocimiento.
Pensé al principio que comenzar desde conceptos básicos sería un mal signo, porque seguramente estarían permitiendo malas prácticas filtrarse para explicar determinadas características, pero este libro probó que yo estaba equivocado: siempre se refuerzan las buenas prácticas (y se explica por qué) y el libro hace un esfuerzo considerable por mostrarnos la buena importancia del progressive enhancement, del cual seguramente escribiré más adelante.
Efectivamente, el libro termina en las facetas más avanzadas de jQuery, incluyendo Theming y Plugins. A estos dos les dedica muy poca longitud y detalle, en comparación al resto de las temáticas. Plugins fue cubierto, de forma implícita, en el resto del libro cuando hablaba de namespacing y scoping (también buenas prácticas) y theming fue algo que básicamente no se tocó. También se cubrió ligeramente jQuery Mobile. Estas últimas parte fueron un poquito decepcionante por lo corto de las explicaciones, pero aún así estuvieron presentes.
Notesé que el libro es sobre jQuery y no sobre JavaScript, por lo que si esperaban ver patrones avanzados de JavaScript y modularización, programación funcional, currying y cosas así… este no es su libro. Aún así, para alguien que se dedica a desarrollo frontend y especialmente alguien que quiere entrenarse en esta librería, utilizando buenas prácticas y manos a la obra, es un libro esencial.
Le doy 5 zorrinitos.
$(‘#zorrinito’).soy();
Sobre cómo elegir la tecnología correcta
Cuando una organización, por grande o pequeña que sea, quiere comenzar su presencia en el mercado mobile, hay una pregumta que siempre surge y que muchas veces no les resulta fácil resolver. ¿Qué es más conveniente: utilizar tecnologías web y sus capabilidades para llegar a todos los dispositivos, o utilizar el framework propio de los dispositivos para utilizar todo el potencial que ellos ofrecen?
Está claro que una solución web puede hacer uso de todas las nuevas tecnologías, incluyendo HTML5, CSS3, las nuevas versiones de JavaScript y una variedad de trucos que muchos programadores conocen, pero utilizar el lenguaje nativo de los dispositivos hace que nada sea imposible. Entonces, ¿cuál es la más apropiada?
Como siempre, la respuesta correcta no es absoluta, sino que varios factores juegan al momento de una desición estratégica. Primero, consideremos los beneficios y problemas de cada elección, lado a lado.
| Web (HTML, JS, CSS) | Lenguaje nativo | |
| A favor |
|
|
| En contra |
|
|
Existe una tercera opción que he elegido no listar: los híbridos. Son compañías o frameworks que aseguran la llegada a una mayoría de dispositivos, solucionando la necesidad de aprender distintos lenguajes. Sin embargo, estas soluciones por lo general son tercerizadas (es decir, corren la aplicación por su cuenta), o son wrappers (es decir, toda nuestra aplicación corre dentro de otra aplicación que ellos proveen) o simplemente revierten a aplicaciones HTML sin demasiado poder. El mercado todavía está surgiendo para estos frameworks y hay resultados muy variados con ellos aún, razón por la cual he elegido dejarlos fuera de la consideración de hoy.
Tomar una decisión según cuál opción tenga más ítems de su lado puede parecer una solución fácil, pero realmente no es la más sabia. La decisión debe alinearse con los objetivos estratégicos de la organización, incluyendo el mercado destino, el tipo de usuario que se espera tener, los recursos disponibles para afrontar el desarrollo, y el tipo de llegada que la aplicación desea tener.
Como un buen ejemplo, muchas empresas grandes quieren entrar al mercado mobile, y deben hacer algo digno de su nombre, pero quieren tener presencia en todos los dispositivos. Al mismo tiempo, startups pequeñas quieren hacer una inversión pequeña para aproximarse al mercado. En estos casos la mejor opción será web, excepto que requieran capacidades especiales (como acceso a la red celular, o acceso USB, etcétera).
En los otros casos, o cuando el público destino es un conjunto de usuarios muy particular, las soluciones nativas pueden ser las más apropiadas. Por ejemplo, cuando el usuario serán oficiales de seguridad de una empresa, haciendo uso de la cámara o acelerómetro del teléfono, las organizaciones pueden decidir que tal o cuál marca de dispositivo con tal o cuál versión será la apropiada y reducir el desarrollo a un sólo lenguaje.
O "shenanigams para que nadie use nuestro sistema"

Por un desarrollo propio me encuentro investigando las APIs de integración a LinkedIn, específicamente para buscar información de gente, publicar ofertas de trabajo y obtener información de las mismas. Por supuesto, me interesan las APIs porque la aplicación que estoy desarrollando involucra más que solo esas partes, y por tanto, la información debe estar correlacionada. Suena razonable, ¿verdad?
El departamento legal de LinkedIn parece opinar distinto.
El último punto de mi registro de clave API son los T&Cs (Terms & Conditions), que especifica claramente qué cosas se pueden y no se pueden hacer con la API. Veamos un poco de ellas. Los pueden acceder aquí: LinkedIn API Terms of Use.
LinkedIn reserves the right, from time to time, with or without notice to you, to change these Terms in our sole and absolute discretion. The most current version of these Terms can be reviewed on the LinkedIn developer portal at anytime and supersedes all previous versions. By using the LinkedIn APIs after changes are made to the Terms, you agree to be bound by such changes. Your only recourse if you disagree with the Terms, or changes to the Terms, is to discontinue your use of the APIs. Accordingly, we recommend you review these Terms periodically.
Este punto, en un primerísimo párrafo cinco (al 23 de Junio de 2012) ya es aberrante. ¿Qué tan cómodos se sienten ustedes firmando cheques en blanco? Yo, sinceramente, nada. Esto es lo mismo: LinkedIn puede hacer uso de nuestra alma si les da la gana, y como nuestra aplicación sigue haciendo uso de las APIs, ellos son dueños de nuestro culo porque ese request HTTP significó “acepto cualquier cosa que digan los T&Cs”. Para hacerlo más interesante, no hay fase de aceptación, y pueden hacer cambios sin o sin notificación.
Como extra me causa gracia el “from time to time”. Está tan mal puesto en la frase que puede entenderse como “podemos cambiarlo de tanto en tanto”, o como “nos reservamos el derecho de tanto en tanto”. Me pregunto si este texto tuvo revisiones.
1.3 APIs License Grant. Subject to the terms and conditions in these Terms, we grant you a limited, non-exclusive, non-assignable or non-transferable license under LinkedIn’s intellectual property rights during the Term to use the APIs to develop, test, and support your Application, and to distribute or allow access to your integration of the APIs within your Application to end users of your Application. You have no right to distribute or allow access to the stand-alone APIs.
En ningún momento se define legalmente quién es “you”, es decir que se entiende a la persona que está firmando esto. Curiosamente, el formulario de registro habla de administradores de aplicaciones, desarrolladores y perfiles. ¿Significa esto que you somos “nosotros”? ¿O significa que por el hecho de sumar a una segunda persona ya estamos en falta? No importa realmente, si a LinkedIn le da por aclarar algo que a nosotros no nos convenga, ya firmamos nuestro cheque en blanco.
1.5 Restrictions. In addition to other restrictions contained in these Terms, you agree not to do any of the following, unless expressly permitted by LinkedIn in these Terms or in writing by LinkedIn:
(…)
f. Require your users to obtain their own Access Code to use your Application.
g. Use your Developer Account or Access Codes to build and/or distribute enterprise applications outside your own company (e.g. use the APIs to build an Application that you distribute to other companies).
¡Good bye open source! No podemos distribuir una aplicación que tenga integración con LinkedIn porque estamos forzando a usuarios a generar un código de acceso a APIs. Sigamos el razonamiento: hacemos una aplicación redistribuíble que está integrada a LinkedIn, pero no podemos dar nuestros códigos por lo especificado en el punto 1.3. Curiosamente, tampoco podemos pedir que alguien use su propio código porque violamos la sección 1.5.f-g. Way to go, LinkedIn.
h. Request or publish information impersonating a LinkedIn user, misrepresent any user or other third party in requesting or publishing information;
Definición muy vaga para ser legal: misrepresenting. Digamos que si a un usuario no le gustó la forma en que está escrita una frase, ¿nos convierte a nosotros en violadores de los términos y condiciones de LinkedIn? Por supuesto que podemos tener una confirmación previa para que el usuario haga lo que le da la gana, pero si es así, ¿qué valor agregado tenemos? Y si no tenemos valor agregado… ya les digo qué pasa.
m. Store LinkedIn user data other than the Member Token or OAuth Token for any LinkedIn user, with the exception of a user’s profile data when given explicit permission by the owner of the profile as set forth in 3.4, below. User profile data obtained in accordance with this section and 3.4 below may not be updated without the user’s subsequent consent;
Sooo, no hay correlación de datos. Nuestra aplicación no puede guardar nada de nuestro usuario, y nada de terceros si se necesitara, incluso información que fue dada en entornos públicos. Supongo que podríamos escanear el sitio de LinkedIn sin hacer uso de la API, ¿verdad? Sigamos leyendo…
n. Use the APIs or Brand Features for any illegal, unauthorized or otherwise improper purposes,** or in any manner that would violate these Terms** (or any document incorporated into the Terms), or breach any laws or regulations, or violate any rights of third parties, or expose LinkedIn or its members to legal liability in your use of the APIs;
(énfasis mío.) Los Términos y Condiciones de uso nos impiden violar los términos y condiciones de uso. ¡Muy inteligente, LinkedIn!
o. Combine content from the APIs with other LinkedIn data obtained through scraping or any other means outside the official LinkedIn APIs. This includes acquiring LinkedIn data from third parties;
Nope, no se puede usar el sitio. Tampoco se pueden combinar datos de las APIs con el resto de los datos. Estamos limitados a usar la API, pero no podemos almacenar lo que la API nos devuelve. Bueno, el requerimiento anterior decía “lo mínimo posible para que la aplicación funcione”, quizá yo estoy exagerando.
u. Use the Content for generating advertising, messages, promotions, offers, or for any other purpose other than, and solely to the extent necessary for, allowing end users to use the returned Content in your Application;
Oops, qué lástima que no se pueda publicar contenido. Una lástima porque ya no sé qué vamos a hacer con las APIs de publicación de estados, de publicación de trabajo o de compartir contenido. Una lástima.
x. Use the APIs in an Application that competes with products or services offered by us;
Estoy sospechando a este punto que no podemos entonces desarrollar aplicaciones que hagan algo distinto de lo que hace LinkedIn (ver más adelante sobre las restricciones de uso de los datos), pero si hace lo mismo entonces tampoco está permitido, porque estamos compitiendo. ¿Qué opción nos deja LinkedIn? Ninguna, sea como sea que utilicemos esta API, estamos ligados a violar los términos de uso (que también está prohibido por los términos de uso).
z. Use any robot, spider, site search/retrieval Application, or other device to retrieve or index any portion of LinkedIn services or collect information about users for any unauthorized purpose;
Como decíamos, confirmando que no se puede obtener información del sitio.
1.6 Support and Modifications. We may provide you with support or modifications for the APIs in our sole discretion. We may terminate the provision of such support or modifications to you at any time without notice or liability to you. We may release subsequent versions of the APIs and require that you use such subsequent versions. Your continued use of the APIs following a subsequent release will be deemed your acceptance of modifications.
Traducción: “no garantizamos que funcionen en el futuro, nos importa poco lo que ustedes hayan hecho”.
1.7 Fees. The APIs are currently provided for free, but LinkedIn reserves the right to charge for the APIs in the future. If we do charge a fee for use of the APIs or any developer tools and features, you do not have any obligation to continue to use the LinkedIn’s developer resources.
Traducción: “no garantizamos que vayan a ser gratis”.
1.9 Usage Limitations. LinkedIn may limit the number of network calls that your Application may make via the APIs, and/or the maximum Content that may be accessed, or anything else about the APIs and the Content it accesses as LinkedIn deems appropriate in its sole discretion. The usage limitations can be found in the LinkedIn developer portal at http://developer.linkedin.com/. LinkedIn may change such usage limits at any time. In addition to its other rights under these Terms, LinkedIn may utilize technical measures to prevent over-usage and/or stop usage of the APIs by an Application after any usage limitations are exceeded. If no limits are stated in the Platform Guidelines, you nevertheless agree to use the APIs in a manner that, as determined by us in our sole discretion, exceeds reasonable request volume or constitutes excessive or abusive usage.
Esto tiene dos partes. La primera, como ya habrán leído, aclara que ellos van a hacer lo que mejor les parezca con los límites de uso. La segunda, que me parece ridículamente absurda en un contrato legal: “estás de acuerdo en usar las APIs de una forma que nosotros queramos, pero no te diremos cómo”. Es realmente irrisorio que consideren esto parte de algo expuesto públicamente.
2 Proprietary Rights
2.1 LinkedIn Property. As between you and us, we own all rights, title, and interest, including without limitation all intellectual property rights, in and to, the (i) APIs, and all elements, components, and executables of the APIs; (ii) the Content available from the APIs; (iii) our Website; and (iv) our Brand Features (collectively, the “LinkedIn Materials”). Except for the express licenses granted in these Terms, LinkedIn does not grant you any right, title or interest in the LinkedIn Materials. You agree to take such actions, including, without limitation, execution of affidavits or other documents, as LinkedIn may reasonably request to effect, perfect or confirm LinkedIn’s rights to the LinkedIn Materials.
¿Significa esto que toda la información que recuperemos a través de las APIs son propiedad de LinkedIn? Sí. Incluyendo información de tu usuario, mí usuario, y la información que públicamente se encuentra disponible allí. Cabe aclarar que esta es una directa contradicción del acuerdo de usuario, en donde dice:
- License and warranty for your submissions to LinkedIn.
You own the information you provide LinkedIn under this Agreement, and may request its deletion at any time, unless you have shared information or content with others and they have not deleted it, or it was copied or stored by other users. Additionally, you grant LinkedIn a nonexclusive, irrevocable, worldwide, perpetual, unlimited, assignable, sublicenseable, fully paid up and royalty-free right to us to copy, prepare derivative works of, improve, distribute, publish, remove, retain, add, process, analyze, use and commercialize, in any way now known or in the future discovered, any information you provide, directly or indirectly to LinkedIn, including, but not limited to, any user generated content, ideas, concepts, techniques or data to the services, you submit to LinkedIn, without any further consent, notice and/or compensation to you or to any third parties. Any information you submit to us is at your own risk of loss as noted in Sections 2 and 3 of this Agreement.
(énfasis mío.) Cabe aclarar que cambiar el copyright por completo está fuera de estos términos. En fin, continuemos con el documento original:
3.4 Data Storage and Conversion Limits.
3.4.1 Prohibition on Copying and Storage. You may not copy, store or cache any Content returned or received through the APIs, including data about users, longer than the current usage session of the user for which it was obtained, except for the alphanumeric user IDs (Member Tokens) which we provide you for identifying users or any individual member’s authentication token (OAuth Token) which we provide you when a LinkedIn user authenticates your Application to his LinkedIn account.
(…)
3.4.3 Exception to Storage and Conversion Limits with User Consent. The restrictions of this section do not apply to user profile data received through a one-time call through the APIs that a user explicitly permits you to collect and store, provided that you obtain the user’s consent through the technical and user-interface specifications provided by LinkedIn, and that any subsequent update to the profile data only be done with the user’s explicit consent. PLEASE NOTE: a) User profile data does not include information about a user’s connections, which may not be copied or stored; and b) you may only use stored profile data for the benefit of the LinkedIn user that granted you permission to access it.
Fuck! Nada, de NADA podemos hacer con las APIs. Nuestra aplicación debería ser explícitamente entonces una interfaz para usar LinkedIn. Pero, si analizamos, por los puntos de competencia, no podemos ofrecer servicios similares, y si no podemos correlacionar datos, entonces ¿qué podemos hacer? Mostrar una interfaz distinta para hacer lo mismo que hace LinkedIn, pero entonces seríamos competidores y eso tampoco está permitido.
Haber leído estos términos y condiciones me decepciona mucho. Tenía la esperanza de usar estas APIs para algo interesante y realmente parecen estar bien construidas, de forma que son simples de usar y tienen muchas opciones interesantes. Desafortunadamente, me encuentro en un hueco legal que no puedo evitar. Invito a abogados o a especialistas en el tema corregir cualquier error que yo haya podido cometer, pero mi interpretación de esta licencia es que, haga lo que haga, voy a caer en una violación de la misma.
Me pregunto siquiera como empresas serias pueden considerar tener este tipo de acuerdos legales expuestos de forma pública. El concepto de protegerse de absolutamente todo y no dar ningún tipo de garantía debería espantarnos terriblemente a todos y negarnos a usar estas cosas hasta que el acuerdo sea razonable. Por supuesto, esto se torna monopólico porque todos lo hacen y entonces les damos nuestra alma con tal de estar a la par con otras organizaciones que tienen integraciones con X cantidad de servicios.
“¡Pero no pasa nada!”, seguro algunos pensarán. A ellos les pregunto: si se olvidan la tarjeta de crédito en un club en donde todos son muy buena onda y “nunca pasa nada”, ¿la reportan como robada? Si la respuesta fue sí, entonces ya tienen su respuesta.
Lo lamento LinkedIn, pero tu departamento legal me mantuvo alejado. Desmientan lo que digo, realmente quiero que me hagan ver que estoy equivocado.
Soy un zorrinito decepcionado.
La gran diferencia del detalle
Hemos visto como a través de los años las interfaces de los sistemas operativos y las distintas aplicaciones (también las web) han evolucionado y cambiado radicalmente su aspecto visual. Muchos más colores, formas redondeadas, animaciones y feedback que nos indica qué está pasando a cada momento.
| Uno de los elementos que más cambio ha tenido son los indicadores de progreso. Desde las líneas que giraban simulando un progreso, usando los caracteres -, /, | y \ en una consola, hasta el uso de caracteres Unicode con barritas que se iban llenando, hasta las hermosas interfaces de hoy de colores y animaciones. |
Cabe aclarar que los indicadores de progreso vienen en dos sabores. Uno de ellos es el indicador de progreso indeterminado, el cual indica que hay un progreso ocurriendo de fondo en nuestra aplicación, pero sin indicar qué tan cerca estamos de terminar esa operación. Muchos de estos hemos visto en Youtube y distintas páginas que hacen uso de ajax. Wikimedia tiene una linda galería de estos, pero para ejemplo, aquí tienen uno:
El otro tipo de indicador es la barra de progreso propiamente dicha. Esta barra es el concepto básico que indica un límite en donde el trabajo ha sido terminado y nuestra posición respecto de completar esa tarea. Una búsqueda en Google Images devuelve muchas, muchas imágenes para saber de qué estamos hablando, y mejor aún, PrettyLoaded es un sitio (Flash) con una galería continua de pre-loaders que reutilizan este concepto con distintas formas.
Ahora, asumiendo que una tarea siempre tarda el mismo tiempo, el indicador de progreso puede hacer una diferencia en la velocidad aparente que como usuarios percibimos, y podría ser bien la diferencia entre cancelar una descarga que signifique una compra o esperar unos pocos segundos más. Esta velocidad percibida es también llamada velocidad aparente, y si bien está relacionada a la velocidad real, hay otros factores que pueden hacerla aparentemente mayor o menor.
La velocidad aparente se encuentra afectada por muchos factores, como bien publicó Anthony, de UXMovement, en el artículo llamado How to Make Progress Bars Feel Faster to Users. A diferencia de muchos artículos que se encuentran en la internet, este está respaldado por estudios de la gente de Carnegie Mellon University, de los Laboratorios de Investigación de AT&T, y de la Universidad de New York. (Los links están al final del mismo.)
Las características que mencionan aquí son las siguientes:
Una característica de las nuevas interfaces ha sido la capacidad de entrelazar imágenes en estos mismos indicadores. Muchas veces es una forma de demostrar que la aplicación sigue funcionando aunque la barra de progreso mantenga su posición, de la misma forma que el caracter que giraba nos indicaba también que el programa seguía funcionando. Sin embargo, el tipo de animación también puede tener un efecto sobre la velocidad aparente del progreso general.
Y lo que han descubierto es que cuando esta animación se mueve en sentido contrario a la dirección de progreso de la barra, la sensación de velocidad es mayor.
Los indicadores de progreso (tanto barras como indeterminados) pueden hacer uso de pulsaciones como parte de la animación. Esto es más común en las barras de progreso, en donde todo el color de la barra es cambiado por un momento y vuelve a su estado normal, repitiendo esta acción cada tanto tiempo, dando la sensación de una pulsación.
Los estudios demostraron que mientras más frecuentes son estas pulsaciones, mayor es la velocidad aparente. Por supuesto, puede que no resulte agradable al ojo del usuario si es demasiado frecuente. Un truco extra también mencionado es que a medida que nuestra barra está avanzando, la frecuencia de las pulsaciones puede ir aumentando, también generando la sensación de un aumento en velocidad, incluso aunque realmente no sea tal.
Supongamos por un momento que el progreso de nuestra tarea es fijo, y que cada tantas unidades de tiempo, siempre tendremos tantas otras unidades de avance en nuestro progreso. Mantener esa monotonía de avance es, si bien realista, no la mejor opción para dar la sensación de progreso. Según mencionan los estudios, incrementar la velocidad del progreso hacia el final genera una sensación de menor tiempo insumido en la tarea en general, incluso aunque los tiempos suma sean los mismos.
Recuerdo haber leído que entre Windows Vista y Windows 7, este había sido uno de los cambios de interfaz en el momento de copia de archivos, a pesar que la estrategia de copia de archivos no había cambiado, y la diferencia era notable. Desafortunadamente, no logro encontrar el artículo en donde originalmente leí eso.
La pausa final, que ocurre muy comunmente si se está haciendo un procesamiento al final de la tarea, arruina la sensación completa de velocidad que el proceso había ganado. Por supuesto, seguramente estemos en un punto en donde el usuario ya no decide cancelar la acción, pero con ella hemos logrado arruinar la sensación de un proceso rápido que el usuario sentía. Esta puede ser la diferencia entre volver a usar nuestro sistema o no en un futuro, así que cuidado.
Los estudios originales son:
Soy un zorrinito con progreso.
Debugging de energía colaborativa

Desde el feed de i.MicroSiervos me llega la noticia de Carat, un sistema que nos aconseja sobre maneras para hacer que nuestro dispositivo móvil haga mejor uso de su batería y dure más.
Está disponible tanto para Android como para iOS, y lo más curioso es que la fuente de información es puramente colaborativa. Es el mismo uso de los dispositivos que sirve como fuente de información para identificar las características que insumen más batería para que de esa forma se pueda desrecomendar su uso a quienes no la utilizan activamente. De esta forma, mientras más uso se haga de la aplicación, más información habrá para utilizar.
La versión de iPhone no está tan preparada en cuanto a interfaz gráfica, pero es totalmente funcional y ya está dando buenos consejos sobre cómo mejorar la calidad de vida de nuestra batería (y nuestro battery-lifecycle). La de Android se ve más bonita en cuanto a interfaz y la funcionalidad es básicamente la misma que la de iPhone.
Este sistema está desarrollado por el AMP Lab (Algorithms, Machines and People Laboratory) de la Universidad de Berkeley, en un pequeño grupo de cinco personas. Sin embargo, el proyecto es open source y se puede encontrar en GitHub, para hacer un fork y ayudar a trabajar sobre él.
Soy un zorrinito ahorrador.
Un lenguaje de programación visual
Blockly es una apuesta de Google para enseñar programación desde los bloques más básicos con esa misma aproximación: bloques.
Gracias a la novedad visual (y la autogeneración de código que ocurre por detrás) se puede programar fácilmente con encajar piezas de rompecabezas, de forma muy intuitiva. Lo que nos demuestra es que se ahorraron la complejidad de la sintaxis de un sistema reemplazándola por un rompecabezas, que vuelve el conocimiento de sintaxis en un juego.
Existen tres demos para Blockly actualmente:
Parecería por estas características no se trata sólo de un intento de educación, sino también la capacidad de extender aplicaciones propias de una forma visual y fácil de comprender. Imaginen permitirle a los usuarios de un sistema “programar” cómo debe comportarse el sistema en determinados casos. Realmente es una opción muy poderosa de extensibilidad, sin requerir la complejidad de saber programar.
Soy un zorrinito en bloques.
Automatizando nuestra vida, un teléfono a la vez
De parte de MicroSiervos me entero que Microsoft está desarrollando un sistema de macros basadas en eventos para teléfonos móbiles. El proyecto se llama on{X} y aquellos que conozcan IfTTT verán una gran similaridad.
El sistema se basa en eventos porque los macros se disparan según determinadas situaciones se presenten. Ver las recetas pre-armadas ya les dará una idea:
Como esas, se pueden hacer muchas, ya que el código detrás de ella es simple JavaScript, lo que permitirá que una gran comunidad comience a construir sobre ellas. En este momento solo funciona para teléfonos Android (Microsoft, really?) pero esperemos que pronto se extienda el soporte. Todavía la comunidad en los foros y el blog están algo vacíos, pero nuevamente, es algo muy reciente todavía.
Yo realmente pienso que esta idea puede despegar.
Soy un zorrinito automatizado.
Una historia real
Una muy bonita anécdota que tenemos para contar cómo nuestro trabajo en User Experience comienza a dar sus frutos es una historia que a César le gusta contar, específicamente por la fuerza que esta historia tiene.
La historia comienza con MakingSense trabajando en una propuesta para un cliente nuevo. Siendo nuevos en nuestras tratativas con esta empresa (una empresa con altos estándares de seguridad), queremos realmente mostrar lo mejor que tenemos. La aplicación que debíamos realizar era desafiante desde el concepto que trataba, porque involucraba mucha seguridad, muchas tecnologías nuevas y muchas características que ayudan al usuario pero hacen difícil de congeniar con las anteriormente mencionadas. Nuestros arquitectos trabajaron en resolver ese problema pero las propuestas siempre resultaron más concretas cuando se puede ver el resultado final.
Entonces también se invirtió mucho en la zona de User Experience de esta propuesta. Sabrán ustedes que estamos haciendo presión sobre este tema últimamente (y si andan leyendo por aquí, seguramente lo habrán notado). Creemos que el UX es un factor de valor agregado, creemos que cuando todo lo demás está bien hecho, este marca una diferencia increíble.
De vuelta en la historia, el equipo de MakingSense trabajó en hacer un buen pre-diseño de user experience, lo que involucraba el desarrollo de flujos de usuario, screenshots de cómo podría llegar a verse el producto, muchos mockups y pequeños prototipos que nunca vieron la luz, pruebas de concepto, etc. Cuando uno trabaja para un proyecto que no es proyecto aún, sabe que está en riesgo. Sabe que si no se concreta la oportunidad, fue tiempo y dinero perdido.
El día de la propuesta se acercaba y las gotitas de sudor iban siendo más comunes en la frente de los involucrados. Se hizo muchisimo hincapié en esos screenshots, se cuidó hasta el ultimo detalle, se hicieron varias rondas del desarrollo del UI (interaction design, wireframes, IA) hasta llegar al diseño final con el que se estaba listo para presentar.
Finalmente, el día llegó.
César asistió a esa reunión en donde nos presentábamos de manera formal con nuestro cliente (aunque ya había habido tratativas informales anteriormente) y pusimos el proyecto sobre la mesa. Se explicó por qué MakingSense era apropiado para hacer el proyecto, se explicó qué teníamos en mente para solucionar su problema, y se mostraban algunas pantallas que ejemplificaban cómo podría haber quedado el sistema terminado.
En ese momento de la reunión la tensión subió. El arquitecto que pertenecía al cliente interrumpió la conversación, dijo “Esperen”, y se fue de la habitación. En menos de dos minutos estaba de vuelta con alguien más, y lo presentó como el CEO de la empresa.
“Quiero que él vea lo que ustedes pensaron”, nos explicó. “Estas pantallas son más de lo que teníamos en mente, definitivamente queremos que esto se vea así, y que de ahora en adelante, todo lo que hagamos sea así.”
Traduciendo la experiencia, ellos sabían lo que querían que el sistema haga. No sabían la diferencia que se podía hacer con UX, no sabían que se podía brindar una experiencia totalmente nueva y agradable, especialmente cuando los sistemas tienen muchos requerimientos de seguridad, o cuando la complejidad son los árboles que no dejan ver el bosque.
La propuesta se convirtió en proyecto y el cliente se convirtió en partner, y hemos trabajado juntos para lograr maravillosos productos.
Sobre el punto en donde dos mundos se tocan
¿Puede la naturaleza ser un modelo de cómo resolver problemas de las ciencias? La pregunta tiene una respuesta obvia. Sabemos que sí, sabemos que muchos procesos pueden copiarse desde la naturaleza para mejorar la forma en la que resolvemos determinados problemas. Desafortunadamente, muchas veces, determinadas áreas de las ciencias quedan fuera porque la relación con el mundo natural está algo alejado. Por ejemplo, las ciencias de la computación o la aritmética.
Sin embargo, hay gente que sabe ver ese tipo de relaciones. Por ejemplo, el caso de micahoover, quién se preguntaba qué algoritmo de búsqueda realizan los relámpagos al caer. Y parecería que, curiosamente, es una búsqueda de tipo simulación Monte Carlo (Monte Carlo Search: A New Framework for Game UI [PDF]).
O el caso de Vihart, quien tiene una serie de videos hablando sobre Doodling in Math: Spirals, Fibonacci and Being a Plant (Part 1, Part 2, Part 3), en donde nos cuenta, desde el punto de vista de una planta, cómo maximizar el consumo de luz solar sin que nuestras hojas nos tapen otras hojas y cómo la serie de Fibonacci y las espirales son la forma de lograrlo.
Estos son dos ejemplos de muchos otros que deben haber ahí afuera (los invito a contarme de más si los conocen)
Soy un zorrinito natural.
Iconos minimalistas para todas las ocasiones
The Noun Project es una colección de iconos minimalistas, la gran mayoría libres para usar. Cada imagen tiene asociada un sustantivo que lo describe, y por lo general la imagen es una buena representación de esa palabra. Disponible tanto en inglés como en español para buscar, esta galería de imágenes nos permite inspirarnos como diseñadores y conseguir una buena cantidad de iconos para nuestros sistemas de necesitarlos.
También existe una visualización por categorías que nos permite interiorizarnos en alguna de ellas en particular, que puede estar asociada a nuestra necesidad.
Soy un zorrinito iconizado.
Una aproximación de best practices
Acabo de leer el artículo de IsoBar Front-end Code Standards & Best Practices. El artículo cubre de forma extensiva varias de las tecnologías utilizadas, con las sugerencias que esta empresa utiliza interamente. Cubre varios aspectos del uso de HTML (y algunas nuevas características de HTML5), CSS (y algunas nuevas características de CSS3), JavaScript, Performance, e integración cross-browser.
Personalmente no me siento de acuerdo con la totalidad de los items mencionados, pero creo que como punto de partida es muy bueno. Tienen una buena cantidad de referencias al por qué conviene hacer las cosas de la forma que ahí están explicadas, y muchas veces las razones son totalmente válidas. Muchas veces también se pesan pros y contras de cada aproximación, lo cual ayuda a tomar una decisión educada del proceso que elijamos seguir.
Soy un zorrinito front-end.
async y await
Continuando con mi serie de posts e investigación sobre lo que VS11 ofrece (Parte 1), quisiera tomar una aproximación separada. Si bien la exploración es interesante, es poco apropiada cuando uno quiere aprovechar el tiempo.
Es por eso que comencé con las referencias en MSDN sobre qué hay de nuevo en VS11, que seguiremos de a partes. Pero a la vez quiero cumplir con mi promesa, por lo cual, si comenzamos sobre qué hay de nuevo en el lenguaje C# (lo siento VB, lo siento C++, soy del bando de C#), nos encontramos con la excusa para cumplir lo prometido.
Esto, bien sabemos, no es algo propio de VS11, sino de C# 5.0, que va de la mano con VS11 y .NET 4.5. Como MSDN lo indica, una de las primeras características es la habilidad de construir fácilmente código asíncrono. “We have to go deeper…“
Cabe aclarar que ya existía la posibilidad de escribir código asíncrono. Los callbacks y el multithreading no es nada nuevo, aunque esto es ligeramente distinto, ya que simplifican un poco la idea y esconden el trabajo sucio. Sin duda se logrará que en el futuro mucha gente no sepa cómo funciona los métodos asíncronos por detrás pero esconder complejidad es un buen paso para permitir innovación.
Digamos que tenemos un programa que factoriza números grandes, porque logramos un trabajo de criptoanalista para el FBI. Nuestro método recibe un parámetro long y nos devuelve un ISet<long> con el conjunto de factores primos que conforman este número original. Dejando de lado la matemática, sabemos que este proceso toma un rato en ejecutarse y queremos que nuestro programa lo trate de forma asíncrona. ¿Cómo se haría este trabajo de la forma tradicional?
Básicamente deberíamos definir un método que sirva de callback. El callback (también llamado continuación) es un método que el thread que trabaja en la tarea llama cuando termina para avisar que su trabajo terminó. De esta forma, podemos preparar nuestra tarea, enviarla a ejecutar, hacer otras cosas en el intermedio y ejecutar código extra cuando la tarea termina, como por ejemplo, trabajar con los resultados.

(Ejemplo del código en Gist.GitHub: Async without async)
Esta aproximación tiene un problema muy claro: la complejidad. Estamos de acuerdo con que el código de FactorNumber debería estar separado en su propio método, pero la continuación de la llamada a FactorNumber y el resto de esa lógica son parte de una misma operación. El hecho de que estén separados en el código no es más que una obligación que debemos cumplir por las restricciones del framework para la instanciación de threads.
Las palabras clave async y await resuelven este problema.
Aquí podemos notar que la estructura del código ha cambiado un poco para dar soporte a esta característica. Por un lado, tuvimos que aislar el código que interactuará con métodos asíncronos, ya que los mismos deben devolver un tipo Task. Esto es porque devuelven un identificador de la tarea que está corriendo en background. En nuestro caso en particular, este será StartWork(), pero no estamos haciendo uso de su Task.
StartWork, siendo asíncrono, se ejecutará a la vez del resto del código, ya que no será bloqueante. Por tanto, el próximo Console.WriteLine se ejecutará, muy seguramente, al mismo tiempo que el procesamiento de StartWork ocurre. Dicho procesamiento hace una llamada bloqueante a FactorNumber, es decir, espera a que FactorNumber termine (lo cual nos permitió convertir la llamada en síncrona) y una vez que tenemos el resultado, se escribirá en consola. No era realmente necesario convertir esta llamada en síncrona de esa forma, una simple llamada a FactorNumber hubiera sido suficiente, pero de esta forma demostré que si bien el sistema espera por su respuesta suspendiendo el thread actual, sigue siendo asíncrono internamente. Eso significa que está ejecutando toda la tarea de callback que vimos antes de forma interna, y ahora nuestro código se lee fácilmente de arriba a abajo.
Confieso que debo trabajar un poco más en esto para no ensuciar tanto el código, pero por ahora parecería que el uso de las keywords exige modificar los valores de retorno y por tanto las llamadas a esos métodos deben ejecutarse de forma distinta. Eso no me agrada, porque inclina un poco la complejidad innecesaria para usar esto, pero sigue siendo una ventaja sobre la solución original.
Pasos para crear una buena estrategia
Ya que están pasando Battleship en el cine, me pareció muy apropiada la publicación de este link. De parte de MicroSiervos, Nick Berry de DataGenetics nos habla de un análisis estadístico para la estrategia de la Batalla Naval.
Atacando el problema primero en la forma más simple posible y luego mejorándola, él nos muestra cómo fácilmente se puede construir una inteligencia que, sin ser muy compleja, se acerca mucho a ser un buen competidos en un juego como este, y los números están ahí para probarlo.
Cabe destacar que esto parece ser algo muy común para la gente de DataGenetics y su blog, el cual comencé a seguir. Tienen muchos buenos análisis de varias cosas totalmente distintas. De hecho, hace poco me crucé con un post llamado Counterintuitive Conundrums, que básicamente son problemas con soluciones inesperadas (y nuevamente, los números están ahí para probarlo).
Soy un zorrinito analítico.
Javascript BDD
Jasmine no es el primer ni el último testing framework que existe, pero aquellos que vengan desde RSpec lo encontrarán muy parecido y fácil de usar. La misma página de Jasmine muestra una buena cantidad de ejemplos de cómo puede ser usado y de sus capacidades. Cabe destacar que no depende de ningún otro framework, pero juega bien con ellos (lo cual es interesante para realizar pruebas de UI aprovechando capacidades que jQuery, Dojo o Mootools nos puedan dar), y ni siquiera necesita del DOM estando cargado, lo que significa que de tener una aplicación compleja en JavaScript, podemos realizar pruebas unitarias respecto de nuestras propias librerías, independientemente de que se encuentren cargadas en un entorno o no.
Soy un zorrinito testeado.
Libros obligatorios de lectura sobre UX
Otra de las joyitas rescatadas de los foros de User Experience, es la pregunta sobre libros de lectura obligatoria de user experience y diseño de interfaces. El listado es más que completo y sorprendentemente vasto.
Este es el listado de libros, según la cantidad de votos de la respuesta que lo contiene (asumo que podríamos decir, más aceptado a menos aceptado):
Más que suficiente para entrenarnos en este aspecto.
Soy un zorrinito lector.
El por qué de practicar y ejercicios para hacerlo
Algún tiempo atrás JM nos había compartido un artículo sobre TDD Katas que básicamente explicaba qué son y por qué valen la pena. En dicho artículo Kata - The only way to learn TDD Peter Provost nos explica la mecánica básica tras la enseñanza de los Katas, una forma fácil de poner a práctica nuestros conocimientos teóricos.
No mucho tiempo después encontré el sitio de CodeKata, aplicado a una serie de metodologías más general, a aprender a desarrollar en distintas disciplinas o ámbitos. El artículo de Code Kata - Background tiene una buena introducción a lo que puede encontrarse en el resto del sitio.
¡A poner esas habilidades a practicar!
¿Y ahora qué hago?
Uno de los posts que causaron revuelo en las preguntas de Server Fault fue My server’s been hacked EMERGENCY (Hackearon mi server, EMERGENCIA), un post cuya respuesta fue totalmente inesperada para muchos y muy útil y planeada para situaciones tan sorpresa.
Me pareció tan útil que además de sólo linkear la pregunta y su respuesta, quise traducir la elongada explicación que Robert Moir, bajo el usuario de DJ Pon3 nos ha brindado. Esta traducción se basa en su respuesta pública, sin permiso explícito.
él nos explica cuáles son las medidas a tomar en un caso drástico como este, y muchas formas de reducir el riesgo de esto ocurriendo en el futuro. La explicación es larga pero muy clara y muy explícita sobre cada aspecto involucrado en la seguridad de un sistema.
A continuación, su respuesta:
Es difícil dar un consejo específico desde lo que has posteado aquí, pero tengo algunos consejos genéricos basados en un post que escribí mucho tiempo atrás cuando todavía podía molestarme en bloggear.
Primero que nada, no hay “arreglos rápidos” más que recuperar tu sistema de una copia de seguridad tomada anteriormente a la intrusión, y esto tiene al menos dos problemas.
Esta pregunta sigue siendo hecha repetidamente por las víctimas de los hackers que entran en su servidor web. Las respuestas cambian raramente, pero la gente sigue haciendo la misma pregunta. No estoy seguro de por qué. Quizá a la gente no le gustan las respuestas que han visto buscando por ayuda, o no pueden encontrar a alguien que confíen que les de consejo. O quizá la gente lee una respuesta a esta pregunta y se concentra demasiado en el 5% de por qué su caso es especial y diferente a las respuestas que pueden encontrar online y se pierden el 95% de las preguntas y respuestas en donde su caso es suficientemente cercano a ser el mismo al que leyeron online.
Eso me trae a la primera pepita de información. Realmente aprecio que eres un copo de nieve único muy especial. Aprecio que tu sitio también lo sea, ya que es un reflejo de tí y tu negocio, o en última instancia, tu trabajo duro en nombre de un empleador. Pero para alguien desde afuera mirando hacia adentro, ya sea una persona de seguridad de computadoras mirando al problema para tratar de ayudarte o incluso para el mismo atacante, es muy probable que tu problema sea al menos 95% idéntico a cualquier otro caso que ellos hayan visto.
No te tomes el ataque de forma personal, y no tomes las recomendaciones que siguen aquí y que te da otra gente de forma personal. Si estás leyendo esto inmediatamente luego de convertirte en la víctima de un hack en un website, entonces realmente lo siento mucho, y espero que puedas encontrar algo útil aquí, pero este no es el momento para dejar que tu ego se interponga en el camino de lo que tienes que hacer.
No entres en pánico. Absolutamente no actúes apurado, y absolutamente no intentes actuar como si las cosas nunca hubieran ocurrido y no tuvieras que hacer nada.
Primero: comprender que el desastre ya ocurrió. Este no es el momento para la negación; es el momento para aceptar lo que pasó, para ser realista al respecto, y para tomar pasos para controlar las consecuencias del impacto.
Algunos de estos pasos van a doler, y (a menos que tu website tenga una copia de mis datos), realmente no me importa si ignoras todos o algunos de estos pasos, pero hacerlos hará las cosas mejores al final. La medicina puede saber horrible pero a veces hay que quitarle importancia a eso si queremos que la cura funcione.
Detén el problema de volverse peor de lo que ya es:
¿Todavía dudas si tomar este último paso? Lo entiendo, de verdad. Pero míralo de esta manera:
En algunos lugares podrías tener un requerimiento legal de informar a las autoridades y/o las víctimas de este tipo de brecha de privacidad. Por mucho que tus clientes se molesten teniéndote contándoles sobre un problema, estarían mucho más enojados si no les contaras, y sólo se enterarían por cuenta propia cuando alguien les cobre U$S 8.000 dólares en bienes usando los datos de tajeta de crédito que obtuvieron de tu sitio.
¿Recuerdas lo que dije antes? Lo malo ya ocurrió. La única pregunta ahora es qué tan bien vas a lidiar con ello.
En situaciones como esta el problema es que ya no tienes control de ese sistema. Ya no es tu computadora.
La única forma de estar seguro de que tienes control del sistema es reconstruir el sistema. Si bien hay mucho valor en encontrar y arreglar el exploit usado para entrar en el sistema, no puedes estar seguro sobre qué más ha ocurrido en el sistema una vez que los intrusos tomaron control (de hecho, se sabe de hackers que reclutan sistemas a una botnet para solucionar los exploits que ellos mismos usaron, para salvaguardar “su” computadora de otros hackers, y también instalar sus rootkits).
Nadie quiere estar offline más de lo que tienen que estarlo. Eso está claro. Si este website es un mecanismo de generación de ganancias, entonces la presión para traerlo de vuelta online rápidamente va a ser intensa. Incluso si solo la cosa en juego es la reputación tuya / de tu compañía, esto va a generar todavía más presión para poner las cosas funcionando de vuelta rápidamente.
Sin embargo, no cedas a la tentación de volver online demasiado rápido. En lugar de eso, muévete tan rápido como puedas para comprender qué causó el problema y para solucionarlo antes de volver online, de de lo contrario muy sgeuramente caerás víctima de una intrusión nuevamente, y recuerda, “ser hackeado una vez puede ser clasificado como mala fortuna; ser hackeado de vuelta inmediatamente luego se ve como descuido” (con mis disculpas a Oscar Wilde).
La primer cosa que debes comprender es que la seguridad es un proceso que debes aplicar por todo el ciclo de vida de diseño, instalación y mantenimiento en un sistema que tiene acceso a internet, no algo que puedes pegar como un par de capas sobre tu código luego como pintura barata. Para estar seguro apropiadamente, un servicio y una aplicación deben estar diseñados desde el comienzo con esto en mente como uno de los objetivos principales del proyecto. Me doy cuenta que es aburrido y que ya has escuchado todo esto antes, y que “no te das cuenta de la presión, hombre” de tener tu servicio web 2.0 beta (beta) en estado beta en la web, pero el hecho es que esto se sigue repitiendo porque fue verdad la primera vez que fue dicho y todavía no se ha convertido en mentira.
No puedes eliminar el riesgo. No deberías siquiera tratar de hacerlo. Lo que deberías hacer, sin embargo, es comprender cuáles riesgos de seguridad son importantes para tí, y comprender cómo manejar y reducir tanto el impacto del riesgo y la probabilidad de que el riesgo ocurra.
Por ejemplo:
Si decides que el “riesgo” de que el piso bajo de tu casa se inunde es alto, pero no lo suficientemente alto como para mudarte por las dudas, deberías al menos mover las reliquias familiares irremplazables al piso superior. ¿Verdad?
Probablemente no dejé cabo suelo entre las cosas que otros consideran importantes, pero los pasos de arriba deberían al menos ayudarte a comenzar a ordenar las cosas si tienes la mala suerte de convertirte una víctima de los hackers.
Sobre todo: no entres en pánico. Piensa antes de actuar. Actúa firmemente una vez que hayas tomado una decisión, y deja un comentario debajo si tienes algo que agregar a mi listado de pasos.
Soy un zorrinito hackeado (gracias Julián!)
Desmintiendo si las URLs acortadas afectan o no la confianza del usuario
Hoy voy a dejar un caso de una pregunta abierta, nuevamente, originada en los foros de User Experience. La pregunta es: _ ¿Los usuarios confían en URLs acortadas?_
Siempre se supo, y es un concepto fundamenta del SEO, que las URLs deben ser lo suficientemente amigables como para significar algo que sea relevante al contenido de ese recurso. Por otro lado, la teoría debajo de REST y la web semántica nos indican que las URLs (o URIs) deberían ser identificadores únicos de un recurso en particular, de forma que, de alguna manera, su identificador tendría cierta relación con su contenido.
Sin embargo, y aún así, parece no haber estudios definitivos realizados sobre lo que los usuarios en general opinan. Nosotros hemos experimentado confianza o desconfianza de estas URLs dependiendo de quién vienen, o en dónde las encontramos. Básicamente, dependería del contexto.
Sin embargo, ninguna de las respuestas tiene algún estudio que demuestre la fiabilidad de su fuente, por lo que yo ya comencé una pregunta que pide por ellos, pero veremos qué ocurre. Esta pregunta sigue abierta e invito a los lectores a aportar cualquier información que tengan al respecto.
Soy un zorrinito acortado.
Comenzando a explorar lo que la beta nos ofrece.
Comencé como un proceso de autocapacitación mi investigación personal de las características que Visual Studio 11, todavía en Beta, nos ofrece. Pretendo documentar mi experiencia personal porque si bien no va a ser una buena indicación de cómo es el producto, puede que detecte muchos pequeños problemitas o cosas que estarían buenos tener en cuenta, al menos prepararse para ellos. Conociendo mi suerte, estoy seguro de que algo voy a romper.
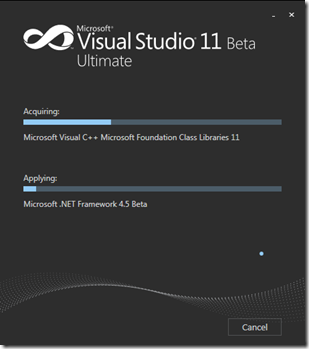 { :align-left }
{ :align-left }
Lo primero que tengo que comentar es la instalación. La interfaz está mucho más refinada, pero más allá de eso, es un poco más oscura en el sentido en que no tenemos mucha información sobre qué está pasando. No he tenido problemas con la instalación, pero imagino que debe ser más complicado de hacer troubleshooting si ocurriera algún error. Por último, la instalación toma su buen par de horas, quizá extendiéndose hasta cuatro o cinco. Si tiene que bajar los updates de internet, es lo suficientemente inteligente como para hacerlo en paralelo mientras otra cosa se instala, así que tener una conexión pobre no debería ser un problema a menos que fuera muy acotada.
Mi instalación terminó sin problemas excepcionales. Una característica rara que me ocurrió en una de las dos máquinas que la instalé (solo en una) es sobre un paquete que debe continuar la instalación. Como varias de las instalaciones de VS, a veces es requerido un reinicio hasta que se pueda continuar la instalación. La forma en la que el instalador se asegura continuar luego es poniendo una entrada en el registro para volver a correr la próxima vez. Resulta que en mi caso, ese ejecutable se inició pero nunca se quitó del registro. Nunca supe si ejecutó correctamente o no porque ese ejecutable en particular parece no tener interfaz. Tras cada reinicio que yo hacía, el ejecutable volvía a pedirme permiso (ya que es un archivo bajado de internet).
Ese se encuentra aquí, algo que futuros visitantes pueden encontrar muy útil para diagonsticar problemas:
"C:\ProgramData\Package Cache\{a3c0442e-f8f7-4089-ac77-1e0c50901f63}\vs_ultimate.exe" /burn.log.append "C:\Users\_<User>_\AppData\Local\Temp\dd_vs_ultimate_<timestamp>.log" /uninstall /quiet -burn.related.upgrade
Por el comando que ejecuta y deja en el archivo de log, parecería ser un servicio de updates y de rollout de nuevas funcionalidades agregadas. Si estoy en lo correcto, no deberían preocuparse ya que VS tiene su propia plataforma de updates. Lo que yo hice es simplemente quitar eso de mi inicio. No he visto complicaciones hasta ahora.
Lo primero que voy a probar es hacer algo parecido a mis tareas diarias.
Mi primer sorpresa es la elección de colores que tuvieron con el entorno. En general, todo grisáceo y de colores muy uniformes. Es fácil ver el texto pero no lo es tanto como el contraste que proponía el blanco sobre azul de la versión anterior. Es difícil distinguir las ventanas sobre el fondo, especialmente si no tienen contenido. Cada tanto los mensajes de diálogo pierden ese estilo y vuelven al estilo normal que tienen las ventanas de Windows, dejando ese feo sabor del cual todos se quejan de la suite Adobe, en donde el programa realmente desentona con el entorno en el que está corriendo.
Recordemos nuevamente que está pensado también para Windows 8, con lo que mi apreciación podría ser equivocada, pero no lo he probado aún. Esa es otra historia y probablemente otra serie de posts.
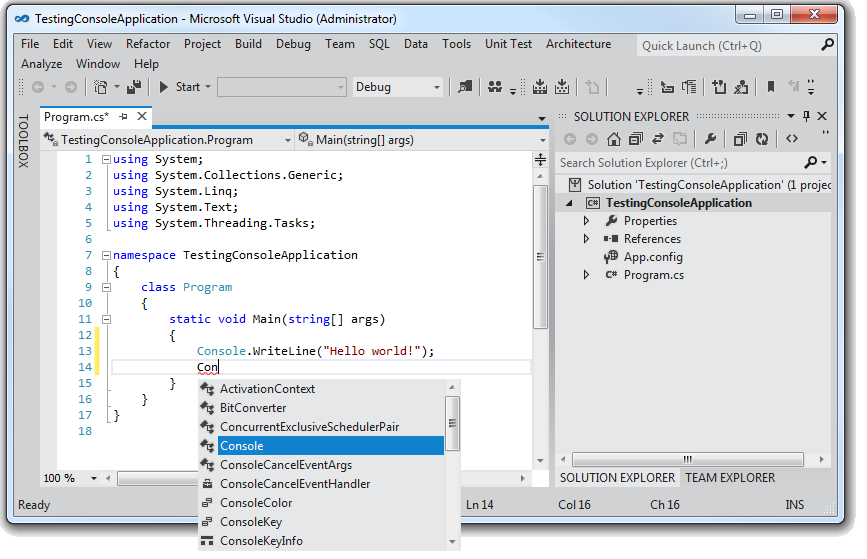
Como pueden ver en el screenshot que tomé, también optaron por eliminar los colores de los menúes contextuales, específicamente les muestro el de Intellisense, el cual me parece una pésima decisión. La habilidad de distinguir propiedades, métodos, clases, enumerados y campos por color a simple vista era una bendición. Las selecciones de arriba siguen siendo dropdowns anque parezcan desaparecidos, y los íconos más el gris claro/gris oscuro/negro de toda la sección derecha lo hace difícil de acostumbrarse. Creo entender la intención: esta pantalla nos concentra, sin duda, en el código, y eso definitivamente debería ocurrir.
El entorno completo parecer ser más rápido y responsivo, sospecho que estará utilizando la misma tecnología de async que el nuevo framework ofrece. ¿Recuerdan el cuadro de diálogo de Add Reference, que fácilmente detenía todo unos minutos hasta recuperar el listado de assemblies? Sigue tardando, pero ya no significa un problema, el entorno sigue respondiendo como si nada estuviera ocurriendo de fondo.
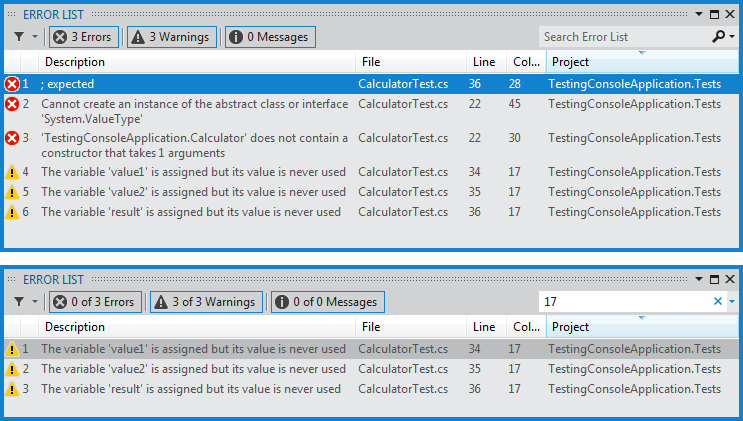
Una muy buena adición que encontré es la capacidad de filtrar errores desde el listado de errores de compilación. Esto nos permite dar un paso adelante, cuando ya estamos acostumbrados a determinados errores causando otros, pudiendo concentrar nuestro esfuerzo en solucionar esos primero. Como pueden ver además, el filtro funciona para cualquier campo, lo cual resulta totalmente natural.
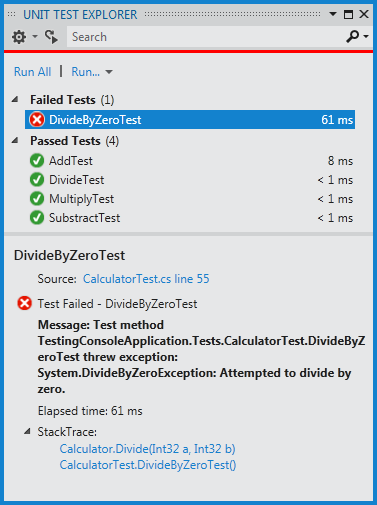
Desafortunadamente, parece que esta característica no se comporta de forma consistente en todas la ventanas. Otra que me interesa que vean es la ventana Unit Test Explorer, otra que estaremos viendo muy seguido, más todavía si trabajamos con TDD. En este caso la búsqueda sólo funciona con el nombre de las pruebas y uno debe presionar enter para aceptar la búsqueda, cuando en la anterior ya con sólo filtrar podíamos ver nuestro filtro aplicarse.
Esta ventana, sin embargo, tuvo un rediseño visual algo importante y me agrada el cambio. En las versiones anteriores los detalles de una prueba se encontraban separados de la prueba en sí, esto hará mucho más fácil poder ver qué pasa con cada una de las pruebas, y asumo que su output también aparecerá aquí.
Parece que otra característica que tampoco nos dejará muy contentos es algo que estaba siendo muy aclamado. Cualquiera que reconozca la frase “Expression cannot contain lambda expressions” sabe de qué estoy hablando. Así es, esa frase sigue presente y nos sigue molestando aún en esta nueva versión. Por favor, espero que la versión final del IDE agregue esto porque es una funcionalidad que puede salvar horas y horas de desarrollo.
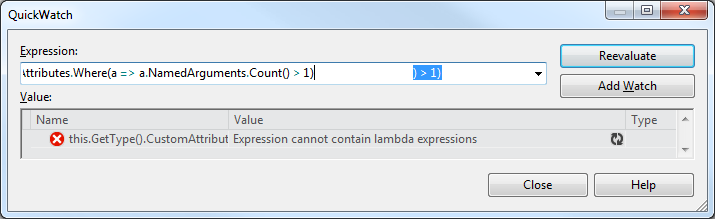
Desafortunadamente alguien ha decidido que agregar coloreado al texto que tipeamos ahí fue más importante, y terminamos con una versión algo buggeada de texto formateado (como pueden ver en la imagen anterior, ambas decepciones juntas). No es realmente nada tan terrible como algo que no funcione, pero muchos queremos poder efectuar un .Where() para no tener que pasar por más de 200 elementos en un enumerable.
En otra de mis pruebas descubrí que existe algo llamado Parallel Watch, que básicamente es una ventana de watch que nos permite ver valores de una misma variable a lo largo de distintos threads. Supongo que esto puede volverse confuso ya que distintas intancias de una misma variable son en realidad distintas variables e instancias no-thread safe son en realidad la misma variable. Eso o yo me estoy perdiendo algo del concepto de trabajar en paralelo. (Si algún lector tiene algo que aportar, es bienvenido.)
Dispuse la siguiente prueba para verificar su funcionalidad, y como sorpresa extra, encontré que puedo editar el código mientras está ejecutando, algo que anteriormente sólo ocurría en determinados casos. Me trajo un poco de satisfacción (aunque no tanto como me habría dado poder usar lamdbas en el quick watch.)
Desafortunadamente mi prueba no resultó muy exitosa, ya que al elegir una ventana de watch para poder ver, el siguiente mensaje se hace presente (les dije que algo iba a romper):
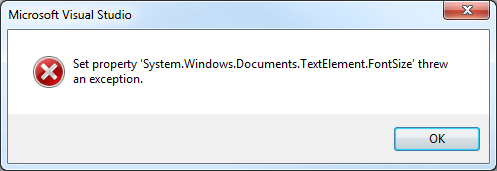
Creo que de todos momentos puedo estar en el camino equivocado, ya que en la ventana de Parallel Tasks nada aparecía. Seguramente tenga algo que ver con la nueva característica de async tasks de .NET 4.5.
Es un muy buen punto de partida para retomar mi investigación, ya que mi tiempo se acabó por hoy.
Comparando funcionalidades desde su pantalla
De parte de Cesar D’Onofrio (¡gracias!) me llega este útil link llamado, simplemente, Mobile Patterns. El sitio es, sin mucho más, una galería de interfaces mobile para distintas categorías de pantalla. En este caso, se trata de pantallas de iPhone, pero los conceptos van más allá del teléfono en el cual se vean. La distribución de la información y la utilización de imágenes no tiene realmente que ver con una marca de dispositivos.
Esta recopilación en particular fue puesta junta por Mari Sheilbley, la diseñadora líder de Foursquare, quien a la vez postea varios diseños interesantes en su blog personal a modo de portfolio.
Soy un zorrinito diseñado.
Buenas prácticas para formularios web
Otra de las preguntas de los foros de User Experience, bajo el título de Have I missed anything from my list of web form best practices?, consiguió una muy buena recopilación de consejos de buenas práctica sobre interfaces de formularios y UI / UX. Si van a mirarlo, miren todas las respuestas, ya que la pregunta principal no ha sido actualizada para recopilar completamente todo lo que han sugerido.
Cabe mencionar que muchas de estas respuestas corresponden a sugerencias e incluso a patrones explicados en el libro Web Application Design Patterns, de Pawan Vora, el cual es una buena referencia para buenas prácticas generales sobre la web. Sin duda habrá mejores referencias, pero es de las que he leído hasta el momento. Los invito a compartir libros o referencias recopilatorias de buenas prácticas.
Soy un zorrinito de buenas prácticas.
UPDATE: Lisandro nos dejó en los comentarios un link sobre la forma correcta de alinear labels, y otro sobre las ventajas de campos de texto unificados. ¡Gracias!
¡Chuck Norris al rescate!
Hace poco me crucé con un proyecto que utilizaba RoundhousE y mi curiosidad me llevó a ver qué era. Me encontré con que es un sistema de migraciones de bases de datos muy conocido para .NET, particularmente para SQL Server, pero también soporta MySQL, Oracle, PostgreSQL, e incluso SQLite.
Cabe aclarar que cuando menciono el concepto de migración, no me refiero a la actividad de mover datos de un esquema a otro, sino al hecho de convertir un esquema a otro (que, en el fondo, no es tan distinto). Este concepto de migración y versionamiento de bases de datos permite tener controlados los cambios que deben aplicarse al momento de cambiar la versión de una aplicación, y su capacidad de aplicar o revertir cambios hace que ya no deba recordarse de forma mental en qué estado nuestra base y cómo llevarla al estado nuevo.
RoundhousE puede encontrarse en su repositorio de GitHub (bajo el usuario chucknorris, ¡ja!), o en su sitio http://projectroundhouse.org, que ahora lleva a Google Code.
Soy un zorrinito migrado.
Una imagen tiene menos de mil copos de cereal
De parte de Design.org me llega una ingeniosa representación infográfica de Ed Lea, quién plasmó diferentes conceptos de diseño e interfaz en ejemplos visuales con un plato de cereal.
El post pueden verlo en The Difference Between UX and UI: Subtleties Explained in Cereal.
Me gustaría incluso jugar a extender la analogía (y necesito ayuda de ustedes, lectores, para eso). Estas son algunas ideas que se me ocurrieron:
¿Qué más se les ocurre?
Soy un zorrinito cerealero.
Imágenes en QR Codes
Russ Cox publicó hace no mucho un artículo sobre lo que él denomina QArt Codes, que son QR Codes con una imagen en ellos.
él comienza contando sobre una anécdota de varias empresas que para marketing generaron QR codes que tenían logos o imágenes en ellos. Sin embargo, estos QR codes eran incorrectos y sólo funcionaban porque hacían uso de la capacidad de corrección de errores. él se propuso entonces hacer un sistema que pudiera incluir una imagen en un QR code con un formato totalmente correcto. En dicho artículo, nos explica cómo es el funcionamiento y formato de los QR codes y cómo esto se puede utilizar para la inclusión de una imagen.
El sistema resultado de dicha investigación se llama QR y su código está disponible en Google Code.
Cabe destacar que el análisis no es extensivo de todo lo que un QR Code debe incluir. Por mencionar algo extra, en un post de Google Plus él nos cuenta que debe incluir ciertos píxeles de margen para que todos los lectores puedan identificarlo (cosa que Facebook no tuvo en cuenta a la hora de pintar un QR code en su techo, pero Phillips & Company sí).
Soy un zorrinito cuadrado.
El Camino del Samurai
Terminé con mi lectura actual, en este caso, el Hagakure. Hagakure Kikigaki (葉隠聞書) es el libro de origen japonés que habla, desde uno de los miembros del clan Nabeshima, sobre cuál es el camino del verdadero Samurai, basándose en una recopilación de historias y anécdotas que llegaron a Yanamoto Tsunetomo, siendo él mismo un samurai.

El libro en sí no tiene una estructura particularmente fácil de seguir, pero de alguna forma deja leer entre líneas cuál es el mensaje del camino del Samurai. En muchos punto las anécdotas recavadas se contradicen una a otra, y no tiene demasiado contexto sobre ellas. Esto significa que estaríamos mejor leyendo una versión anotada, seguramente con aclaraciones culturales e históricas que provean ese contexto necesario.
Yo comentí la equivocación de leer una versión que encontré libre en internet, específicamente una que ofrece el sitio de JudoInfo en su sección de descargas. Esta versión en particular, si bien está formateada de una forma aceptable, es una muy mala traducción al inglés del texto original, y en muchos puntos es simplemente incomprensible. Como extra, se convierte en una lectura bastante cansadora, por las gramáticas raras, la mala utilización de ciertas palabras y la repitición extrema de otras, la poca separación de conceptos y los textos largos de hombres matando a otros sin razones claras. Nuevamente, todo esto puede solucionarse con una buena traducción y una buena edición.
Me agrada mucho lo que el libro tiene que decir sobre el camino del samurai. Yo sabía que el código de honor era muy estricto, pero no había imaginado que llegaba a este punto, y de hecho, si uno toma la enseñanza básica de vivir sólo el día del presente buscando ser útil a su amo, el código de honor fácilmente se desprende de esas enseñanzas. Cometiendo el pecado de sobre-simplificar el significado del camino del Samurai, el hecho de considerar la muerte como algo inminente y determinarse a obtener resultados inmediatos es una forma de vida que estos hombres seguían.
Lo encuentro como una lectura muy interesante, y esperaba que dejara en mí una marca especial. No fue tan profunda por la mala experiencia de la lectura, pero el principio fundamental ha quedado en mi persona. Ciertamente, es una lectura que recomendaría.
Le doy 4 de 5 zorrinitos.
Soy un zorrinito samurai.
¡Que alguien pague lo que nunca se pagó!
Como protesta a todos los clientes que no pagan a los trabajadores freelancers, específicamente del área del software, la gente de Freelancers Union presenta La Factura Más Grande del Mundo, en donde cada trabajador no pagado deja su línea para que sea añadida a la factura. (Y yo me enteré gracias a la gente de Clients From Hell.)
El objetivo de esta iniciativa es despertar los intereses de aquellos que puedan legislar regulaciones para que quienes sufren día a día esto tengan un respaldo legal sobre el cual apoyarse. Hoy, según parece, es un poco difusa la situación y los freelancers no son tan tomados en serio.
Soy un zorrinito caro.
Posts being featured in MakingSense's blog
Noticia rápida: algunos de los posts de aquí pueden aparecer de tanto en tanto en el blog de MakingSense. Para quien no lo sepa, es la empresa en donde trabajo, y donde de hecho ya hay algunos posts míos y un webinar. Si están interesados en el negocio de IT desde un punto de vista no tan técnico como este blog, y más orientado a tendencias y management, les recomiendo totalmente que se pasen por allá.
Gracias y saludos.
Soy un zorrinito publicitario.
Quick notice: some of the posts from here may appear from time to time in MakingSense’s blog. For those that do not know, it is the company which I work for, and where I had already had a couple of posts and a webinar. If you’re interested in IT business from a point of view not so technical as this blog, and more oriented to tendencies and management, I totally suggest you give that blog a look.
Thanks and best wishes.
I’m an advertising little skunk.
Desafíos de hacking y seguridad
Fue exactamente hace un par de días cuando hablé de Explot Exercises, pero más de cuatro años (wow) cuando hablé de HackThisSite, pero ahora sí tengo un listado grande de sitios que permiten hacer pruebas de seguridad y aprender online. Basado en esta pregunta en IT Security, este es un buen listado de sitios para practicar seguridad o participar de desafíos. Cada uno tiene su propia modalidad, pero les dejo como ejercicio a ustedes elegir la más apropiada:
Soy un zorrinito inseguro.
Recursos de UX y UI para Metro
Sabemos que Metro es un nuevo estilo, una aproximación completamente distinta cuando se trata de interfaces. Como nuevo, muchos nosotros podemos encontrarnos confundidos al momento de querer aplicarlo. Es para eso que es necesaria alguna guía, alguna indicación que nos indicará si estamos en el camino correcto o no. Gracias a una pregunta en los foros de User Experience encontré estos links, que pueden ser de mucha utilidad:`
Soy un zorrinito metro.
Un documental sobre Raymond Kurzweil y su pensamiento
This is the story of the destiny of the human-machine civilization.
A destiny we have come to refer to as the Singularity.
— Ray Kurzweil
Transcendent Man es el nombre de un documental hecho en el 2009 sobre Raymond Kurzweil y su filosofía futurista/transhumanista. Ahora hablaré sobre eso, pero primero sobre el documental en sí.
Como documental, esta hora y media realmente no es demasiado útil. Tiene una buena introducción para quien no sepa nada de Kurzweil (o su familia o su historia) ni del concepto de la Singularidad. Nuevamente, sólo en ese caso, porque a modo de introducción genera la idea necesaria, pero para alguien que quiere informarse al respecto, este documental no es sólo tendencioso y mal fundamentado, sino que es, planamente, aburrido. Como película es realmente poco dinámico, lento, la estructura de la información está bastante poco definida y la música e intercalación de infografías es pobre y poco cautivante.
Creo que soy muy duro con este documental porque este es un tema que realmente me apasiona. En poco voy a comenzar a seguir de cerca la filosofía de Kurzweil, y tengo en mi listado de próximos libros a leer los suyos. Quiero realmente saber lo que piensa y por qué lo piensa, ya que el documental lo deja presentado como un loco que tuvo la suerte de no equivocarse antes, o como un visionario que tiene sus razones y absolutamente nadie comprende. Yo creo que la situación real es mucho más profunda, y que hay muchos más argumentos a favor y encontra de los presentados, con lo que me decepciona la cantidad de información presentada en Transcendent Man.
Los primeros veinte minutos son realmente lo que esperaba: un comienzo épico y, si bien tendencioso, muy claro en lo que estamos viendo. Se trata de alguien que solo por lo que dice el mundo científico tiembla, porque siempre dijo locuras pero siempre tuvo razón. Luego de esos veinte minutos, el documental trata de varios pilares del avance transhumanista, como el avance en la investigación genética, la robótica y la nanotecnología. Creo también que no son las palabras más apropiadas para definir a la Singularidad, pero ese es otro tema que no discutiré aquí. Habla también de la historia personal de Ray, su familia y su vida actual, y su visión de la muerte y la inmortalidad.
En fin, no la recomendaría como fuente de información, y ciertamente no la recomendaría como película. Aún así, la calificaría de interesante. Le doy 2 de 5 zorrinitos.
Soy un zorrinito singular.
Exploit this!
Parecido a los laboratorios de seguridad, hace poco me encontré con un sitio llamado Exploit Exercises, un sitio web que dispone de guías y máquinas virtuales que podemos bajar para probar y aprender sobre escalado de privilegios y corrupción de memoria en entornos Linux.
Soy un zorrinito inseguro.
Are you sure you want to cancel explosion? [Ok] [Cancel]
Encontré hace poco este link y realmente quería compartirlo. El artículo, en inglés, se titula 6 Disasters caused by Poorly Designed User Interfaces, y si bien el artículo proviene de Cracked.com, – que bien sabemos no se trata de una fuente periodística – da muy buenos ejemplos de cómo una interfaz de usuario mal diseñada realmente tienen consecuencias.
Soy un zorrinito mal diseñado.
I'm sorry Dave, I'm afraid I can't do that.
En MicroSiervos publicaron un artículo sobre un nuevo método que está siendo investigado en DARPA, llamado Autenticación Cognoscitiva. Según lo dicen ellos también, el sistema podría identificarnos por “tu forma de pensar”.
Cabe aclarar que en el paper real, al método se lo denomina Active Authentication y parecería no estar relacionado mucho con las huellas cognoscitivas sino más con otra información biométrica, pero realmente sí lo está. Varios de los elementos que se utilizarían para identificar a una persona, incluso durante el transcurso del uso de una aplicación, serían cosas como:
Como bien dijeron los chicos de MicroSiervos, el objetivo de este estudio es eliminar las contraseñas y utilizar un método más cercano a la identificación de una persona real, basado en elementos que la distinguen de los demás. No conozco qué tan distinguible sea una persona por estos aspectos (o qué otros detalles de estos aspectos están involucrados), pero sin duda es un acercamiento interesante. Habría que analizar en qué forma se trabajan casos excepcionales, como por ejemplo, qué ocurriría si me quiebro un brazo y ya no tecleo de la misma forma, o si tengo un estado emocional alterado en base a un evento de mi vida.
Si alguien está interesado en leer el paper, está disponible públicamente en el sitio de Federal Business Opportunities.
Soy un zorrinito autenticado.
Unit testing para web frontends
Hay un artículo en particular de Steve Sanderson llamado Using HtmlUnit on .NET Headless browser automation que indaga sobre los beneficios de utilizar esa librería para simular un browser completamente funcional que podemos utilizar para nuestro unit testing, y, por qué no, para automatizar tareas en un browser. La idea principal es poder ejecutar tareas como si de un browser se tratara, e inspeccionar los elementos de la página e interactuar con ellos.
Cabe destacar que HtmlUnit en realidad está hecho para Java, pero puede portarse a .NET de la forma que Steve Anderson menciona. He leído por ahí que es un poco lento, pero creo que su API agrega la suficiente simpleza como para trabajar fácilmente por él.
Soy un zorrinito automatizado.
Hace unos días me llegó un email sobre Udacity (del cual yo ya había hablado) avisando que hay nuevas clases disponibles allí.
Ahora el listado es:
En fin, si a alguno le interesa, voy a estar por ahí.
Soy un zorrinito en aprendizaje.
Y ¿por qué no la cambiamos?
Un comentario que mucho tiempo hemos visto discutido por ahí es por qué todavía usamos la figura del floppy disk para indicar la acción de guardar, cuando hace tiempo que estos discos se dejaron de usar. Peor aún, hay gente que ni siquiera sabe qué son.
La primera respuesta de ese link menciona que la imagen del floppy disk es un modismo, no una metáfora. El modismo (idiom) es, para resumir, un simbolismo no directamente asociado con el significado. En algún momento fue un símbolo, asociado a cuando persistíamos nuestros datos en estos diskettes, pero ahora es algo totalmente fuera de contexto.
En los foros de Graphic Design también se habló de este tema y se están proponiendo nuevas alternativas. En los foros de UX están de acuerdo con que cambiar los íconos generaría más problemas de los que realmente resolvería, pero está claro que si la persistencia se inventara hoy, el ícono sería distinto.
¿Quizá el nuevo paso es inventar algo más abstracto, que sea válido para cualquier era de almacenamiento?
Soy un zorrinito almacenado.
Seleccionar un elemento cualquiera de un conjunto
Otro de mis pequeños snippets, este es útil para unit testing.
Cuando tienen un repositorio de datos que en realidad es mockup, y algún objeto tiene que estar pre-populado, podrían querer que los tests sean independientes de los datos. Y con esto me refiero a ser independiente de los valores que esos objetos tienen. Para esos casos, utilizar un objeto al azar de un conjunto de objetos sería una buena aproximación. No es tan determinista, pero eso es algo deseable, e incluso más cerca a probar la aplicación real.
Para obtener un objeto al azar, este pequeño snippet ayuda:
Accesible para uno, secreto para todos
PrivateSky no es ni el primer ni el último intento de un servicio de seguridad en la nube. Lo que los distingue es que, según dicen, ni ellos mismos tienen acceso a los datos que nosotros guardamos, y que ni al momento de que el gobierno les requiera los datos, ellos los darían. (O eso dice su CEO.)
Alguien en IT Security preguntó: ¿Cómo puede PrivateSky no tener acceso a nuestros datos?, y la respuesta más extensa la brinda, con lujo de detalles y tecnicismos, Brian Spector, el CEO de CertiVox. Debo admitir que no estuve al nivel de entenderla completamente, pero me queda claro cuál fue la estrategia general, y sé que en este tipo de cosas no se le puede mentir a la comunidad, al menos no en ese foro en particular.
En general, lo que ellos intentan es hacer un sistema de encriptación basado en identidad, en donde algo del lado del cliente siempre permita decriptar, algo que ellos en ningún momento reciben como clave completa, y en donde la forma de alterar esto generaría la destrucción de las demás partes de la clave. Esto significa, que sólo el usuario en acuerdo con el sistema puede cambiar la clave a otro valor, y que cualquier intento de hacerlo fuera de esa identidad básicamente perdería las claves que se pueden usar para decriptar los datos.
Por ahí preguntaron también cómo harían para evitar pedidos legales de información. Ellos se basado en un vacío legal que les permitiría entregar los datos encriptados, y defenderse diciendo que no tienen forma de decriptarlos, dejando la información segura de forma total. (Esto es, claro, excepto que la entidad gubernamental tenga los métodos apropiados para quebrar la encriptación, cosa por la que se apuesta que no ocurra.)
A pesar de lo transparente que se busca ser en esto, Brian Spector ha sido bastante cerrado en cuanto a la información de seguridad que dejó ver del sitio web.
Aún así, parece una aproximación muy novedosa.
Soy un zorrinito privado.
Post procesamiento vs. preprocesamiento
Para los que conocemos y usamos Less o sus variantes, nos alegraríamos mucho de saber que CSS pueda agregar capacidades similares. A pesar de que gran parte de la comunidad esté en desacuerdo (¡Gracias, AM!), yo creo que serían útiles, por varias razones. (Invito a discutir a quién piense distinto.)
Todo esto venía a los links que me encontré, relativamente novedosos: Calc() para CSS, un operador que calcula valores en base a los argumentos que se le pasen. Creo que este pedacito de código lo paga todo:
#foo {
width: calc(50% - 100px);
}
<div id="foo">Always 100 pixels less than half the available area</div>
Por otro lado, Scoped Styles, algo que sólo veo como utilidad al momento de permitir usuarios escribir su propio CSS (apropiado para SaaS en donde los usuarios tengan su propio espacio). No soy muy fanático de esta funcionalidad, pero reconozco que resuelve un problema existente.
Soy un zorrinito dinámico.
La razón detrás de las URLs raras...
Sabemos que el nombre no es más que un nombre y que no importa cuál sea el servidor actual en donde se están alojando los datos, pero parecería que es una práctica común de muchos sitios grandes (léase: Facebook, Twitter, Google, etc.) hacer referencia a muchos de sus recursos en dominios externos. Por ejemplo, las imágenes de Facebook se encuentran alojadas debajo de http://static.ak.fbcdn.net/ y no debajo de http://www.facebook.com/, ni siquiera debajo de http://imgs.facebook.com/. ¿Por qué?
Alguien ya hizo esa pregunta y la respuesta fue nueva para mí: hay una limitación en varios browsers (y hastas donde yo sabía, algunos sistemas operativos) que previene hacer más de dos, tres o cuatro conexiones simultáneas a un mismo hostname. De hecho, es parte de la especificación HTTP 1.1 (parece que cumplir el estándar no siempre está tan bueno, ¿no?). Ahora, si notaron, la limitación es por hostname, ¿por qué entonces utilizar distintos dominios? La razón es evitar cookies que pueden estar yendo y volviendo en cada uno de los pedidos, y para evitar eso, se puede usar un dominio extra que nunca devuelva cookies. De esa forma, sitios grandes como estos se ahorran mucho bandwidth.
UPDATE: Gracias a Exos, que claramente estaba más informado que yo en este tema, las limitaciones exactas son de tres conexiones por cada dominio y cinco para cada IP. Los distintos dominios/subdominios ayudan a utilizar CDNs para distribución de contenido con mayor velocidad. Exos está en desacuerdo (y demuestra por qué, miren los comentarios) con que las cookies sean una gran carga respecto del bandwidth. Entonces el por qué de los dominios vs. subdominios queda en duda, pero suponemos que debe estar relacionado con políticas de administración interna de cada empresa.
Soy un zorrinito performante.
Y mi sobrada misericordia
Me acabo de dar cuenta, de casualidad, que los estilos del blog no estaban funcionando en IE8-, debido a la presencia de elementos de HTML5, que, para ser breve, rompían todo. Tengo sentimientos encontrados y noticias acordes.
Por un lado, si es que estabas usando IE8- y visitando mi blog, asumo que debés de estar de pasada, no creo que seas el tipo de audiencia que lee este blog. Por lo general la gente acá utiliza Chrome o Firefox, y siempre en las versiones más actuales. Lamento decirlo, pero surfers de IE, son una minoría.
Por otro lado, les perdono que no hayan actualizado y ya solucioné el problema. Disfruten de dos colores más.
PS: Ahora tenemos búsqueda. ¡Wheeee!
Soy un zorrinito misericordioso.
...to clear your app permisions
De parte de i.MicroSiervos me entero de la existencia de MyPermissions.org, una pequeña recopilación de links comunes a distintas aplicaciones que nos lleva directamente al punto para remover/editar permisos de aplicaciones. Podemos encontrar muchas cosas en nuestro cementerio de aplicaciones de Facebook, Twitter, Google, Yahoo, Dropbox, etc. Vale la pena tomarse dos minutos y ver qué cosas estamos permitiendo que realmente no usamos, o peor aún, no deberíamos usar.
Soy un zorrinito seguro.
El mundo microscópico de los píxels
Hace un par de días, un artículo en MicroSiervos mostraba una comparación de las pantallas del iPad 2 y el iPad 3 (que no se llama iPad 3). Más interesante aún, dejaron el link al blog de Lukas Mathis, que entre otras cosas escribió un artículo llamado The New iPad’s screen under the Microscope.
Más allá de sólo mostrar la comparación entre las pantallas del iPad viejo y el nuevo, continúa agregando imágenes con el mismo aumento de otros dispositivos, tanto de Apple (iPhone 4S, iPod Touch), como de otras marcas y tipos de tablets o teléfonos. A mi me sorprende mucho la variabilidad que tienen los píxeles en cada una de las pantallas, y cómo la formita especial que cada uno tiene ayuda a una calidad particular de imagen.
Está claro que la gente de Google está peleada con el color verde y reducen su presencia (aunque yo había escuchado que el ojo humano es más sensible al verde que a otros colores, con lo que seguramente esto se haga para compensar), mientras que otros tratan a todos por igual (como el Nintendo 3DS).
Soy un zorrinito de color… (not).
Para que la comunidad se construya a sí misma
¿Recuerdan que alguna vez conté de UserVoice y cómo permite obtener feedback de la comunidad? Bueno, la gente de Microsoft me leyó (?) y el mismo desarrollo de ASP.NET MVC está siendo permitido por la comunidad. Una de las formas es este mismo user voice, que pueden encontrar en el ASP.NET MVC UserVoice Site.
Otra forma, menos obvia pero muy clara aún así, es que el framework es Open Source y está hosteado en ASP.NET en CodePlex, junto con otros proyectos muy cercanos. Está claro que se puede modificar pero Microsoft aclara que no van a tomar código nuestro (aunque siendo sinceros, creo que eso se evalúa en caso por caso). Sea como sea, dicen que están muy interesados en todo tipo de feedback.
Soy un zorrinito libre.
RESTful thinking
Someone save us from REST es el título de un curioso artículo de Rob Connery. Lo curioso es que por lo general REST es una buena práctica y es muy popular y deseado en cuanto a la organización semántica de nuestras aplicaciones web (o de los servicios que estas expongan).
La idea de REST es utilizar toda la complejidad que HTTP provee para dar un sentido más semántico a las operaciones que realizamos. De esa forma, pedir una página y enviar información deberían usar verbos distintos, e incluso deberían haber verbos distintos cuando esa información es nueva o se está modificando información existente. Al mismo tiempo, las URIs deberían ser identificadoras de recursos (de ahí su nombre) y no simplemente direcciones web. Ese es un pequeño resumen, pero la historia va mucho más profunda sobre la idea de darle un significado a las operaciones que se realizan en internet.
Rob Connery lo ve como las peleas grammar-nazi que ocurren en la internet. Es verdad lo que dice y pueden que tengan razón, pero realmente no es tan útil, y hay más discusión y confusión que verdad tras todo ello. Su punto de vista es que se están exagerando mucho las posiciones sobre esta discusión y que nadie tiene realmente una posición 100% clara de lo que REST significa, porque no hay un estándar al respecto.
Soy un zorrinito semántico.
...it's more likely than you think.
Muchos se habrán enterado del problema que tuvo Windows Azure con el día bisiesto del 29 de Febrero de 2012, el famoso leap year bug que causó downtime en la nube por todo el día. En algún momento se dijo que el problema no estaba relacionado con las fechas sino que fue coincidente, pero explicaciones posteriores confirmaron que era un problema de generación de certificados en el día bisiesto. Las razones de por qué se hace y cuáles fueron los problemas están explicados detalladamente en el blog de Azure: Summary of Windows Azure Service Disruption on Feb 29th, 2012.
Alguien preguntó en StackOverflow cómo protegerse de estos problemas. Por supuesto, si a Microsoft le pasa, a cualquiera de nosotros nos puede pasar. Por supuesto, no está del todo claro cómo fue que se generó la fecha inexistente, ni en qué lenguaje y Microsoft no da datos al respecto, pero esta persona aclara que aparentemente en el Framework .NET esto no ocurre.
Hay una respuesta en particular que me gustó enormemente, a pesar de no haber respondido la pregunta. él habla de un proyecto en el que está embarcado llamado Noda Time, basado en el Joda Time de Java. Esta API resuelve muchos problemas que por lo general ni siquiera conocemos.
Me gustaría transcribir y traducir parte de su post, indicando algunos ejemplos de estos problemas (aunque no te interese la programación puede que encuentres esto muy curioso):
(…)
- Mapear un horario local a zona horaria no es tan simple como pensarías. Una fecha/hora local > puede ocurrir una vez, dos veces (ambigüedad) o ninguna vez (se salta) por transiciones > de horarios de verano.
- Las zonas horarias varían históricamente - más de lo que TimeZoneInfo generalmente quiere > revelar, francamente (no soporta una zona horaria cuya idea de “tiempo estándar” cambia > durante el tiempo, o que cambia a horario de verano de forma definitiva.)
- Incluso con la base de datos de zonas horarias, los IDs de zonas horarias no son de fiar. > (CLDR se encarga de esto, algo que estoy esperando en soportar en Noda Time eventualmente.)
- Las representaciones textuales de fechas y horas son una pesadilla, no sólo en términos de > su ordenamiento, sino también los separadores de fecha, los separadores de hora, y cosas raras > como los nombres de los meses genitivos.
- El comienzo del día no es siempre medianoche - en Brasil, por ejemplo, el cambio de horario > de primavera mueve el reloj de 11.59:59 PM a 1 AM.
- En algunos casos (bueno, yo conozco uno) una zona horaria puede forzar a que todo un día se > salte - El 30 de Diciembre de 2011 no ocurrió en Samoa! Sospecho que muchos programadores > pueden ignorar esto, pero…
- Si vas a usar otro calendario aparte del Gregoriano, sé cuidadoso y asegúrate de saber cómo > se va a comportar.
(…)
Soy un zorrinito CST.
Crítica criteriosa
A menos que hayas estado viviendo bajo una roca por los últimos meses, deberías saber lo siguiente:
- Windows 8 es el nombre de la nueva versión del sistema operativo de Microsoft
- Windows 8 introduce a Metro, un intento de introducir a las pantallas táctiles como las privilegiadas en Windows sin incapacitar la interación de teclado y mouse
- Windows 8 es diferente. Si estás estancado en el 2001 con Windows XP, Gnome 2 y/o KDE 3, obviamente tampoco te va a gustar Windows 8. También tengo unos conejitos bailando para que mires.
(énfasis y links del artículo original)
Este artículo no tiene desperdicio, ya que me pareció totalmente balanceado y acorde con una opinión crítica. Da muy buenos consejos para los que estamos curiosos de Windows 8 pero no sabemos cómo seguir adelante. Ya comprarlo? Usarlo? Instalarlo? Máquina virtual o disco real? Qué me pierdo? Qué tiene? Vale la pena? Todas esas preguntas están respuestas en este artículo: Windows 8 & Metro with Mouse and Keyboard.
Soy un zorrinto crítico.
Autobiografías analíticas
Quizá esto merezca una explicación y una exposición pseudo-filosófica sobre el tema, pero eso requiere más tiempo del que dispongo ahora, de forma que sólo les dejo el dato. En este caso se trata de Steven Wolfram, científico fundador de Wolfram Research, inventor de Mathematica, y varios otros productos y libros que andan por ahí.
Steven cuenta que desde pequeño estuvo muy interesado en los datos, y comenzó, pensando que muchos otros lo hacían, a registrar datos sobre su propia vida. Para su sorpresa (de verdad?) no era tan común que la gente hiciera esto, y hoy es la persona con más datos auto-biográficos. Hace poco se publicaron unos artículos haciendo análisis de ellos, y realmente es increíble el tipo de tendencias que pueden detectarse gracias a ellos.
Via Proof me llega el artículo directamente desde el blog de Steven Wolfram, The Personal Analytics of My Life. Es fácil de leerlo, yo lo recomiendo.
Soy un zorrinito analizado.
De forma casi automatizada
Como siempre, yo sacando cosas de los foros de StackExchange, en este caso de ProWebmasters. La pregunta fue: Cómo trabajar con archivos CSS viejos? Específicamente, cuando estos archivos se vuelven enormes, y cuando ya no estamos seguros de qué está en uso, qué quedó en desuso, qué está repetido, qué se puede resumir, etc. Cuando tenemos un proyecto de ya un par de años, esto se hace muy difícil de medir.
La respuesta provee una buena cantidad de herramientas para probar que nos permite facilitar este trabajo, algunos de los cuales trabajan sólo en la página actual mientras que otros pueden realmente recorrer el sitio o usar un listado de URLs que les proveemos.
Soy un zorrinito limpio.
Top 5 de acciones para prevenirse
Desde el mes pasado estoy esperando a que Social-Engineer.org deje salir a la luz el newsletter que enviaron sobre tips de reducción de riesgo ante ataques de ingeniería social. Este newsletter, específicamente el número 29, se titula The Top 5 Social Engineering Mitigation Tips.
El newsletter es un poco más descriptivo que sólo enumerar cinco items, cuenta por qué son importantes y qué cosas podrían ocurrir si es que no se tuvieran en cuenta. Por alguna razón el formato se ve un poco roto y se veía mejor en el email, pero aún así es legible y útil.
Soy un zorrinito protegido.
Con cocodrilos y huevos
Ayer encontré en el foro de Theoretical Computer Science una pregunta sobre cómo aproximar la ciencia de la computación a chicos entre 8 y 14 años, muy apropiado también para alguien como yo que tiene muy poco conocimiento sólido de muchas de las estructuras y ciencias involucradas.
Todas las respuestas son muy buenas, unas más completas que otras, pero hubo una que me llamó poderosamente la atención. Esta era una forma divertida de aprender cálculo lambda, y se basa en un software creado didácticamente con cocodrilos y huevos, familias y cocodrilos viejos que explica la forma en que recursivamente se aplican las mismas reglas para dar resultados complejos.
Les recomiendo mirar el video completo, aplicado a la lógica booleana. Es muy interesante, y fácil de seguir.
Soy un zorrinito teórico.
La noble tarea de trabajar, efectivo y eficaz y en paz.
Sé que AP acaba de publicar esto (¡Gracias!), pero creo que su relevancia es tanta que voy a republicarlo también. él publicó un link a un artículo llamado The 10 rules of a Zen Programmer y antes de que digan nada: casi no tiene nada que ver con programación (de ahí el título que yo le dí). Las reglas que expone son imprescindibles para un buen trabajo, organizado y tranquilo. Estoy totalmente de acuerdo con todas.
Aún más, como yo comentaba, actualmente me encuentro leyendo un libro llamado Hagakure, que se trata del código de honor y conducta de los samurais del siglo XVI, escrito por samurais mismos. Me sorprendió mucho (y quizá no debería) ver que las pautas dadas en este artículo son muy cercanas a las expuestas en ese libro. Se trata de hacer noble la tarea a la que nos dedicamos y convertirla en algo casi espiritual.
Si a alguien le gustó tanto como a mí este artículo, el autor, Christian Grobmeier, tiene una categoría en su blog llamada The Zen Programmer, algo vacía aún, y está trabajando en un eBook en donde explicará todos estos conceptos con detalles, ejemplos y algunas cuestiones más. Si les interesa seguir el progreso, pueden ver los detalles en el Libro: The Zen Programmer.
Widget de autoguardado
Una característica que seguramente todos adoramos de GMail es el autoguardado. Al momento exacto en que dejamos de escribir un mail, este se autoguarda, y no recuerdo cuándo fue la última vez que perdí un mail por accidentalmente refrescar la página. Quienes vienen de las viejas épocas de Hotmail conocen mi frustración.
Hay alternativas interesantes para lograr este mismo efecto, una de las cuales es Sisyphus.js (gracias JH!), un proyecto de open source en GitHub que es un wrapper para formularios. Se encarga de automáticamente atrapar los eventos de cambio en ellos para guardar automáticamente en local storage la información del formulario. De esa forma, nuestro formulario siempre tiene la información guardada.
No dudo que pueda modificarse o atrapar eventos que nos permita también serializar esta información al servidor para que, al igual que GMail, esta información autoguardada quede relacionada con nuestra cuenta y no con nuestro navegador.
Soy un zorrinito autoguardado.
Cuando la respuesta no es obvia
Otro de los foros de Stack Exchange que suelo leer es Database Administrators, en donde, como imaginarán, las preguntas y respuestas rondan sobre bases de datos y tecnologías afines. Cada tanto me encuentro con alguna joyita útil y este fue uno de esos casos.
La pregunta trataba sobre alguien que tenía problemas de performance cuando no se trataba de el acceso a disco ni del consumo de CPU. Muy apropiadamente, la pregunta se llama SQL: What is slowing down INSERTs if not CPU or IO?, y por supuesto, siendo un caso particular puede que no nos sea realmente útil la respuesta. Lo que quiero destacar de esta pregunta es el método de investigación que usaron y las herramientas con las que analizaron la performance interna del motor de base de datos. Puede ser muy revelador para nosotros trabajar con estas herramientas cuando la respuesta no es obvia y los planes de ejecución no son suficientes para detectar problemas de performance.
Soy un zorrinito performante.
Bookmarklet de visualización de eventos
Muy parecido a debugCSS que alguna vez envié, VisualEvent es también un bookmarklet que nos permite trabajar con los interiores de alguna página. En este caso, nos mostrará visualmente cuáles son los eventos asignados a los distintos elementos e incluso muchas veces el código. Muy útil para debuggear y detectar problemas de interacción con código que tenemos que corregir. Además, también para considerar cuánto JavaScript estamos usando en una página (puede que sea mucho, no?)
Soy un zorrinito JavaScript.
Simpleza autocrítica
Para quienes no conocen el Joel Test, es una prueba muy simple, solo 12 preguntas que nos guían a darnos cuenta si nuestro equipo de desarrollo va por el buen camino o tenemos cosas que arreglar.
De ahí alguien preguntó si había una especie de Joel Test para la evaluación de un programador en particular, especialmente preguntas para hacer en entrevistas y para evaluar a gente de forma individual. Alguien mencionó que se podía trabajar con la Programmer Competency Matrix de IndianGeek, con la que ya he trabajado anteriormente. Aún así, no se ajusta específicamente a todas las características que alguien quisiera medir en un programador.
Al fin y al cabo, las respuestas no fueron muy iluminadoras, usuarios relacionados hicieron una pregunta en Quora sobre qué hay que preguntar a un candidato antes de contratarlo, las respuestas son un poco más interesantes y más allá del tema del entrevistado y la contratación, es interesante como ejercicio preguntarnos esas cosas a nosotros mismos y evaluar las respuestas.
Soy un zorrinito evaluado.
Una librería de referencias de patrones de usabilidad

Bueno, son las 4 AM y no puedo dormir. Acabo de terminar de leer el libro que venia leyendo lentamente desde hace tiempo ya, llamado Web Application Design Patterns, de Pawan Vora.
El libro en sí tiene el título muy bien puesto, porque realmente de eso se trata. Es una colección de patrones de diseño orientados a la usabilidad y la interfaz gráfica de las aplicaciones web. Para los que ya lo sabemos, recordaremos que los patrones son, como su palabra lo indica patrones. Son características en común y no soluciones definitivas ni detalladas de como aproximarse a una situación en particular.
Hablando de patrones en software, generalmente se los identifica de una forma muy común y muy particular. Cada patrón tiene un nombre que lo identifica, un problema particular que resuelve y una descripción de la solución básica a la que aproxima. La compilación de patrones que Vora hizo en este caso hace muy buen tributo de ese esquema y lo mejora en varios aspectos.
El libro se divide en varios capítulos que atacan temas comunes que merecen la atención en el desarrollo y la usabilidad de aplicaciones web, los cuales son:
Le doy crédito especial por la inclusión de esa última sección, en donde se definen las características que una librería de patrones (como este propio libro) debería tener, y se basa en varias librerías actuales en uso y recopiladas anteriormente por estudios al respecto.
En todas las secciones se muestran ejemplos, tanto de implementación como de uso real de esas características. Una gran mayoría de las veces se fundamentan los beneficios de estos patrones con estudios (las referencias están todas incluidas y detalladas al final del libro). Al mismo tiempo, están todos los conceptos explicados de una forma lo suficientemente detallada como para ser comprensible, lo suficientemente abstracta como para ser reusable y lo suficientemente clara como para ser entendida por no-programadores o diseñadores.
Una distinción que en este libro no se hace y me gustaría agregar como apreciación propia es que los patrones, como ya comenté, son soluciones a problemas determinados. No hay que confundirlo con buenas prácticas que, aunque cercanas, siempre conviene aplicarlas. El caso de los patrones es distinto, y de hecho, parecería ser imposible aplicar la totalidad de los patrones a cualquier sitio web. Ni siquiera los que están entre los ejemplos (Google, Apple, Mint, Facebook, Yahoo!, Basecamp, eBay, Amazon, y una larga lista de etcéteras) cumplen con la mitad de los patrones mencionados.
Volviendo al libro, lo recomiendo mucho como un libro de referencia. Está redactado como tal y no es una lectura ligera, pero vale la pena. 4 zorrinitos.
UPDATE 22/02: Tras pensarlo un poco más me dí cuenta que este libro no cubre una característica que si bien no está muy relacionada con la usabilidad, sí está relacionada con la experiencia del usuario, y ciertamente son patrones aplicados en web applications. Lo encerraría bajo la categoría de Performance, e incluiría cosas como caching de nivel aplicación, caching de nivel usuario, AJAX, conexiones persistentes, preprocesamiento de resultados. Son todas cosas que aplican como patrón a resolver un problema en particular en una situación en particular, siendo lo suficientemente abstractos como para ser aplicados en una variedad de casos. Posiblemente sería más difícil encontrar ejemplos (porque muchos sistemas no cuentan cómo es que funcionan por dentro), pero creo que sería bueno haberlos cubierto.
Soy un zorrinito usable.
Repositorio público de esquemas de markup
En el punto intermedio entre estándares y SEO está Schema.org, un sitio que haciendo uso de los estándares de microdata permitiría mejorar la meta-información que un sitio está aportando, específicamente para hacerlo más apropiado a los motores de búsqueda. La página de Getting Started nos da una buena idea de qué trata esto.
Según cuentan, Google y otros proveedores de búsqueda están teniendo mucho en cuenta estos formatos de metadatos, llamados micro-formatos, y justamente podemos apreciar muchos de ellos y su estado de aprobación en Microformats.org.
Soy un zorrinito micro-formateado.
...y volvieron para quedarse!
Eso, ya pude habilitar los comentarios (y quedarom medianamente arreglados), hagansé un festín de feedback para decirme qué piensan. Acuerdensé de comentar en todo lo demás, toda opinión es bienvenida (no por eso aceptada, jeje).
Soy un zorrinito comentado.
Orientado a mejorar la experiencia del usuario
Un problema común en cuanto a mejorar la experiencia del usuario es que muchas veces no se sabe cuál es el problema, o cómo los usuarios interactúan con la aplicación. Si bien algo de eso mencionamos cuando hablamos de 22 herramientas para mejorar la usabilidad, hoy el problema es interno de la aplicación, y se trata de loggear las acciones de los usuarios para identificar qué necesita mejora.
Entonces, ante la pregunta: ¿Qué vale la pena loggear de los usuarios para ganar perspectiva de su comportamiento? la respuesta es, como muchas veces, depende. La razón es que loggear es caro, loggear todo es imposible y solo resultaría en un montón de datos sin correlación a nada. Los detalles de qué aproximaciones se pueden tomar están también entre las respuestas a esa pregunta.
Soy un zorrinito loggeado.
Compendio de herramientas para mejor usabilidad
En mashable tienen un artículo muy interesante llamado 22 Essential Tools for Testing Your Website’s Usability. Cane destacar que el artículo no sólo expone las herramientas sino que además las categoriza y da una pequeña explicación de cada categoría, para que sepamos exactamente qué queremos medir en cada caso. Las categorías son: Análisis de tareas de usuario, legibilidad, navegabilidad, accesibilidad, velocidad y experiencia de usuario.
Soy un zorrinito usable.
Precompilación de CSS para .NET
Sé que esto no es ninguna novedad, pero lo explico para el que no lo conozca: less es un componente JavaScript que nos permite tener más flexibilidad en el tipo de cosas que podemos escribir en nuestros archivos CSS. Estos archivos pasan luego a llamarse archivos less, con una sintaxis muy parecida a CSS, pero con algunas mejoras, como la definición de variables, mixins (“funciones”) y anidamiento (namespacing?) de declaraciones. Como bien dicen entonces, less is more.
Ahora, uno de los grandes problemas con esto es que less es JavaScript, y por tanto, no está bueno que cada navegador tenga el trabajo de pre-compilar el CSS y aplicarlo a cada página. Es un poco trabajoso (dependiendo de la complejidad de nuestros estilos y nuestras páginas), pero está claro que es demasiado trabajo. Alguien preguntó si había una forma de compilar los archivos less a CSS para que cada navegador no tenga que hacerlo, y obtuvo una buena cantidad de alternativas.
Yo encontré una no mencionada, y sacada directamente de NuGet, dotless es la portación de esto mismo a .NET, con la diferencia de que está implementado en forma de HTTP Handler, lo que significa que el browser se encarga de resolver los pedidos de archivos .less y devolverlos como CSS. Mejor aún, ya puede devolverlos minimizados y cachearlos. Dije que es un paquete Nuget? La instalación en sí son 4 clicks. Muy adecuado.
Soy un zorrinito cómodo.
Error Logging Modules and Handlers for ASP.NET
ELMAH es un proyecto hosteado en Google Code bajo la licencia Apache 2.0, que automáticamente se inserta en nuestro código para darnos un tratamiento mucho más complejo de errores, incluso de aquellos que surgen de forma inesperada (que, filosóficamente hablando, debería ser la mayoría de ellos).
Cabe aclarar que las características que ELMAH provee out-of-the-box son:
Cabe destacar que se sabe que ELMAH tiene ciertos problemitas en integrarse a aplicaciones ASP.NET MVC, específicamente por la forma en que se tratan algunos errores, pero tienen una solución aceptable, como explican en What are the definitive guidelines for custom error handling in ASP.NET MVC 3? (Lástima que la pregunta original nunca se respondió de forma completa.)
Si les interesa una respuesta más apropiada a esa pregunta (cómo deben tratarse las excepciones), les recomiendo un link compartido por JM, 15 Best Practices for Exception Handling, muy recomendable.
Soy un zorrinito excepcional.
8 formas comunes, en ASP.NET
Este es un problema común y por eso me pareció apropiado hacer un poquito de difusión a este link en particular que encontré entre los Enlaces interesantes número 66 de VariableNotFound. Muy apropiado, el artículo se titula Eight Different Ways to Transfer Data from One Page to Another Page (por Dios, son feas las páginas de EggheadCafe). Como bien aclara el mismo artículo, hay más formas de hacer eso, pero creo que estas primeras ocho son las aproximaciones más comunes, e incluso muchas independientes del lenguaje. Cada una de ellas tiene consideraciones que no se mencionan en el artículo, pero aún así es bueno como referencia rápida.
Soy un zorrinito transferido.
No está el 3, vamos por el 4!
Síp, los selectores CSS4 ya hicieron su apareción en uno de los primeros drafts de la W3c en septiembre del 2011. Sin embargo, les falta un buen camino para que siquiera vayan a implementarse en cualquier navegador, por lo que no están listos para ser usados, ni siquiera para ser probados.
Hay muchos pseudo-selectores y unos cuantos selectores en sí, y si prefieren una versión resumida, pueden visitar el artículo de Meet the CSS4 selectors, pero en el fondo les recomiendo leer el draft de la W3C y hacerse agua la boca con lo fácil que va a ser aplicar estilos.
(vía los Enlaces interesantes número 65 de VariableNotFound)
Soy un zorrinito estilizado.

Hace un tiempo ya que en nuestro equipo estamos integrando Backbone.js a nuestros proyectos. La idea tras backbone.js es, como su nombre lo indica, ser la columna vertebral del código javascript frontend, de forma que todo trabaje sobre una estructura centralizada y permita al código no ser un desastre auto-destructivo o conflictivo cuando los proyectos crecen. Esto se da mucho en aplicaciones con mucha interacción de usuario, y es importante para una aplicación compleja poder tener el código organizado. Backbone le da una estructura al código del tipo MVC en donde podemos diferenciar datos, de presentación de los mismos y de elementos que controlan la interacción entre ambos.
Ahora, el problema con backbone es que es un poco difícil de aprender. Tiene mucha estructura, poca documentación y no todo es obvio. Gracias a AM y a SC que me han compartido estos documentos útiles: Backbone Fundamentals y Backbone Patterns.
Toda esta temática queda muy acorde a The Seven Deadly Sins of JavaScript Implementation, en donde backbone.js se encarga de un par de pecadillos.
Soy un zorrinito frontend.
**UPDATE: **For English readers, you may check out this Backbone.js Introduction and Resources.
Un fauvista con cubiertos de gala
No hace mucho que, gracias a un proyecto paralelo a mi trabajo, estoy aprendiendo a usar Git. Encontré que es una herramienta sumamente compleja y flexible, distribuida y rápida.
Git, para quién no lo sabe, es un sistema de control de versiones, distribuído, enfocado en la velocidad, y que fue desarrollado por Linus Torvalds exclusivamente para el desarrollo de Linux, luego dejándolo libre para su uso indiscriminado. La historia es algo humorística, ya que, en pocas palabras, Linus decía que todos los sistemas de control apestaban de una forma u otra, y quiso hacer algo que fuera bueno de verdad. Quizá no estén de acuerdo con que sea tan superior, pero tienen que aceptar que es realmente radical. Si no saben por qué, sigan leyendo.
Con su primer release en el 2005 y ganando más popularidad en la actualidad, Git ha probado ser eficiente y un buen recurso para el control de versiones. Mejor aún, para el programador.
Soy un novato todavía, pero quiero compartir mis pequeños avances con Git como para que los demás puedan aprender conmigo. Suelo trabajar mucho en Windows y si bien mis primeras experiencias fueron con Git Extensions, al final el uso de la consola terminó siendo mucho más efectivo. Git Extensions mismo viene con una consola y si están en Linux, hay versiones de Git de sobra que pueden utilizar.
Nuevamente, decía que soy solo un novato por ahora, y si bien creo tener razón en lo que voy a afirmar, entiendo que puedo estar totalmente equivocado. Sientansé libres de contactarme y corregirme. Estoy dispuesto a hacer crecer esto todo lo que sea necesario, o de hacer muchas entregas como para aportar información interesante. No sé en qué terminará esto, pero mientras más informativo, mejor.
Git, a diferencia del resto de los sistemas de control de versiones, funciona de una forma tan granular que nos permite generar nuestro propio proceso en lugar de adaptarnos a un proceso estándar. Hay quienes prefieren trabajar de alguna forma y quienes prefieren trabajar de otra, pero una vez que se entiende bien la filosofía de Git, es todo , en el fondo, lo mismo. Comencemos.

La filosofía de Git, en pocas palabras, es de apartarse del trabajo diario del programador (o diseñador, o lo que sea que hagamos) y dejarnos hacer nuestro trabajo. Git se encargará, cuando se lo indiquemos, de identificar las diferencias, y de convertirlas en cambios graduales que querremos versionar de forma conjunta o de forma separada. Cambiar un archivo dos veces no implica un único cambio. Cambiar varios archivos no implica cambios separados. Todo queda a nuestra discresión.
Y eso es parte de lo importante: Git nos permite hacer nuestros cambios de una forma “ordenada” y hasta semántica. (Me gusta mucho últimamente esa palabra.) Podemos dar determinado significado al progreso de nuestros cambios, de forma que tengamos controlado cuando podemos volver atrás y cuándo podemos seguir adelante. Cabe destacar que ambos son posibles en cualquier punto de nuestro trabajo. Más adelante se darán cuenta de por qué digo esto.
Para aquellos que estábamos acostumbrados a VSS, TFS o SVN, nos daremos cuenta de que es algo distinto. Quizá los que usaban SVN desde la consola lo encuentren, en algo, similar, pero la filosofía en la que se manejan los cambios es totalmente distinta. Se darán cuentas que cosas que por lo general son imposibles de hacer, son totalmente naturales, y de hecho, se hacen todo el tiempo. Esa es, en pocas palabras, la filosofía de Git: No ponerse en el camino del programdor. Ser una herramienta, no un obstáculo.
Distribuído, cloud computing y todo lo demás es un término exageradamente abusado hoy en día. Todos sabemos las ventajas que esto tiene y en general por qué convienen (o por qué no). En el caso de Git, es realmente una ventaja, y no tenemos por qué sufrirla si un sistema distribuído no nos conviene.

Que Git sea distribuído significa que no hay ningún repositorio central, ninguno vale realmente más que otro. Por supuesto, muchas veces nuestra organización hace que hagamos de uno de ellos el repositorio central, pero cualquiera de ellos podría hacerlo, y esto significa que los repositorios centrales también pueden invertir su rol de a ratos. Supongamos que Alice y Bob se copian un repositorio central de Carlos (esto se llama clonar). Ambos trabajan sobre A y B, pero Carlos también sigue trabajando en C. Si Bob quiere obtener la última versión de todos ellos (así convirtiéndose en un repositorio central por un momento), sólo tiene que “jalar” los datos (pull) desde los repositorios A y B. Cualquiera de ellos puede hacer lo mismo.
Mejor aún, con los permisos necesarios, cualquiera de ellos puede “empujar” cambios (push) a los otros repositorios. Claro, que si no hubiera reglas, todo sería un descontrol, pero Git nos permite acomodar la organización como mejor queramos. Los repositorios son gratis, ocupan poco espacio y pueden clonarse infinidad de veces.
Se imaginan que con una característica tal, cada repositorio copia es, en cierta forma, un backup del repositorio central (o del que designemos como repositorio central). Cada cambio puede pasar por un proceso separado y por una cantidad de repositorios distinta hasta llegar a estar presente en todos lados. “Qué desastre!”, pensarán. Y eso les comienza a dar la idea más importante: Git es una herramienta muy avanzada, podemos realmente hacer desastres catastróficos con ella, pero también podemos hacer procesos elegantes y simples, sin comprometer las necesidades.
Un ejemplo real: en un proyecto en el que actualmente estamos trabajando, A, B y yo (yo seré C), tenemos un repositorio central en GitHub, online. Cada uno de nosotros tiene su fork (copia) del mismo repositorio también en GitHub, y a la vez, cada uno de nosotros tiene una copia local. Todos trabajamos en la copia local, hacemos nuestros branches, commits, etc. Cuando es necesario, empujamos nuestras cosas a nuestro repositorio de GitHub, de forma que ambos están sincronizados. Cuando el momento es el apropiado, enviamos pushes al repositorio central. Cada uno de nosotros tiene acceso al repositorio central de la misma forma que al suyo, lo cual permite muchas veces arreglar errores del pasado (sí, Git permite eso) pero en general, esta estrategia ayuda a sincronizarnos. A veces trabajamos trayendo y llevando cosas entre nuestros repositorios, sin uso del central, hasta que una característica esté lo suficientemente madura.
Dejo esto por ahora. Prefiero hacer los posts cortos y que sean muchos, a que sean grandes, largos y nadie los lea.
Soy un zorrinito distribuído.
Acabo de terminar de leer Pro ASP.NET MVC3 Framework, un libro de Apress, escrito por Adam Freeman y Steven Sanderson. En pocas palabras, el libro es muy bueno, no exageradamente detallado pero buena aproximación para quiénes quieran ganar un nivel principiante/intermedio en la plataforma. Determinadas características han quedado afuera, y por supuesto, detalles de la implementación del framework también. Eso habría sido material para una buena cantidad de otros libros. Este en particular está muy orientado al ejemplo práctico, y es ideal para afianzar teoría con pequeños snippets de código que la hacen práctica. Cubre algunos aspectos relacionados a esto para darle un buen contexto y es una buena opción por su precio, pero no es suficiente para el que quiera entrar demasiado profundo en los interiores de la plataforma.
El libro se divide en tres grandes partes. La primera parte, llamada Introduciendo ASP.NET MVC 3, es una explicación muy a vuelo de pájaro de qué es MVC, cómo es la aproximación de Microsoft a él y unos ejemplos básicos para demostrar la organización de una aplicación MVC. Se habla un poco de inyección de dependencia, haciendo uso de Ninject, pero su aplicación es de lo más básica y no justamente asociada a las buenas prácticas, aunque como primer paso, es bueno. Habla de DDD y de TDD, ayudado de Moq, desde un punto de vista tan superficial que no hacen impacto en el resto del contenido, pero siguen estando ahí.
La segunda parte del libro, ASP.NET MVC3 en Detalle, comienza a hablar del sistema de ruteo, de cómo se enlazan a él los controladores y las acciones, el uso de filtros (casi tocando AOP para controladores, pero no mencionándolo), uso de controladores propios, autorización, generación de un engine propio de vistas, uso de helpers, vistas parciales, acciones hijas, templates de modelos, binding de modelos, validación, AJAX, y el uso de jQuery. En estos últimos dos puntos debo hacer una aclaración: la forma en la que se implementa AJAX es todavía muy Microsoft-oriented, del estilo de hacer una receta y que todo funcione de forma mágica. Se queda muy corto para customizaciones y aplicaciones reales con lógica de cliente compleja, pero recordemos que este libro es sobre ASP.NET MVC, no sobre JavaScript. Aún así, es un buen comienzo para profundizar en otro libro.
La tercera y última parte, Entregando Projectos ASP.NET MVC 3 Exitosos, cubre varios puntos extras no exactamente de a la plataforma pero relacionados. Uno de ellos es la seguridad. Se le dedica un capítulo entero a determinados tipos de ataque y forma de evitarlos. Como los otros temas tangenciales, no es una guía definitiva, pero un buen punto para comenzar. Otro capítulo está dedicado a la autenticación y la autorización, sin mucho detalle y sin mucho ejemplo esta vez, pero pasos básicos que nos permiten conocer varias opciones distintas para las distintas situaciones que debamos afrontar. El último capítulo de esta parte se enfoca en el deployment y la generación de paquetes de instalación. Nuevamente, no contiene mucho detalle.
El libro en general es bueno como introducción y bueno como ejercicio de aprendizaje. Es detallado en el comienzo y light al final, con lo cual sus 836 páginas en realidad son un resumen de mucho más que podría cubrirse. Es un balance apropiado, con lo cual recomiendo su lectura. Le otorgo unos 4 zorrinitos.
Partiendo desde la base de lo básico
Este es otro de esos encuentros que hago en los foros de StackExchange, específicamente en el de User Experience. Aquí alguien preguntó ¿Cómo es que los bordes redondeados afectan la usabilidad?
La pregunta estaba orientada al saber el por qué los bordes redondeados son algo deseable, y de qué forma afectan a nuestra experiencia de una página web. Al mismo tiempo, también pregunta por qué la mayoría de los sitios permite que estos bordes aparezcan no-redondeados en versiones viejas de algunos navegadores, si es que es una característica tan importante.
La respuesta más votada habla de la psique humana y cómo el ser humano responde de forma más amigable a objetos redondeados. Hizo una referencia muy interesante también, basándose en el libro Universal Principles of Design, un libro que analiza desde lo más básico la experiencia de usuario en mundos más allá de la informática (incluyéndola también). Mostrando cosas como desde el diseño de juguetes, al diseño de menúes y pasando por el diseño de elevadores, este libro parece ser una de esas joyitas que iluminan más el por qué que el cómo hacemos lo que hacemos todos los días.
Soy un zorrinito especulativo.
La iniciativa mobile de Google
Gracias a i.MicroSiervos me enteré de GoMo, una aplicación web que toma nuestro sitio y nos analiza de forma personalizada las características del mismo y nos da sugerencias para pasar al mundo mobile. Cosas como la visibilidad de la página, los links, las tecnologías utilizadas y demás, está todo disponible en un reporte de forma gratuita.
Cabe destacar que este sitio es en realidad una iniciativa de Google, con lo cual gana un poco más de renombre.
Les recomiendo también visitar el mismo sitio desde un dispositivo movil, la enorme diferencia con el sitio original realmente habla de tomar una aproximación diferente al momento de pensar en mobile.
Soy un zorrinito móvil.
Otra iniciativa más de enseñanza online
Me encontré como noticia en ALT 1040 que Sebastian Thrun dejó Stanford para comenzar su propia iniciativa de enseñanza online, llamada Udacity. En este preciso momento se están enseñando sólo dos cursos: Cómo construir un auto que se maneja solo y Cómo construir un motor de búsqueda. Ambos están dados por Thrun y el del motor de búsqueda está también asociado con David Evans.
Se vienen nuevos cursos durante este año, que también parecen ser muy interesantes, como Sistemas Operativos, Sistemas Distribuidos, Redes, Seguridad, Algoritmos y estructura de datos, Prácticas de Ingeniería de Software, Construir aplicaciones web, etc. Nombré los cursos que están nombrados en la página al día de hoy, pero quién sabe qué traerá el futuro. Parece que por hoy está teniendo mucho éxito.
Soy un zorrinito estudioso.
Conseguí una lapicera dorada +20!
La gamification (…jueguización? ugh) es algo muy común y popular en estos días para aplicar a distintas actividades, y alguien en Productivity de StackExchange decidió preguntar si existen técnicas de productividad basadas en juegos. Desafortunadamente las respuestas no son muchas y no hay demasiadas opciones, pero las pocas que hay son iluminadoras.
Uno es el caso de EpicWin, una aplicación de iPhone que en base a las tareas que uno completa va ganando puntos de experiencia y subiendo su nivel, obteniendo items, y equipando así a un personaje. Sus contrapartes en el Android Market son Task XP y RLRPG.
Hubo alguien que utilizó automatización sobre su inbox para generar gráficos de productividad. Muy seguramente esté trabajando bajo la premisa de Inbox Zero, también muy útil para tener la mente y el inbox limpio.
Alguien más se basó en Pomodoro y creó un juego integrado en su sistema de tiempos. Mantiene una wishlist de cosas que le gustaría comprarse, pero sólo se lo permite cuando, tras terminar una tarea, su oportunidad de tirar los dados le favoreció. No gana todo el tiempo, pero mientras más tareas haga siempre va a tener una oportunidad extra, aumentando las posibilidades.
Soy un zorrinito jugador.
yeaaah, venga esa complejidad!
De los rincones recónditos de User Experience en StackExchange y una pregunta de cómo incitar a los usuarios a poner passwords fuertes, me entero de la existencia de Naked Password, un plugin de jQuery que en sitios informales (muy informales) incentiva a los usuarios a usar passwords complejos, de forma… digamos… “natural”. Pueden probar el demo en su misma página.
Dicho sea de paso, otras buenas respuestas fueron:
Soy un zorrinito de poca complejidad.
De HTML a PDF
Nombre complicado, pero aplicación muy útil. Hace algunos días ando trabajando con wkhtmltopdf, una aplicación basada en QT y en Webkit que renderiza páginas web y las convierte en PDFs. Lo interesante es la forma en la que se puede automatizar este proceso, generando elementos más allá del contenido en sí (como tablas de contenido, encabezados y pies de página, etc). Mejor aún, este paquete contiene wkhtmltoimage.
Por supuesto, todo esto puede ser parte de una aplicación mayor que genere PDFs o imágenes desde otro documento (luego publicaré algo sobre eso) basándose en un proceso automatizado. Parece que es muy comùn que aplicaciones utilicen esto de fondo para generar screenshots de páginas web o reportes PDF desde un HTML.
Soy un zorrinito screenshoteado.
Dominio para desarrollos locales
En geeks.ms (via los enlaces interesantes de VariableNotFound) publicaron un artículo/tip/huevo de pascua (no lo considero un huevo de pascua) sobre dnndev.me, un dominio registrado y apuntando sus entradas DNS a 127.0.0.1. La idea detrás de esto es que los desarrolladores puedan utilizarlo para no modificar sus entradas en el archivo hosts. El nombre del dominio viene realmente de DotNetNuke Development, que es la razón que llevó a registrar este dominio. Yo me hubiera conformado con un localhost.com, o loopback.me, o algo así.
Realmente no es tan útil si uno sabe cómo editar los archivos de host, pero – y acá lo interesante – muchas veces no tenemos accesos de administrador para lograrlo, y en ese caso es en donde necesitamos un DNS que nos devuelva 127.0.0.1 para estas cosas. Ahí es donde esto se vuelve realmente útil.
A ver quién tiene una idea similar y registra dominios para apuntarlos a direcciones de redes C. No les gustaría ir a 192-168-0-1.my.net y que tengan acceso a su router? Mejor aún, podrían usarse alias en subdominios para IPs conocidas dentro de las redes. linksysrouter.my.net, broadcast.my.net, etc. ¿Quién será el valiente?
Soy un zorrinito cobarde.
El problema es la receta, no la sopa.
Hace mucho que todos estamos siendo bombardeados por la historia de esta ley que casi sigue su curso, pero hay un tema en particular que no veo nombrar y que creo es el más importante. Es como si todos se quejaran de un dolor de cabeza pero no se preguntaran por la enfermedad, sino sobre como quitárselo.
Esta es mi (humilde e ingenua) opinión al respecto.
(Antes de matarme, por favor lean lo que tengo para decir.)
Creo que el argumento de que los senadores no entienden de tecnología como excusa para decir que la ley no tiene sentido es un poco simplista. Puede que no haya sido una buena idea, pero estas cosas se piensan antes de convertirse en propuesta. Dejando de lado que esto puede haber sido algo que surgió de las empresas multimediales, la ley tenía un sentido práctico: detener la piratería.
Muchos critican que la ley era dirigida a regular a quienes permiten los accesos a la piratería más que a la piratería en sí. Eso también tiene sentido. Cuando el asesino serial no hizo caso a la ley de “no matar”, hay que asegurarse que nadie lo ayude. Si drogarse fuera ilegal, vender droga también lo sería, es natural pensar que si la piratería es ilegal, llevar a piratería también lo sería.
Por otro lado, los comentarios que he visto al respecto muestra muy poco conocimiento sobre las leyes de copyright. Las leyes de propiedad intelectual están muy claras y son vigentes. Esta ley no era nada nuevo en cuanto a qué regulaba, era nuevo en cuanto a quién estaría obligado a reaccionar y las medidas a tomar. (Más un par de detalles que a drede voy a dejar fuera.) En resumen, la ley decía “tomemos más seriamente las leyes que ya tenemos”.
El problema de SOPA estaba más allá de SOPA, y esto es lo que veo que muy pocos dicen. El problema de SOPA era el copyright en sí mismo, pero cuando SOPA iba a aplicar esas reglas “de a de veritas”, todos nos preocupamos.
El problema con las leyes de la propiedad intelectual es que crean una propiedad sobre elementos que no pueden ser reclamados ni robados. Para hacerlo aún más obvio: reclaman propiedad en donde no se puede reclamar propiedad.
El mundo de a poco ha reaccionado un poco a esto haciendo de las licencias libres algo muy natural en entornos en donde no se puede ganar esa pelea. El software es un campo de batalla que el open source está ganando de a poco. (El modelo as a Service no probó ser rentable de casualidad.) La música y las películas es una batalla que el propietarismo ya perdió pero que resiste a retirarse.
Tuve una charla con un colega al que le expliqué mi punto de vista de esta forma: ¿Qué es una canción, si no un montón de ruidos juntos? ¿Podemos decir que alguien es dueño de ese ruido y nadie más debe poder usarlo? ¿Los libros, un manojo de palabras?
Por supuesto, la respuesta de esta persona fue muy apropiada: hacer música cuesta dinero, tiempo y aprendizaje. Hacer libros requiere también tiempo, dinero, investigación, edición, etc, etc. ¿Cómo fomentar la cultura si esta gente no recibe dinero por lo que hace?
Y mi respuesta es que lo que esta gente vende no es ni ruido ni palabras, es lo extra que todo eso tiene. Uno no escucha música porque sí, sino que uno la experimenta y la disfruta (como todo arte, lo que se vende es el sentimiento – incluso aunque sea un resultado de una fórmula marketinera). Un libro no es un montón de palabritas juntas, sino la información extra que aporta. Lo que compro cuando compro algo de eso no es el material ni el medio (que, según la ley de copyright, no deben tener dueño), sino el ahorrarme tener que hacerlo yo. Estoy comprando trabajo pre-hecho.
En ese sentido, este trabajo es un trabajo como cualquier otro. Quienes escriben libros deben poder vivir de ello, quienes hacen música deben poder vivir de ello. Pero como un trabajo justo, debe pagársele por su trabajo, nada más. Su éxito es un resultado de qué tan bien está hecho su trabajo. Recuerden: cultura. La comercialización no es algo malo, pero ese es otro trabajo. Si lo que queremos es que alguien talentoso haga un buen trabajo, hay que mantenerlo bien pagado mientras ese trabajo se hace, no cuando ya está hecho. Hay que recompensar el buen trabajo, no el buen descanso.
Una vez hecha la obra, vale tanto como su material, porque ya no hay nada más que debería pagarse. ¿O acaso solo los que tienen dinero deben acceder a nueva información? ( ¿Es así como fomentamos la cultura?) Si el medio no vale nada, la obra en el mercado no debería valer nada. La piratería es la respuesta natural del mundo a eso.
Quiénes exigen que el copyright se pague caen en una de las siguientes categorías:
La discusión sobre cuánto es lo justo para cada empresa es otra discusión extensa, y creo que abarca más de lo que puedo opinar acá. Pero no, la propiedad intelectual no tiene cabida ahí, solo el trabajo realizado.
Primero, démonos cuenta de que estamos ladrándole al árbol equivocado. El problema no es SOPA ni la internet. El problema es el copyright y lo que estamos pagando.
Segundo, denunciemos las extorsiones de compañías a artistas. Si alguna vez tuvieras la oportunidad, exigí que tu contrato esté libre de copyrights propietarios. Si realmente amás lo que hacés, vas a comprender mis palabras. Si ves que tu copyright ya no te genera dinero, no nos hagas perder el tiempo y cambialo. Si tu película o tu canción ya se pirateó, ofrecé una descarga oficial y promové el modelo pay as you want, donaciones, vendé publicidad o merchandising, etc, etc.
Tercero, prestemos un poco más de atención a las injusticias de la propiedad intelectual que ocurren todos los días y protestemos por eso también. No esperemos a que la ley se tome en serio para darnos cuenta de que estaba mal.
Cuarto, dejemos de actuar como si la cultura fuera algo que nació en internet. Vivimos el 90% de nuestras vidas fuera de él (bueno… algunos un poco menos). Hagamos énfasis en que la libertad esté fuera de él también.
Mi guía novata a la organización
Hace un tiempo ya, y realmente, el día que salió, yo ya tenía una cuenta de Trello. Era simple, era bonito, era rápido, pero no veía el gran poder que tenía. Es porque, como muchas cosas, hay que saber utilizarlas.
Hoy es para mi una herramienta fundamental en mi organización (personal y laboral) y me ha vuelto más productivo y ha evitado muchos de esos momentos de “_ ¿y ahora qué?” o “ ¿en qué estaba?_”. Voy a compartirles el como para que sepan cómo lo hago yo, y espero comentarios de cómo lo hacen ustedes. Hasta que arregle los comentarios del blog, pueden responderme a @AlphaTwi.
Trello se compone de boards (pizarras) que a su vez se componen lists (listas), que a su vez contienen cards (tarjetas).
Cuando crean un board por primera vez, verán esto como su contenido.
(Puede que se vea distinto si su resolución de pantalla es menor, en ese caso pasará al modo mobile.)
El flujo ya es bastante apropiado en la forma en la que se presenta, y es ideal para grandes grupos de gente (ah, es multiusuario). Básicamente, las cosas se van dando de alta en la lista To Do, al momento en que comienzan a trabajarse, se mueven a Doing, y al momento de terminarlas se pasan a Done.
La simple disposición de tareas de esta forma ayuda a responder muchas preguntas.
Cuando las cosas están en To Do es porque es importante ver cuáles son todas las cosas pendientes. Responde preguntas como “terminaremos para hoy/mañana?” o “cuando termines con esto estás libre?”.
La lista de Doing ayuda a ver qué progreso se está haciendo. Responde preguntas como “En qué está trabajando José?” o “Qué estaba haciendo yo?” (especialmente útil para los que lidian mucho con interrupciones).
La lista de Done ayuda a ver qué se terminó. ¿Qué sentido tiene esa lista? Ayuda a responder preguntas como “_ ¿Qué porcentaje de tareas terminamos?”, “ ¿Avanzamos mucho?”, “ ¿Qué está presente en esta versión?_”.
Mis cambios a ese esquema por default no han sido radicalmente distintos, pero lo suficiente como para mencionar. Este es el caso de mi trabajo, tengo distintos esquemas para distintos tipos de proyectos personales (y creo que esa es una de las cosas que hace a esta herramienta tán versátil). Estas son mis listas y para qué se usan:
To Do: Igual que siempre este es el listado de todo lo que se tiene que hacer, o que algún día tiene que ser resuelto. Puede ser mañana, puede ser la semana entrante, puede ser “algún día” indefinido.
Get Done Today: Al principio del día, luego de checkear mis correos y verificar qué cosas tengo pendientes que no sabía antes, elijo desde To Do un listado de ítems que obligatoriamente tengo que terminar el día de hoy. Puede basarse en prioridad, en tiempo disponible, en urgencias, en la dirección del viento. La forma de elegirlas no importa, lo que importa es que esas tareas son mi compromiso del día. Me sirve también para reportar en nuestra scrum meeting qué es lo que voy a estar haciendo.
Doing right now: Como su nombre lo dice, el listado de cosas que estoy haciendo ahora mismo. Si no tengo nada acá, probablemente esté almorzando. Si tengo más de tres tarjetas aquí, seguramente algo saldrá mal. Cuando me llaman por teléfono, me buscan en la oficina o me interrumpe un email, este es el lugar al que vuelvo a mirar y resumo mis tareas.
Waiting for feedback: Este es el listado de cosas que comencé pero estoy bloqueado y requiero que alguien más intervenga. Es porque la tarea depende de alguien más o porque estoy esperando respuesta de alguien para poder continuar. Siempre les agrego un comentario a esas tarjetas para poder leer cuál fue la última vez que la actualicé y para saber qué estoy esperando que me respondan o hagan. Puede que una vez que me respondan las tarjetas se muevan de aquí a To Do, o, si tengo suerte, a Done.
Done: Nuevamente, aquí es donde vienen a morir las cosas que ya hice. Mantengo este listado hasta el fin del día, en donde lleno mis timesheets (mi empresa requiere que llene un listado de qué actividades realicé cada día). Las tarjetas me ayudan a recordar, y el tener que limpiar esa lista me hace recordar llenar el timesheet.
Este es un ejemplo con mi día de hoy (exitosamente cerrando la semana):
Probablemente lean mis ítems y no entiendan en qué estoy trabajando, porque los títulos no son muy explicativos. Ese es otro beneficio: no tienen que serlo. Sólo tienen que decir lo suficiente como para que yo recuerde de qué se trataba todo. Si necesito más detalles uso los comentarios o las descripciones de las tarjetas (que, dicho sea de paso, soporta Markdown). Si necesito varios puntos intermedios agrego una checklist (como el primer item en la imagen), y es todo a gusto.
Espero que esto haya sido útil para quién lo lea. Si tienen sugerencias, estoy encantado de oírlas, sería muy útil para mi también aprender de alguien que sepa organizarse mejor.
Soy un zorrinito organizado.
Contratar programadores según su capacidad para resolver problemas
Interviewstreet es una tentativa de cambiar la forma en la que las empresas contratan a sus programadores. En lugar de hacer evaluaciones en el lugar, o inventar evaluaciones propias, pueden servirse de las que están aquí, y los programadores pueden utilizar el sitio para probarlas, enviarlas, obtener un puntaje y exhibir su perfil de logros en el mismo sitio. De esa forma, las empresas pueden verificar cuál es el desempeño de cada perfil.
Personalmente no me parece una buena aproximación, pero es un sitio con desafíos a resolver. Siempre hay algo interesante que probar. Me recuerda a Project Euler pero sin la parte empresarial.
Soy un zorrinito problemático.
Una guía para salvar los electrónicos mojados
Paseando como siempre en los foros de StackExchange, específicamente en el de SuperUser, me encontré con una pregunta anecdótica: Lavé mi pendrive. Algún riesgo a largo plazo? Las respuestas sobre esa pregunta en particular son algo diferentes, algunos han experimentado problemas y otros no, pero las respuestas extendidas dan muchas instrucciones de cómo tratar en estos casos. Personalmente leí más de lo que sabía, hay muchos buenos consejos para aplicar en esa situación.
Soy un zorrinito limpio.
Un wrapper de tecnologías HTML5 I/O
Desde el Tumblr de Eric Bidelman me entero de su publicación de filer.js, un wrapper en JavaScript de tecnologías de sistemas de archivos de HTML5, no realmente agregando más funcionalidades, sino haciéndolo más accesible y más simple de utilizar para aquellos que hayan trabajado con APIs de I/O en otras plataformas. Se lo puede ver trabajando online en sus demos, como el HTML5 Filesystem Playground.
Soy un zorrinito archivado.
Otra gran apuesta a la educación online
Leí esto en alguna entrada de MicroSiervos pero desafortunadamente perdí el link y no puedo encontrarlo. Ellos linkeaban a una artículo hablando sobre MITx (FAQ), una de las nuevas apuestas de las universidades de tecnología para la educación online y gratuita. En este caso, como pueden adivinar por el nombre, se trata del MIT.
Aparentemente esta propuesta comenzaría a funcionar en estos primeros meses del 2012, y las clases van a tener ciertos certificados que demostrarían el conocimiento de uno sobre la materia en cuestión, pero nada realmente que tenga el nivel de un título del MIT en sí mismo.
Recordemos que MIT también es el dueño de OpenCourseWare, un esfuerzo similar, y ese seguirá siendo mantenido.
Soy un zorrinito educado.
Empezando un blog más ordenado y limpio
Allo, me pegué una terrible actualización de estilos. Como ven, la página está mucho más limpia, y desde mi punto de vista, un poco más legible y elegante. Se aceptan sugerencias.
Notarán que no todo está disponible como antes, muchas cosas desaparecieron. Algunas volverán a aparecer, otras quedarán en el olvido.
Las cosas que deberían volver a aparecer y/o que no están funcionando bien (y debo arreglar) son
En fin, acepto tanto críticas como sugerencias, y por supuesto, halagos. No hay comentarios así que no podrán hacerlo por acá, si quieren hacerlo en otro lado son bienvenidos a mi Twitter: @AlphaTwi.
UPDATE: Este diseño es mobile friendly. Navegadores del pulgar, sientansé libres de disfrutar de algo mucho más legible.
Del blog de Edu me entero de un software llamado AjaxMyTop, que es básicamente un manager de procesos open source para MySQL. Muy útil para, de una forma simple y efectiva administrar los procesos que se estén ejecutando actualmente en el servidor.
Soy un zorrinito administrable.
Hoy mismo me crucé con un post de la serie de Damn Cool Algorithms, una serie de posts del blog de Nick Johnsonz, en donde explica determinados algoritmos de forma relativamente simple. Hace falta conocimiento técnico, pero aún así los simplifica lo suficiente como para que sean entendibles. Y son realmente útiles, son de mucha utilidad y además, en cierta forma, bonitos.
Soy un zorrinito algorítmico.
Sé que muchos de nosotros nos encontramos en desacuerdo con el uso masivo de la tipografía Comic Sans, generalmente porque decimos que es inapropiada a mucho de los usos que se les da. No soy diseñador, y seguro que uno podrá dar infinidad de razones por la que es pecado hacer tu branding en esta fuente. Sin embargo, hay gente que piensa lo contrario y varios de ellos se han agrupado para dar lugar a Comic Sans Project, un Tumblr en donde se postea branding de distintas empresas, llevadas al Comic Sans. Debo confesar que está hecho con mucho cuidado, ya que la gran mayoría no se ven mal (aunque se puede argumentar que no es Comic Sans pura, ya que sufre de varias modificaciones). En fin, mirenló, diviértanse o lloren. Me lo trajo de regalo de reyes A Welsh View.
Soy un zorrinito poco serio.
A esta altura ya todos conocemos Dropbox, y quizá varias otras alternativas similares (como Live Mesh, Sugarsync, etc). En este caso alguien preguntó qué servicios similares existen que no suban su información a internet, y obtuvo una buena variedad de respuestas. Es útil cuando la privacidad es un problema o la legalidad de la información también lo es (por ejemplo, que cierta información no pueda alojarse fuera de los servidores de una determinada empresa). En casos así, estos otros servicios pueden ser muy útiles.
Soy un zorrinito sincronizado.
Cosmos es un proyecto opensource hosteado en Codeplex, que se trata de un sistema operativo completo construido en C#. Como tal, podemos deducir que no corre realmente de forma nativa en una máquina, sino sobre la plataforma .NET, pero creo que merece su atención como proyecto de extrema complejidad. No he visto el código, pero no dudo que mucho se podrá aprender de eso con solo mirarlo. Aparentemente, también hace utilización de extensas capabilidades de Visual Studio para un buen debugging del mismo, con lo que también es un buen ejercicio para aprender de esta herramienta.
Soy un zorrinito emulado.
UPDATE 3/1/2012 12:00 PM: Andrés agrega en los comentarios hablando de Singularity, un proyecto similar también en código managed (IL), pero no construido enteramente sobre eso, sino que tiene un kernel hecho en Assembler y un par de drivers hechos en C++. Aparentemente, este sí calificaría como un sistema operativo completo, ya que puede correr de forma independiente.
Para aquellos aprendiendo – o con ganas de aprender – a manejar Git como sistema de control de versiones, Git Magic es un documento que cuenta cómo utilizarlo de a poco, varios trucos y analogías de para qué sirve, de forma muy práctica y muy orientada a lo que uno quiera lograr.
Soy un zorrinito distribuido.