Archive: 2010
118 posts published in 2010

A black and white figure's thought-hive
118 posts published in 2010
A este punto del desarrollo de la tecnología, cualquier cosa puede ser víctima de un ataque de phishing. Para quién no lo sepa, el phishing es el engaño que se realiza para obtener información de uno que pueda ser útil para alguien más, sea para el motivo que sea. Por lo general se hace a través de email intentando obtener datos de uno para luego estafar de alguna forma (contraseñas, datos personales, etc.). Dado que un engaño puede realizarse por múltiples vías, incluso en algunas de las cuales podemos caer sin siquiera sospecharlo (pharming, content-injection phishing, etc.).
La gente de Dragonjar escribió un artículo sobre cómo se realiza el SMShing (también llamado Vishing), y también introducen una campaña muy interesante, llamada Trollear por una causa. Esta campaña en particular (algo similar a las historias que yo contaba de Anonymous [1], [2]) pretende que quienes quieran hacerlo se dediquen a la vez a estafar a los estafadores, quizá para hacerles perder el tiempo, quizá para molestarlos un poco nada más, quizá para decepcionarlos lo suficiente como para que su negocio no sirva, o quizá para entregarlos a la justicia. Sea como fuera, es una campaña muy interesante.
Soy un zorrishing.
El diseño de URLs es lo que primero se ve de una aplicación web. Es prácticamente nuestro punto de entrada a la misma, y de alguna forma nuestro mapa mental del sitio fuera del sitio.
Gracias a un tweet de @Xyborg y de @Woork me enteré de un artículo de Kyle Neath llamado URL Design en donde aborda el tema. Por suerte no es una consideración general sino que toca muchos puntos interesantes, como por ejemplo, de qué forma plantear determinadas jerarquías, de qué forma presentar una dirección si se trata de la misma información que ya se ve o de nueva información, como trabajar con el historial y las nuevas funciones de HTML5, etc.
Pero lo más importante es que nos provee un criterio muy interesante sobre la forma en que las URLs deben ser construidas para representar algo fácil de recordar y algo representativo de la información.
Como extra y relacionado, que también me pareció muy interesante, es la forma en que se debe planear para evitar conflictos de URLs entre contenido de usuario y funcionalidades que actualmente no existen en el sistema. ¿Cómo planear a futuro? Acá está la pregunta: How do sites prevent vanity URLs from colliding with future features? Las respuestas son más que curiosas.
Soy un zorrinito universal.
Gracias a un tweet de Woork me enteré de un proyecto que actualmente forma parte de Google Labs llamado BigQuery.
BigQuery es la posibilidad que nos ofrece Google de utilizar su capacidad de tratamiento de grandes cantidades de información de una manera similar a cómo haríamos con tablas SQL. El problema en este caso es que no se trata realmente de una base de datos relacional, con lo que tenemos que tener cierto tratamiento especial con los datos. La entrada y la salida del mismo por ahora será a través de texto (CSV para importar datos, JSON para obtenerlos), y el lenguaje utilizado es muy similar a SQL, con algunas pequeñas modificaciones y limitaciones.
Tenemos también la posibilidad de integrar la API de BigQuery a nuestros sistemas, si es que podemos sacar provecho de eso, y sin duda utilizarlo de forma programática. Así tendremos la posibilidad de analizar gigabytes o terabytes de data con el poder de Google, instantáneo. No dudo que en el futuro esto logrará mayor funcionalidad y características que puedan llegar a convertirlo en un sistema de datamining muy poderoso. Aún no, pero no creo que estemos lejos.
Soy un zorrinito con muchos datos.
Hace un tiempo ya que tuvimos un link de introducción a HTML5, como para saber de qué se trataba, y por supuesto, el tiempo ha pasado y esta nueva tecnología se ha vuelto mucho más popular. Lo bueno es que ya mucho del mismo es aplicable a los navegadores actuales, por lo que no tenemos exactamente que esperar a que el estándar sea totalmente aprobado. Al menos no si es que deseamos estar en lo último y aprovechar sus bondades.
Pero lo que es actualmente aplicable y lo que no podemos verlo en un buen artículo de InfoWold llamado How to use HTML5 on your website today, para poder adaptarnos a las nuevas capacidades. Podemos también hacer un repaso rápido a sus características gracias a An Introduction to HTML5, o ver su historia (que realmente es interesante) en A Brief History of Markup, o repasar básicamente de qué se trata HTML5 y en qué forma es importante, bajo un artículo del mismo nombre: ¿Qué demonios es HTML5 y por qué debería importarme?
Por último, y si es que estamos listos para poner manos a la obra, tendremos que tener a mano una buena cheat sheet, para no perder de vista las posibilidades que tenemos, y saber bien de qué forma debemos utilizarlas, y utilizar un código de reset HTML5 para que todos los elementos se comporten de la misma manera (aunque siendo sinceros, esto está más relacionado con CSS3).
Recuerden que aplicaciones HTML5 sobran, sientansé libres de explorar las que ya están en el mercado, que también son una muy buena fuente de aprendizaje.
Soy un zorrinito HTML5.
Gracias a JH me llega esta interesantísima presentación sobre un ámbito algo descuidado por lo general del desarrollo web: la parte programática de la interfaz. En esta presentación llamada Scalable JavaScript Application Architecture, Nicholas Zakas nos presenta una arquitectura modular extensible, en donde cada módulo independiente solamente conoce el sandbox en el cual interactúa, aislado de todos los demás módulos, y sin siquiera conocer cómo es la aplicación web en la que está funcionando.
Parecería que esto no aplica en entornos en donde los distintos módulos tienen que reaccionar frente a acciones realizadas en otros módulos, pero bajo el ejemplo de Twitter, se nos explica cómo es que los módulos pueden registrarse para afrontar cambios cuando sea necesario, de una forma bastante desacoplada.
Tengan en cuenta que el señor Zakas es ingenierio de frontend de Yahoo!, con lo cual, estamos hablando de alguien que tiene a su cargo una página con mucha funcionalidad y mucho trabajo de performance y desarrollo. Por supuesto, tampoco dejen de ver el resto de sus presentaciones, igual de interesantes.
Soy un zorrinito javascript.
Hace poco hablábamos de determinadas herramientas de seguridad que están disponibles para nosotros a lo largo y lo ancho de la internet. Pero además de eso, debemos saber utilizarlas.
Una de las herramientas de seguridad más potentes que hay es Metasploit, que como toda herramienta poderosa, es lo suficientemente compleja como para que no cualquiera la sepa manejar. Es por eso que la gente de DragonJar nuevamente hace su aparición, esta vez ofreciéndonos un Curso Completo de Metasploit en Video. Sin duda un must-watch para cualquier persona que quiera dedicarse o interiorizarse en la seguridad de sistemas informáticos.
Soy un zorrinito seguro.
Gracias a un interesante post que me compartió el kangrejo, estuve leyendo un poco sobre las diferentes licencias de software que están por ahí. El artículo en cuestión es de OnSoftware, y el artículo se llama El Software libre y las licencias de uso.
Me resultó realmente muy curioso (y de hecho, no lo sabía) que una licencia de software libre no significa que seamos libre de utilizarla para cualquier proyecto. Por ejemplo, la licencia GPL nos obliga a liberar todo código en donde está utilizada esta licencia con esa misma licencia, con lo cual, si no fuera porque jQuery tiene también la licencia MIT, todo lo que hiciéramos con esta librería tendría que estar publicado como open source.
Wikipedia tiene un buen artículo sobre Comparison of free software licenses, que nos explica con cuáles licencias podríamos utilizar software en nuestros proyectos.
Recuerden que free software no es lo mismo que open source.
Soy un zorrinito licenciado.
Well, face recognitions systems are not actually the last thing in technology, but still may be something new for us who couldn’t have a grasp of it and try it out in our own code. Of course, maybe we’re not fancy enough to come up with an algorithm out of ourselves and may just have ideas to use it, not to develop it.
For us then, we can go ahead and try Face Detection in any language, a blog post from Tukiun referring to OpenCV, the Open Computer Vision library that will allow us to make image processing something simple. It has been ported to different languages so it is sure that some of them will be suitable for us.
I’m a recognized little skunk.
Está de moda últimamente hablar de la computación en la nube (y no es para menos, ya que realmente propone un cambio interesante en la forma en que se mantiene el software). Lo más común para esto son servicios en donde podemos alojar nuestros sistemas con más o menos control de la plataforma, pero pocos de ellos se han centrado solamente en los datos.
Database.com es un sistema online que nos permitirá crear una cuenta para comenzar a utilizar bases de datos on the cloud. Lo mejor de todo esto, es que para comenzar, siempre y cuando no exceda cierta cantidad, será gratuito. ¿Qué mejor que eso? (Que sea todo gratuito, lo sé, pero hey, alguien tiene que mantenerlo.) Cabe aclarar que con nuestra cuenta tendremos también la replicación automática (por supuesto, estamos en la nube), backups, tuning según el uso, upgrades del sistema, y generación de los ambientes de desarrollo, test y training.
Sepan también que esta gente es la misma que desarrolló SalesForce, de forma que no se trata de ninguna tontería y sí estamos hablando de algo serio y confiable.
¡Gracias Kabytes por la información!
Soy un zorrinito en la nube.
Ayer hablamos un poco del anonimato en nuestra conexión y como podemos lograrlo gratis hoy a través de los servicios de Amazon, pero además podemos utilizar una gran variedad de herramientas de seguridad para asegurarnos que nuestra situación sea protegida, o por qué no, también utilizar estas herramientas para probar a alguien más. (Por supuesto, siempre de forma legal ;) )
La gente de DragonJAR ha dispuesto varios links a un repositorio de herramientas de seguridad que se encuentra en pentest.fr/resources, yo les recomendaría que les den una mirada, y de seguro podrán encontrar algo que les sea de utilidad, incluso si no quieren testear seguridad de nada sino averiguar e informarse al respecto. Tenemos disponibles, además de herramientas, documentos, exploits y hasta código para disponer de él cómo mejor nos parezca.
Soy un zorrinito seguro.
Estaba leyendo algunas cosas cuando caí en el artículo de HackTimes sobre Anonimato en internet gratis durante un año, y tras leer de qué se trataba, realmente me pareció muy interesante. Lo explicaré en pocas palabras.
Básicamente, podemos contratar un VPS (Virtual Private Server) de Amazon y si nos mantenemos dentro de los límites de transferencia (que parecerían ser unos 15 GB/mes) este primer año lo tendríamos gratuito. Podemos configurar este VPS como un servidor proxy que utilizaremos a través de una conexión SSH (encriptada), lo cual significaría que toda nuestra navegación en internet sería detectada desde los servicios de Amazon (recordemos, Cloud Computing). Eso significa también que nuestro ISP no tendría acceso a la información que estamos enviando/recibiendo.
Pero mejor aún, y esto aplica para los que, como yo, últimamente han tenido problemas de conexión debido a problemas de proxies internos del ISP: estos problemas desaparecerían, porque todos estos pedidos ya no serían procesados por nuestro ISP, sino por Amazon.
Quizá yo haga el intento, no parece demasiado difícil. ¿Ustedes se animan?
Soy un zorrinito encriptado.
There are a couple of subjects in web design and web development that will never grow old. One of them is this one: rich text editing. At least until browsers and web standards include a way for rich text editing to be done on the client side, there will be custom implementations through JavaScript and HTML markup that will provide users of WYSIWYG editors.
So, Plug-ins for rich text editors on your website is an article with a nice collection of different plugins and options you may use to provide that functionality, but still there are many many options.
Which one are you closer to? Any specific advantage or disadvantage that plugin provides?
I’m a WYSIWYG little skunk.
Gracias a @smashingmag y a @breakingdev me entero de una serie de consejos para programadores sobre bases de datos. Es muy buena esta aproximación, ya que por lo general los programadores se enfocan más del lado de la lógica de una aplicación, quizá en cuanto a la arquitectura o al diseño de un sistema, y no tanto a la forma en la que se almacenan los datos para el mismo. Y cabe destacar, que muchas veces esta puede ser una diferencia enorme en cómo se comporta el sistema.
Para comenzar con un link cortito, comencemos con el Top 10 MySQL Mistakes Made by PHP Developers, que como su nombre lo indica, es un listado de errores comúnmente realizados por programadores web, y ciertamente son comunes. No todos están 100% directamente relacionados con la base de datos en sí, pero de alguna forma siempre impactan sobre ella.
Para continuar con un listado más detallado y explicado, Database development mistakes made by application developers, una discusión que en Stack Overflow surgió con la pregunta: qué cosas nuestros DBAs no nos perdonarían? Cabe destacar que esta pregunta está muy relacionada con What are the most common SQL anti-patterns?, que también se relaciona con errores comúnmente cometidos.
Ambas discusiones tienen una buena extensión y una buena cantidad de respuestas, muchas de ellas detalladas y explicadas con la razón de la equivocación y la forma de evitarlo.
¿Se encuentran culpables de alguno de estos errores?
Soy un zorrinito equivocado.
Muchos de los que estamos en el ámbito sabemos qué cosas hay que hacer para publicar un website. Más allá de las tareas de desarrollarlo, hay un montón de detalles extras a tener en cuenta en el momento de la publicación. Hablo de cosas como verificar la consistencia de los textos, verificar que no queden textos de prueba, verificar la ortografía, verificar que tenemos el uso correcto de las imágenes, testeos de seguridad, correcto linkeo de páginas… ese tipo de cosas.
Cuando uno lo considera seriamente, se dará cuenta que son muchas cosas a tener en cuenta. Por eso, la gente de AddedBytes (de la que ya hablamos antes – [1], [2]) ha publicado The Ultimate Website Launch Checklist, que pueden ver online o descargar, o directamente leer en BoxUk (el sitio original).
Dénle una mirada, muy seguramente descubran algún paso que no estaban teniendo en cuenta, y quizá sería buena idea tenerlo en cuenta para el futuro. O por qué no, usar la checklist completa. ¿Hay algún punto que quisieran agregar?
Soy un zorrinito publicado.
Ha habido mucho debate sobre Flash últimamente, más específicamente desde que los teléfonos móviles más famosos del mercado no lo admiten como parte de la interactividad que van a brindar. Por si fuera poco, no sólo no piensan admitirlos como parte del mundo móvil sino que Apple publicó una carta abierta sobre el tema, Thoughts on Flash, en donde exponen varias razones (muchas de ellas debatibles en mi opinión) por las cuales Flash no sería una buena idea para ningún dispositivo móvil en general.
Por supuesto, los usuarios no disfrutan de esto tampoco. Sabemos que gran parte de la interactividad en muchos sitios está basada en Flash (para bien o para mal), y que hay sitios que de no ser por Flash, no funcionarían. Parecería que, afortunadamente o desafortunadamente, Flash está para quedarse.
Tobias Schneider decidió aprovechar muchas de las ventajas que se puede lograr con JavaScript, SVG y otras tecnologías relacionadas, para a través de JavaScript renderizar archivos swf (Flash) y permitir su disposición e interacción en el navegador. Esta librería se llama Gordon (muy apropiado nombre).
Desafortunadamente esta librería no soporta todo tipo de interacción Flash aún, sino que de a poco está extendiendo la cantidad de características que soporta, por ahora parecerían estar cubiertas las versiones 1 y 2 de Flash. Pueden pasar a ver los demos, o leer las notas de compatibilidad.
Soy un zorrinito flash gordon.
Para aquellos que desarrollamos sobre lo que se llaman plataformas (como por ejemplo .NET o Java), sabemos que el código que nosotros escribimos no se compila a lenguaje de máquina realmente, sino que se compila en algún lenguaje intermedio que luego es interpretado para una mejor ejecución en la máquina apropiada sobre la que esté corriendo la plataforma.
El punto que muchos dejamos de lado es saber interpretar ese lenguaje intermedio. Este lenguaje muchas veces puede proveernos información muy válida sobre problemas de performance que puede sufrir nuestra aplicación, usos de memoria no liberados, o incluso de la forma en la que se realizan llamadas al sistema operativo.
Charles Nutter realizó una presentación llamada JVM Bytecode for Dummies (and for the rest of you all) que explica detalladamente cómo podemos iniciarnos en este mundo. él se enfocó en el bytecode de la máquina virtual de Java, pero esto es aplicable a otras máquinas virtuales y a otras plataformas también. Puede que al principio nos maree un poco con ejemplos algo complejos, pero luego la teoría va tomando color hasta ser bastante tangible y podemos entender cómo el bytecode realmente refleja nuestro código. Mejor aún, podemos directamente programar con bytecode y aprovecharnos de eso mismo.
Soy un zorrinito interpretado.
Imagino que ustedes se habrán emocionado tanto como yo al leer el título. Hacker Books contiene, entre otros, libros para hacker, y eso es verdad. Se supone que diseñado muy estilo a web 2.0, esta librería virtual nos permite acceso a cierta cantidad de libros que suelen ser de los mejores recomendados en el ámbito. Esperemos que con el tiempo ese criterio no cambie, ya que de verdad he visto muy buenos libros por ahí.
Como decía, no son los únicos libros. También hay muchos libros muy buenos sobre desarrollo, sobre entrepeneurship, sobre lenguajes específicos, sobre negocios. Están categorizados en distintos niveles, y están en distintos formatos, algunos digitales, otros en audio, otros en libros físicos para leer.
Disfruten su lectura!
Soy un zorrinito lector.
De parte de un pequeño artículo de web.desktop.life me enteré de un pequeño proyecto llamado jscoder, el cual es un pequeño IDE (no tan pequeño si lo vemos desde el iPhone) en donde podemos codificar JavaScript y ejecutarlo allí mismo. Por si fuera poco, también disponemos de la función de autocompletar código, por ahora solo palabras clave, pero en el futuro también habrán snippets de código para utilizar.
De ocurrir errores en la ejecución del código, el teléfono nos devolverá un mensajito de error explicando qué ocurrió, y por supuesto, el código está adaptado para que este “ambiente” funcione en este dispositivo, teniendo en cuenta la orientación, el click con los dedos (“tap”) y tantas otras cosas que, claro, podemos utilizar para aprender.
Personalmente no considero demasiado productivo el hecho de programar en un dispositivo móvil (ya sabemos que escribir es difícil, encima quieren programar?), pero no deja de ser algo novedoso y que en cierta moda está demostrando las capacidades de estos dispositivos.
Soy un zorrinito móvil.
Hace tiempo ya estaba comentando con un colega sobre la enorme cantidad de medidas que pueden tomarse para mejorar la performance de una aplicación web. Existen miles de factores involucrados, entre los cuales hay muchas configuraciones y tweaks que pueden hacerse al servidor, pero muchos otros tienen que ver con el código en sí mismo. Sí señores, estamos hablando de HTML, CSS y JS.
El problema en este punto es que un HTML mínimo puede no ser el HTML que nuestro generador de contenidos genera. Puede que el CSS sea automatizado también, o que nuestro diseñador o desarrollador HTML no esté pensando en hacer las cosas de la forma “más mínima posible”, sino realmente trabajando en hacer que algo se vea bien y esté bien codificado. No está entre sus prioridades escribir
background: url("image.jpg") repeat top left scroll;
en lugar de
background: url(image.jpg);
Ambos son equivalentes, pero la segunda es más corta y por tanto más eficiente. Pero nuestro desarrollador debe realmente preocuparse porque el desarrollo sea correcto, que la visualización sea consistente y que sea acorde entre navegadores.
Ni hablar de JavaScript, en donde la cantidad de optimizaciones, minimizaciones y mejoras puede ser realmente importante. Alguno quiere trabajar sobre JavaScrpt minimizado? Sin duda: no.
La alternativa a la que llegamos era la de tener dos versiones de la aplicación. La de desarrollo con código normal y la de producción. Una vez que desde la de desarrollo se hicieran pruebas y quisiera hacerse un release, solo teníamos que correr una serie de herramientas que nos permitieran tener una versión minimizada y optimizada del código, bajo el riesgo de que algo se rompiera en el proceso.
Pero ahora Google acaba de publicar un módulo que han desarrollado para Apache 2.2, llamado mod_pagespeed, el cual hace optimizaciones y cache en el momento de los pedidos, para optimizar los sitios web sin tener que modificar los archivos reales. Por supuesto, es altamente configurable, y podemos ver la gran cantidad de mejoras que puede realizar en el poco tiempo que tiene.
Google nos cuenta que ya está trabajando con GoDaddy para que todos sus clientes puedan utilizarlo, y con Cotendo para que esté disponible en su CDN también. Si ustedes no tienen la suerte de estar entre ellos, pueden bajarlo por cuenta propia desde la página del proyecto de PageSpeed, e instalarlo en sus propios servidores.
Soy un zorrinito acelerado.
We’ve already presented some tools ([1], [2], [3]) that allows you to easily have some feedback of what the users do at your site or web application, or how do you need to improve it to make it better for their user experience.
So, here is another tool that will help us measure that bit of the user that’s not so easy to see: MouseTrace is a tool that being installed on our website will track exactly what the user does with it’s mouse. Even if they don’t click, it is a good idea to keep track of it so that we can find out if our layout is somehow confusing the users.
I haven’t tried this myself. Have you? Are you going to? Please share your experiences.
I’m a tracked little skunk.
Alguna vez hablamos de dos sistemas (Uservoice y Votebox) que nos permitían obtener información de parte del usuario como ideas o propuestas para continuar con el desarrollo de nuestro sistema y entender sus necesidades. Sin embargo, quizá no sea del todo buena idea utilizar estos mismos para el reporte de problemas o para un feedback algo negativo sobre lo que los usuarios están encontrando. Ese tipo de cosas que “son como no deberían ser”.
GetSatisfaction es un sistema del mismo tipo, integrable desde su propio website, en donde los usuarios pueden loggearse de distintas formas (perfil de Google, Facebook, Twitter, etc.) para reportar problemas que estén encontrando en la aplicación. Más allá, podemos darles un feedback al respecto y que ellos continúen esa discusión basándose en nuestras respuestas. No hace falta que se dupliquen las respuestas innecesariamente, ya que un usuario distinto puede elegir la opción “Estoy teniendo el mismo problema” y automáticamente podremos ver cuántos son los usuarios afectados que están involucrados en este problema en particular.
No relacionado a la funcionalidad, quiero destacar lo novedoso de la presentación en la página principal de GetSatisfaction. Podrán ver que en la parte superior de la página hay una especie de rueda de la fortuna (Wheel of satisfaction, como ellos la llaman) con logos de distintas empresas que tienen historias de éxito. Podemos hacerla girar y cambiar la historia que estamos viendo.
Soy un zorrinito orientado a los usuarios.
Todos sabemos que cuando queremos avanzar en las tendencias tecnológicas, muchas veces debemos dejar atrás a una serie de usuarios que no quieren o no pueden actualizar sus plataformas. Para muchos desarrolladores web, Internet Explorer es hoy el problema de dar soporte a todos los posibles usuarios, más específicamente en las versiones antiguas de este navegador. (Según parece, todavía hay gente que utiliza la versión 5.)
Gracias a un tweet de @jmma me enteré de un script llamado Selectivizr (nombres 2.0 si los hay) que simula los selectores CSS3 para IE6, IE7 e IE8. Por supuesto, ya luego podemos utilizar CSS3 y librerías JavaScript con selectores CSS3 sin problemas.
En el fondo, sabemos que no es perfecto (vean la sección “You need to know”), pero está mucho más cerca de ayudarnos a avanzar sin dejar a muchos usuarios de lado.
Soy un zorrinito compatible.
Muchos de nosotros debemos pensar que la ingeniería social tiene mucho de talento innato, mucho de arte y mucho de particular. Por la forma en que muchas cosas se desarrollan en este área de la seguridad, creemos que hay realmente poco de reutilizable, exceptuando ciertos detalles técnicos, ciertas acciones que pueden desarrollarse a través del ámbito virtual.
Estas cosas son, por supuesto, fácilmente reproducibles y reutilizables, y deben de serlo cuando se trata de la utilización de ciertos exploits o de ciertas técnicas que necesitamos utilizar para que el usuario nos brinde información propia (por ejemplo, phishing, tab-nabbing, click-jacking, etc.).
Social-Engineer.org tiene muchísima información sobre este tema, sobre distintas aproximaciones y técnicas, y, lo más curioso, un framework de ingeniería social llamado de forma muy creativa Social Engineering Framework. Pero no sólo eso, sino que para asistir a la sección de computer-based social engineering hay herramientas muy conocidas, las cuales son:
Yo diría que todo esto es un must-read para un aspirante a testeador de seguridad.
Soy un zorrinito social.
Gracias a la gente de BreakingDev me enteré de una aplicación web llamada HTML Instant, en donde podemos comenzar a maquetear HTML instantáneo, viendo los resultados ahí mismo en donde estamos trabajando.
Lo bueno es que podemos ver los resultados de forma instantánea y sin mucho trabajo, podemos codificar al mismo tiempo que vemos nuestros errores para fácilmente corregirlos. No hay siquiera por qué cambiar de ventana. La aplicación de una sola página consta también de ciertos snippets pre-armados sobre los cuales podemos trabajar más fácilmente.
Por supuesto, también acepta CSS y JavaScript.
Soy un zorrinito web.
Hace un tiempo me crucé con un artículo que hablaba sobre HTML5 y la privacidad en internet. Si bien me pareció que era un poco exagerado, parece que muchas fuentes, incluyendo algunas bastante confiables como el NYTimes.
Pero en realidad no estamos hablando de un problema de HTML5, sino de la seguridad que los navegadores implementen para dar soporte a este nuevo estándar.
Todo en el fondo se trata de la utilización de más técnicas para el almacenamiento de información local en una computadora, que de una forma u otra puede ser utilizada (y de hecho, lo es hoy en día) para identificar gustos y tendencias de navegación en ciertas partes de internet, de forma que, por ejemplo, Google pueda anunciar cosas de nuestro interés, incluso aunque estemos viendo una noticia sobre algo que no está relacionado.
Una aplicación proof of concept de cómo se puede almacenar información casi-persistente (cuando se supone que no debería de serla) es EverCookie. Evercookie es una suerte de cookie que a través de distintos mecanismos de almacenamiento se permite persistir de forma prácticamente persistente, incluso luego de la limpieza de caché, cookies y otro tipo de limpiezas estándares que muchos de nosotros haríamos pensando que ya debería de haber desaparecido.
¿Ustedes creen que esto realmente tenga implicaciones en la seguridad? ¿Creen que HTML5 se convertirá más en un problema que en una solución?
Soy un zorrinito persistente.
Gracias al Twitter de @BreakingDev me topé con un artículo muy interesante llamado Get MySQL Replication up and running in 5 minutes. Creo que es realmente útil para novatos como yo en estos asuntos, ya que recuerdo mis pobres intentos de trabajar con replicación MySQL y pasar horas y horas intentando hacerlo trabajar, basándome en unas instrucciones mágicas que alguien que lo comprendía me pasó y yo solo las seguía ciegamente.
Por suerte el artículo es lo suficientemente explícito como para darnos a entender qué es lo que estamos haciendo, y lo suficientemente breve como para no hacernos perder tiempo e ir directo al grano.
Por supuesto, siempre podemos ir al manual oficial y checkear el capítulo Replication, en donde la primera parte está titulada How To Set Up Replication. Este es el que contiene toda la información que podamos necesitar sobre opciones extras o customizaciones que quisiéramos hacer.
Soy un zorrinito replicado.
Continuando con mi lectura del libro de Minsky, el capítulo 4 se titula “Conciencia”, y definitivamente trata sobre eso.
La primera sección del capítulo intenta definir lo que la conciencia es, por supuesto, fallando por el hecho de que “conciencia” no es más que una palabra describiendo algo que somos capaces de percibir. Al igual que nuestra mente, no puede ser lo suficientemente simple como para ser definidia por solo una palabra (o solo un proceso), de modo que Minsky deduce que la conciencia es de hecho la interacción de diferentes recursos mentales. él propone la idea de que nuestras mentes tienen un detector de conciencia que se activa cuando ciertos recursos están involucrados o activados. En esta idea podemos explicar comportamientos complejos inconscientes a la vez de comportamientos simples conscientes (y por supuesto, los opuestos también.)
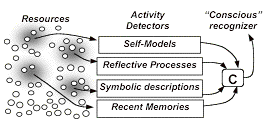
Minsky también describe cómo las redes de conectividad o redes neurales no pueden describir completamente los secretos de nuestra conciencia, pero las redes semánticas sí. ( ¿Qué tan de acuerdo se encuentra esto con la neurobiología?) Esto se debe a que nuestros procesos de conciencia deben tener al menos cuatro características:
Minsky también propone que existe otro detector que activaría ciertos recursos para hacernos concientes de un problema específico que debemos resolver cuando el comportamiento instinctivo no lo resolvería.
Luego trata sobre nuestra capacidad de reflexionar sobre nosotros mismos como si fueramos espectadores del Teatro Cartesiano, un concepto similar a la metáfora de Sócrates de la caverna y las sombras en la pared. Sin embargo, el teatro cartesiano es más una idea de Daniel Dennet, y podría ser descripta brevemente como si nuestra conciencia fuera un espectador en un espectáculo en donde diferentes partes de nosotros mismos son los actores.
Finalmente, Minsky explica la idea de _cerebros _reguladores y detectores. Estos cerebros podrían ser meta-mentes que interactúan como si el mundo exterior para ellas fuera la información que pueden obtener de nuestro cerebro real. Una especie de una mirada interior, que podría permitirnos alcanzar más planos abstractos fuera de la experiencia del mundo real.
Una cuestión curiosa es que Minsky explica que tenemos seis niveles de cerebros internos, lo que corresponde con los distintos niveles de conciencia que los humanos tienen: instinctos, deliberación, reflexión, reflexión del ser-propio, y reflexiones de la conciencia propia. No ha entrado en detalle sobre ninguno de ellos, pero realmente encuentro interesante el hecho de que ya he leído al respecto habiendo estudiado hace mucho Kabbalah y el árbol de la Vida como un mapa para la mente humana, en donde los seis sephiroth inferiores (Yesod-Hesed) representarían seis niveles de conciencia huamana. Quizá sea solamente casualidad, pero intentaré volver a esto después en más detalle.
Going on with my reading of Minsky’s book, chapter 4 is titled “Consciousness” and it definitely treats about that.
The first section of the chapter tries to define what consciousness is, of course, failing as in fact “conscience” is nothing but a word that describes something that we are able to percieve. As our mind, it can’t be so simple as to define with just one word (or just one process) so Minsky states that consciousness may be in fact the interaction of different mind resources. He proposes the idea that our minds have a consciousness detector that is activated when certain resources are activated. In that idea we can explain for unconcious complex behavior and conscious simple behavior. (Of course, also the oposite.)
Minsky also describes how neural or connectivity networks cannot fully describe the secrets of counsciousness, but semantic networks can. (How aligned is this with neurobiology?) This is because our counsciousness process must have at least four characteristics:
Minsky also proposes that there is another detector which would activate certain resources to make us conscious of a specific problem that we need to solve when instinctive behavior would not solve the problem.
Then he treats our self-reflection as if we were spectators of The Cartesian Theater, somewhat alike Socrate’s metaphor of the underground den and the shadows on the wall. However, cartesian theater idea is mostly from Daniel Dennett, and could be briefly described as if our conscience was a spectator in a show were different part of ourselves were the actors.
Finally, Minsky explains the idea of regulator and detector brains. This brains could be meta-minds that interact as if the outer world for them was the information they could get from our real brain. Some sort of an inside-looking, that could prove for more abstract plans rather than real world experience.
A curious thing is that Minsky describes that we’ve got six levels of inner-brains, which correspond to different consciousness levels that humans have: instinctiveness, learning, delibering, reflection, self-reflection and self-conscious reflections. He hasn’t gone further in detail about them, but I truly find it amusing that I already have read that when studying Kabbalah and the Tree of Life as a map to human mind, where the lesser six sephiroth (Yesod-Hesed) would represent six differents levels of human counciousness. Maybe was just chance, but I’ll try to get back to this later with further detail.
Otro post de jQuery, pero realmente vale la pena porque nunca nos dejamos de sorprender de las cosas que podemos hacer gracias a este framework. En este caso, para aquellos que quieran conocer exactamente cómo es que funciona o cómo es que efectúa ciertas tareas, se habrán encontrado con la complicación de que realmente es complejo en su funcionamiento interno. Para ello, la página de jQuery Deconstructed nos permite una vista más semántica y fácilmente entendible de sus funcionamientos internos. Si es que estuviéramos interesados, esta misma gente ha creado varios instructivos del interior de Prototype y de Mootools, otros frameworks bastante conocidos también.
Un trabajador tiene que conocer sus herramientas, cierto?
Soy un zorrinito javascript.
Tanto para probar un diseño o como para probar un website o aplicación web, ya hemos hablado de varios sistemas que nos permiten evaluar qué tan eficiente es nuestro diseño (recuerdan el link de Usabilia?). Hoy tenemos dos más muy similares, basados en la prueba de los cincos segundos.
Al usuario que va a efectuar la prueba, se le muestra un screenshot de nuestro website o nuestro diseño, y luego de eso él tiene que escribir las 5 primeras cosas que recuerde haber visto. Por supuesto, nos permitirá identificar fácilmente así qué elementos son los que realmente llaman la atención del visitante al primer momento. Y sabemos que si ganamos la atención en ese primer momento, hemos tenido éxito.
Por un lado tenemos a FiveSecondTest, en sus versiones paga y gratuita. Esta aplicación es de la gente de UsabilityHub, que ya tienen una serie de productos para la medición de la usabilidad de aplicaciones web, incluyendo también a NavFlow y a ClickTest.
Por otro lado está Clue, un servicio gratuito muy similar, en donde solo podremos probar aplicaciones web.
Soy un zorrinito probado.
Alguna vez hablé sobre un sistema que nos permitía buscar imágenes que contuvieran ciertos colores. Pasaron los meses y ya se convirtió en algo común que todos podemos hacer a través de Google Image Search. El buscar imágenes similares también es algo que podemos hacer, también desde Google Image search.
Pero cuando tenemos una imagen, cómo la utilizamos sin palabras para buscar en donde se encuentra? O para buscar imágenes similares?
Entonces es cuando queremos hacer image reverse search, es decir, buscar desde imágenes, o buscar imágenes similares.
La web de GazoPa (gracias @baldosin) nos permite hacer esto, subiendo una imagen, linkeando una desde otra web, dibujando, usando la cámara web, o introduciendo palabras clave que creemos están relacionadas.
Eso de dibujar es muy similar al software imgSeek para Linux (también gracias a @baldosin), que nos permite utilizar esta funcionalidad de una forma más personal.
Finalmente, mi preferido es TinEye, que a mi parecer me ha dado mejores resultados y parece que está creciendo.
Soy un zorrinito rastreador.
Gracias a DN pude checkear la web de ZingChart, un producto que nos proporciona la posibilidad de generar gráficos interactivos a través de datos JSON. Toda esta interactividad puede lograrse a través de AJAX, permitiendo una buena experiencia del usuario y una riqueza gráfica interesante.
Más allá de las características del producto (que son muchas), hay dos a destacar. La primera de ellas, es que ahora nos provee la posibilidad de utilizar su versión HTML5 cuando sea posible, permitiéndonos de otra forma volver a Flash. Comparen ustedes mismos y vean las diferencias de velocidad y tamaño.
La segunda característica es que a pesar del precio que tiene este producto (algo caro en mi opinión personal) es que podemos bajar la versión gratuita, totalmente ilimitada en su uso permitido, y la única contra que tiene es un link al sitio original y un textito que dice “Powered by Zing Charts”. Yo creo que vale la pena, no?
Soy un zorrinito gráfico.
Si ustedes han estado trabajando en análisis de algún sitio, ya sea por cuestiones de seguridad, curiosidad o investigación, muy seguramente habrán encontrado que analizar el JavaScript luego de que se comprime lo mayormente posible es un dolor. Por supuesto, sabemos que sigue siendo JavaScript válido porque se ejecuta, pero lo que nos falta es una forma de poder leerlo de forma simple.
JavaScript Beautifier se encarga de eso, toma nuestro input y lo convierte en JavaScript fácil de leer. No sólo eso, hay varias sugerencias extras al final de la página, pero si preferimos no hacer caso a ellas, el beautifier funcionará siempre online. Dice también de-obfuscar los crípticos códigos generados por JavaScript Obfuscator.
Soy un zorrinito arregladito.
Buscando una herramienta en específica me di cuenta que Microsoft dispone de una sección para todas las herramientas extras para .NET, llamada .NET Framework Tools. Me pareció que había muchas cosas interesantes para los que trabajamos en ese entorno.
Todas estas herramientas ya están incluidas en el entorno de Visual Studio. Por ejemplo el Assembly Binding Log Viewer. Gracias a él sabremos cuando no se encuentra una librería, en donde fue que se buscó. SqlMetal nos permite regenerar los archivos de DataContext de LinQ to SQL. GacUtil nos permite administrar el Global Assembly Cache.
Y hay más, por supuesto, muchas de ellas habrán encontrado su camino dentro del entorno visual, pero nunca está de más conocerlas.
Como extra y no relacionado les dejo una infografía sobre todos los personajes de Hanna Barbera, una curiosa infografía. Con gusto linkearía al Flickr de Juan Pablo Bravo (el autor) pero lo ha hecho privado, junto con otras infografías de ese estilo.
Soy un zorrinito útil.
En el momento en que una aplicación web es publicada, es muy importante que podamos tener algún tipo de feedback o resultados de opinión de los usuarios mismos. No solamente nos brindarían información sobre qué fallas han detectado (lo que, por supuesto, esperamos que sean las menos posibles) sino sobre nuevas ideas y posibles caminos que esta aplicación podría comenzar a transitar. Pero el proceso de toma de esa decisión es algo difícil.
¿Por qué no dejarle este trabajo a otra aplicación web 2.0? Estoy hablando de UserVoice, una web de valorización de ideas en donde cada persona puede publica su propia idea y/o votar por ideas de los demás.
Para ver un ejemplo, pueden ver el sistema de UserVoice para HiTask, una web de task-managing de la que hablaré en algún momento.
En este sistema, uno tiene una cantidad de puntos limitados para utilizar, y uno puede cambiar esa valorización siempre que quiera, o recupera sus puntos cuando la idea que los tiene fue implementada o cancelada.
Dropbox tiene una aplicación similar llamada Votebox, aunque desafortunadamente tienen que estar loggeados para poder verlo (siempre pueden registrarse si lo desean). Realmente no sé si es un sistema tercerizado o si lo han hecho ellos mismos.
Soy un zorrinito con feedback.
Remember that link where I spoke about different algorithms? I made a quick reference to Pixel City. If you had the chance to see it, and furthermore, if you have had the chance to download it and test it yourself, you might have seen that for a really little binary executable we can get really great things.
That’s because of content procedural generation, this means that the data you see is not configured or saved anywhere, it is just created in the moment that it is needed, with a set of rules that make sure that the result is close as expected.
Of course, this isn’t something new, lots of games already make use of this technique and not even that, there are a couple of games made entirely on this fashion. You should check out .kkrieger, a 96k 3D full level FPS game. That’s right. 96k.
You should also check Synth, an almost 100% procedural generated game, where even the music is generated in real time.
There’s also a nice experiment with procedural animation and genetic algorithms called Creepy Crawlies. In this application, you can create a creature with a certain configuration of bones (fixed length), claws (points it can grab on to) and muscles (parts it can expand/collapse), and the genetic algorithms will make it evolve so it grows up to the best locomotion technique. The animation is done procedurally too.
I’m a generated little skunk.
En Juegos.MicroSiervos publicaron un pequeño artículo sobre un juego llamado SwarmNation. El juego es realmente simple, pero no por eso fácil. Dejenmé describirlo:
Cada jugador controla un píxel o un cuadradito, sobre un mundo de cuadrícula. En este mundo podemos movernos arriba, abajo, a la izquierda y a la derecha según nuestro antojo, excepto que ya haya alguien más ocupando ese puesto. A cada momento, el juego indica que se debe formar una cierta figura. Esta figura, por supuesto, requiere de más de un pixel.
Aquí lo interesante comienza. Tenemos que coordinarnos con el resto de los jugadores para poder formar esa figura, y en el tiempo limitado que esa figura nos ofrece. Aquellos píxeles que formen parte de la figura formada, sumarán puntos. Aquellos que hayan quedado fuera, restarán puntos.
¿Cómo nos coordinamos entre los distintos jugadores? Bueno, realmente no hay muchas opciones. Dicen en MicroSiervos que no hay comunicación entre los jugadores, pero tenemos una herramienta: si presionamos la barra espaciadora, nuestro píxel se volverá naranja un momentito, como una forma de llamar la atención.
Yo lo estuve jugando un rato y es realmente difícil interpretar sólo desde los movimientos de los jugadores quiénes son los que emprenden nuevas figuras, quiénes prefieren comenzar, quiénes deciden quedarse para acomodar los detalles al final… y lo peor, la gente a veces cambia sus estrategias. Realmente es un juego difícil. Y por si fuera poco, uno mismo tampoco está seguro de cuál es la mejor estrategia para ganar.
La gente de SwarmNation tiene una cuenta en Twitter, en donde cuentan, por un lado, que los servidores están teniendo mucha carga últimamente y por eso puede que el juego no comience para nosotros. Por otro lado, también cuentan que consideran esto un juego interesante y de alguna forma un experimento social. Por si fuera poco, también postean cosas curiosas al respecto, como el caso en donde un píxel se sacrificó por otro, o la primera vez que los píxeles formaron una espiral (posiblemente una de las figuras más difíciles, require mucha coordinación).
En fin, pruebenló y me cuentan cómo se llevan con sus desconocidos cooperadores.
Soy un zorrinito colaborativo.
Dejando de lado a Google Closure, una herramienta de la que hablamos hace tiempo, hay algo que a muchos otros nos interesa al momento de programar: la forma en la que el código se ve. Por supuesto, más allá de ese extraño gusto por un código artísticamente elaborado, hay ciertas líneas que podemos seguir para que no sólo sea más bonito, sino más fácil de leer, interpretar y más eficaz.
Google vuelve al rescate como más de una vez lo hace, compilando públicamente su manual de estilo para codificación JavaScript. Este manual, llamado Google JavaScript Style Guide, nos provee de información extra sobre cada punto. Por ejemplo, sabían que además de ser más difícil, si una variable no está declarada con var, es puesta en el scope global? [link] Yo no. O cómo utilizar la clausuras de funciones para evitar memory leaks.
Está lleno de información interesante para el programador web.
PD: Como extra, pueden checkear el proyecto en Google Code sobre estilos de Google, para distintos lenguajes.
Soy un zorrinito JavaScript.
Validation is an essential part of any application. We need to check that the data entered is in the range of the set of data we can handle. And not only security purposes, but also to make sure that is is into what we can process.
Not so long ago, I had to make a very common validation: Alphabetic Characters. Most of us developers would have just created a regular expression against the set A-Za-z or maybe using another set like \w. Well, this does not always gives us what we really want.
In my case, I had to validate for more than just A-Z. This is, my application should allow for different languages where the alphabet was extended from the basic Latin 26-letters.
Sure, I could add the accented vowels. á, é, í, ó, ú, á, é, í, ó, ú. Well, that’s the acute accent. We have the grave one: à. We have the circumflex: â. Diaeresis: ä. Oh, wait. They’re even more. Suddenly, too much to remember or to manually write.
And not only vowels. It seems that consonants can also be accented. ý. ñ. š. ç.
Oh, there are even more letters. In German, for example, the “ss” letter combination evolved to ß. Those are ligatures: œ. þ. æ.
These are all, believe it or not, part of the Extended Latin Alphabet. So, if I wanted Johann Strauß, Kurt Gödel or Maria Skłodowska (later known as Mrs. Curie) to have a user in my application, I needed to allow this type of entrances.
Some languages do provide a tool for that. For instance, Perl provides the \X operator. This matches any unicode character. Anyway, this is a little more than we want to actually achieve.
Other tool languages provide is the \p{} and \P{} operators. This goes for Perl and .NET. I think Java also does. More information on these special features can be read at the Unicode section of Regex Tutorial.
However, if you’re trying to have a rich web 2.0 application, then you need to have this working in JavaScript too. Of course, server side validations need to be made, but still, a rich user experience demands that we do not wait to go to the server until we give the user a “Invalid name” message or something alike.
JavaScript does provide support for the \uXXXX operator to match a specific unicode codepoint. Knowing that, I made a quick look trought the Unicode Block Listing, and gathered all those points that where part of the Latin or extended Latin alphabet. Here’s what I found:
In case you wonder why the range Latin-1 Supplement leaves out the \u00F7 codepoint, it’s because it is a division symbol.
Ok. Making this all one RegExp (I added a space at the end, that is on purpose):
var regex = new RegExp(/^[\u0041-\u005A\u0061-\u007A\u00C0-\u00F6\u00F8-\u00FF\u0100-\u02AF\u1E00-\u1EFF\u2C60-\u2C7F ]+$/);
Let’s simplify it a little bit (\u00FF and \u0100 are consecutives, we can include them in one single range).
var regex = new RegExp(/^[\u0041-\u005A\u0061-\u007A\u00C0-\u00F6\u00F8-\u02AF\u1E00-\u1EFF\u2C60-\u2C7F ]+$/);
And there it is! You can try it out at the JavaScript Regular Expression Tester!
By the way, this expression should work on other languages as well.
En un artículo de Added Bytes me encontré linkeado esta colección de patrones de pantallas, llamada 12 Standard Screen Patterns, del blog de Designing Web Interfaces. Esta gente se dedica a postear información muy interesante sobre cómo hacer más fácil e intuitiva, a la vez de innovadora, la experiencia usuario-máquina a través de distintas visualizaciones, herramientas, técnicas y aproximaciones.
En este caso, se trata de una colección de pantallas que amoldan la información de acuerdo a las acciones que se quieren realizar sobre la misma. Por ejemplo, la disposición de una página de búsqueda no será para nada parecida a la de un formulario (incluso aunque técnicamente, la búsqueda sea un formulario), o de un wizard. Para más información al respecto, aquí tenemos otro listado de patrones de diseño visual.
Para que el mundo mobile tampoco se quede afuera, acá hay un artículo sobre iPhone Application UI Design Patterns, con algunos consejillos sobre cómo diseñar visualmente una aplicación para estos teléfonos.
Por último, la página de Paul Hibbits está llena de recursos sobre usabilidad y diseño de interfaces. Hay una sección en especial sobre los patrones. Muy interesantes y completos para ver.
Soy un zorrinito user-friendly.
De parte de Diego me enteré de esta Tabla Periódica de elementos HTML, que pueden ver funcionando aquí, en donde están presentes los 104 elementos que actualmente forman parte del draft de HTML5. Si fuera un simple listado no pasaría de curiosidad, pero no solamente podemos verlo y hacer click en cada elemento para tener una breve descripción y luego un link a la especificación del mismo… sino que podemos además tomar una página cualquiera y ver qué uso de estos elementos se está haciendo en vivo y en directo para esa página.
De amante de las autoreferencias que soy me pregunté qué pasaría si esa misma página verificara esa misma página. El resultado fue el siguiente: HTML, body, un meta, un title, un label, un form, un input, un button. Luego un par de h1, un par de h2, una tabla, 9 filas y 162 celdas (los elementos). 109 ul y 248 li (epa!), junto con 109 párrafos. 5 scripts, 5 links y… 245 anchors con 338 divs.
Lo curioso es que a partir de un análisis así podría llegar a entenderse más o menos qué funcionalidad tiene esta página. Podemos deducir que tiene una única función (o eso parecería), por tener un sólo form y un solo campo de entrada. Parecería además que por tener una tabla y una cantidad similar de celdas y elementos li/a, podemos pensar que esta página muestra información relacionada con una cantidad de elementos, y los anchors están presentes para cierto tipo de interactividad. Sin duda, una web 2.0, con mucha información pequeña y algo de interactividad.
Soy un zorrinito elemental.
Brad Williams made available a great slide presentation at Wordpress WordCamp 2009 in NYC. It is called WordPress Security, and it’s really complete explaining about certain spam techniques or hacking tips on Wordpress. Of course, those are things that can be avoided and he tells us how.
Not only that, but he provides with different plugins that we can use to test and check our WordPress site security. Those are:
Of course, he provides a lot more of information and resources to check out.
I’m a secure little skunk.
Gracias al blog de Thalskarth’s Maëlstrom (cuándo podré escribir eso sin copy-paste?) me enteré de un proyecto interesante que se está desarrollando. Dicho proyecto se llama TabCandy y hay un video explicativo al respecto que podemos ver aquí: An Introduction to Firefox’s TabCandy.
Recomiendo ver el video completo. Al comenzar a verlo pensé que se trataba de un plugin más que mejoraría el manejo de los tabs, uno más de tantos. Sin embargo, la idea va mucho más allá. Si recuerdan el concepto que mencionábamos hace un tiempo sobre Cómo trabajar con distracciones, de readquisición de contexto, el agrupamiento visual y localización espacial de conjuntos de tabs nos permitiría fácilmente enfocar nuestra navegación en distintas tareas. Por ahora tenemos algo similar si es que utilizamos distintas ventanas y tabs dentro de dichas ventanas (cosa que muy seguramente podamos hacer más fácil en Chrome que en Firefox).
Pero este proyecto va más allá. La posibilidad de crear y etiquetar conjuntos, buscar páginas entre todas o el contenido de las páginas. La posibilidad de compartir, o de que varios usuarios remotamente hagan una misma navegación. La posibilidad de tener conjuntos de conjuntos de tabs, la posibilidad de asignarles colores, u otras personalizaciones propias. La posibilidad de interactuar con otros usuarios, o incluso recomendar otros tabs que podrían sernos útiles basados en nuestra selección actual.
Las posibilidades son muchas, y es un desafío lograr todo esto para que funcione rápidamente y con un bajo consumo de memoria (cosa que ha sido desde siempre el estigma de Firefox).
Soy un zorrinito en tabs.
Una de las tantas herramientas para checkeo de seguridad XSS hoy viene de la mano de los muchachos de Dragonjar. Según ellos lo mencionan, esta herramienta llamada X5S no solamente sirve para revisar si un sitio es seguro contra ataques XSS (cross site scripting), LFI (local file inclusion) y RFI (remote file inclusion). Sin duda algo muy interesante para los aficionados a la seguridad web, podrán probar este software como un plugin de Fiddler.
Como mencionaba, no es la única herramienta, ya que hay otras similares. No he podido probar esta ni tampoco AttackAPI, pero pronto me están esperando ambas para que logre poner mis manos encima de ellas. ¿Alguien que las conozca ha tenido buenos resultados?
Soy un zorrinito seguro.
Hola, sí, qué tal?
Cambié un poco el estilo de la sección de comentarios. Perdón por como estaba antes, incluso a mi me daba asco comentar. Ahora se ve un poco más bonito, voy a ver si en algún momento le habilito algo de edición más interesante.
Soy un zorrinito con estilo.
Sí, ya sé que suena demasiado geek, pero cualquiera que pueda abtraerse un poco del algoritmo en sí, de qué haga o cómo lo haga verá que de alguna forma su “orden” logra un algo extra que puede ser realmente hermoso.
Demostraciones tenemos miles, y la primera que encontré fue una comparación hecha sobre algoritmos de ordenamiento si es que generaran sonido. Su visualización gráfica también es atractiva. Pueden visitarlos en Sorting Algorithms: quite boring until you add sound effects, pero aquí tenemos otra bonita demostración gráfica del heapsort, quicksort, y radio del dígito más significativo.
Pero no todos son algoritmos de ordenamiento. También tenemos fractales, como la serpiente de Serpinski, un tetris-fractal. O por qué no, algoritmos genéticos, o usados para hacer arte, que es de todos modos muy hermoso.
Los dejo con el mejor de los ejemplos para mi gusto, que es la demostración de utilizar un algoritmo procedural para la creación de un paisaje nocturno. Vale la pena ver todo el video con toda la evolución del proceso: Pixel City.
Soy un zorrinito algorítmico.
Yo no tuve ninguna suerte con el concurso de How Strong Is Your Fu #2, y mucho menos todavía he podido asistir al Black Hat de Las Vegas. A pesar de eso, lo bueno es que esta gente ya ha dejado para descargar y husmear una gran mayoría de las cosas que se expusieron. Desde los Black Hat USA 2010 Archives podemos acceder a la distinta información de esta distinguidísima conferencia sobre seguridad informática.
Por supuesto, dudo que sea lo mismo que haber estado ahí y haber visto algunas cuantas demostraciones en vivo.
Muchas gracias a la gente de DragonJar que me acercó esta información, allí tienen un listado de todo también.
Soy un zorrinito seguro.
Yeah, yeah, I know that there are plenty of different web hosters that offers great deals for free. But, wouldn’t you like to have some kind of search between them, so you can choose the one that goes best according to your preferences?
Now we have Free Web Hosts, a searchable index for different offered services, all of them free, and upgradable with different options.
I’m a free online little skunk.
Un post muy interesante titulado Rethinking interruptions, de John D. Cook, habla de cómo las distracciones no son intrínsecamente malas para el trabajo, sino que, al contrario, en cierta forma son totalmente necesarias e imprescindibles para la solución de problemas. Sin embargo, ¿hasta qué punto se pueden mantener estas sin que afecten negativamente el trabajo?
él distingue muy bien el efecto que es malicioso en las interrupciones, que no es cuánto tiempo a uno lo distraiga, sino qué tan lejos deje la mente del estado original en donde estaba antes de ser distraída. él llama, tomando un término de Mary Czerwinski, readquisición de contexto al proceso que nos permite volver al estado original para poder seguir trabajando normalmente.
Esto es lo realmente interesante ahora: parece que la señorita Cerzwinski ha realizado un taller estudiando este fenómeno, cuyos resultados podemos ver en un broadcast de Channel 9 titulado Jon Udell and Mary Cerzwinski on interruptions, context reacquisition and spatial/temporal memory. Por si no fuera poco, parece que Microsoft se encuentra trabajando en una herramienta que nos permitiría facilitar este proceso una vez que terminemos con una tarea, por ejemplo, al finalizar una llamada telefónica, una conversación de chat o alguna situación que, por lo general, suelen sacarnos de la actividad que estábamos realizando en el momento en que las comenzamos.
Soy un zorrinito distraído.
Desde hace mucho tiempo que la gente de Dragonjar se ocupa de informar y educar sobre temas de seguridad informática, hacking, avances en tecnología y temas relacionados. No se quedan sólo en eso sino que a lo largo del tiempo han ido generando concursos, conferencias, discusiones, y participación de la comunidad.
Todo eso no es suficiente, y hoy comenzarán con su nuevo proyecto llamado Dragonjar.tv, un broadcasting para toda la audiencia interesada en esto sobre temas relacionados, que comenzará a verse hoy Miércoles 18 de Agosto, a las 20.00 hrs, hora de Colombia (GMT -5).
Les transcribo el mensaje que me han enviado informándome al respecto:
Con agrado les anuncio que por fin DragonJAR.tv estará al aire en vivo, **hoy Miércoles 18 de Agosto a las 8PM GMT -5 (hora Colombiana)** ... Pero.. ** ¿Que es DragonJAR.tv?**, DragonJAR TV es un programa de TV Online en los que se tratarán temas relacionados con la seguridad de la información, de forma amena, agradable y sobre todo DIVERTIDA. La idea del programa es llegar a la mayor cantidad de publico, sin importar el conocimiento que este tenga sobre las áreas de la seguridad informática, siempre aportando nuestro grano de arena a esta área y ayudando que el mundo sea un poco mas seguro. En DragonJAR.tv encontraras los consejos que necesitas para evitar ser víctima de los mas sofisticados fraudes en la red, pero también talleres prácticos en los que aprenderemos sobre las nuevas técnicas y herramientas utilizadas en materia de seguridad. Espero que este programa sea de su agrado, que compartas esta información con tus familiares y amigos, recuerda que la solución para muchos de los problemas que encontramos en la red es la EDUCACION, en DragonJAR.tv tendrán eso y mucho mas ;-) Visita www.DragonJAR.tv
Soy un zorrinito seguro.
Hace tiempo que vengo vigilando la página de Live Mesh Beta, un servicio de Microsoft que competiría contra MobileMe, el servicio análogo de Apple. Según parece, algo ha pasado a lo largo de la beta privada (que estuve esperando a que se hiciera pública) ya que parece que Live Mesh nunca saldrá de beta, sino que será directamente reemplazado por el servicio de Live Sync.
En el fondo, esto no es nuevo. Es una tecnología que Microsoft adquirió en el 2005, llamada FolderShare, y que luego pasó a formar parte del paquete de Windows Live. El servicio es similar al de Mobile Me, Dropbox y otros servicios similares, que nos permiten sincronizar archivos a través de la nube. Además, hay servicios similares, como el mismo Live Mesh que, según parece, también estuvo funcionando hace un tiempo y que también alguna relación tiene con Windows Sky Drive. Estos servicios ya están disponibles para todos los que tengamos una cuenta de MSN Passport. De no tenerla, simplemente podemos crearnos una gratuitamente y comenzar a disfrutarlos.
Soy un zorrinito en la nube.
Hace tiempo que se viene hablando de las bondades de HTML5, y varios lugares ya han aprovechado sus características para ofrecer algún servicio extra, como video de forma distinta, como otro tipo de campos de navegación, como una arquitectura más semántica… pero creo que esta es la primera vez que lo veo en su uso completo.
Ayer mismo me encontré con una noticia de DeviantArt anunciando la liberación de Muro, una aplicación web totalmente HTML5 para dibujar. Quizá más de uno recuerde Harmony, uno de los primeros sitios que mostró las cosas que se podían hacer con el HTML5 Canvas, pero Muro realmente lo utiliza mucho más allá. Por si no fuera suficiente, Muro nos permite el uso de layers, brushes, y filtros o efectos para las imágenes. Por supuesto, las imágenes también pueden exportarse.
Por supuesto, ya han hecho muy buen uso de esta aplicación.
Soy un zorrinito dibujado.
Hay sitios web que ya están comenzando a utilizar video HTML5 para distribuir su multimedia. Algunos de ellos son Youtube y Vimeo, pero tratándose de un estándar, el resto de nosotros no tenemos por qué quedarnos afuera.
Aparece entonces en escena un plugin de jQuery llamado jMediaelement (jme), que nos permite manejar los nuevos tags
Soy un zorrinito HTML5.
Hace ya mucho tiempo que los programadores web checkean sus markups con la herramienta de validación HTML de W3c, sus estilos con el validador CSS de W3c, sus sitios móbiles con dicho servicio de W3C y también el validador de feeds. Gracias a un tweet de jmma, me enteré que ahora W3C dispone de un servicio completo para verificar todo esto al mismo tiempo, llamado Unicorn.
Este servicio es tan fácil de utilizar como los otros existentes, y además es un poco más user-friendly, permitiéndonos con artimañas de interfaz solamente concentrarnos en lo que más nos importe.
Por supuesto, esto es parte de una campaña para que de a poco la web se esté acercando a los estándares, largo trabajo que aún se está llevando a cabo. ¿Qué pasará el día en que los navegadores dejen de aceptar páginas fuera del estándar?
Soy un zorrinito estandarizado.
Me enorgullece poder anunciar que desde hace un tiempo he tenido la oportunidad de trabajar junto con el equipo Doppler para un nuevo proyecto, algo que desde entonces se estaba formando llamado Doppler Reports (link). Este proyecto finalmente vio la luz y está activo públicamente desde el 27 de Julio. Permítanme contarles un poco más sobre eso.
Momento… ¿qué es Doppler?
 { :align-left}
{ :align-left}
Para aquellos que no lo conocen, Doppler es una herramienta de email-marketing. Es realmente compleja, pero explicándola en un vistazo rápido, es posible usarla para crear contenido de email online (basado en plantillas o editandolo manualmente), y enviarlo masivamente a una o más listas pre-cargadas. Sim embargo, hay mucho más para lo que puede utilizarse, y una de las grandes posibilidades que nos ofrece está en la capacidad de analizar la reacción del cliente a nuestras campañas de emails. Cuando uno tiene diez, quizá veinte, cincuenta o cien contactos, esto es algo que se puede hacer fácilmente con un listado de ellos. Uno verifica sus contactos, analiza quién abrió los emails enviados, quién hizo click en cuál link, y esa es toda la información que uno necesita.
Las cosas cambiaron mucho desde esa mañana del 2005. ¿Qué pasa cuando tienes mil contactos? ¿Y un millón? No, no estoy exagerando. Eso es parte de nuestro trabajo diario: mantener una herramienta que envía millones de emails. ¿Cómo obtenemos los resultados y los mostramos al usuario? La respuesta obvia es: Reportes.
Los reportes te darán toda la información resumida que necesitas sin tener que revisar cada uno de los contactos (porque, por supuesto, el sistema lo hace por tí). A medida que la tecnología evoluciona y que el comportamiento del cliente evoluciona a medida que el marketing evoluciona, nuestras herramientas deben evolucionar también.
Aquí es donde el Equipo de Doppler vio la necesidad de una aplicación de reportes totalmente nueva, para poder satisfacer muchos pedidos que nuestros clientes tenían para la versión anterior de la misma. Pero esta herramienta debía estar pensada para millones de emails, miles de usuarios, información en tiempo real y al mismo tiempo, reportes informativos y elegantes.
Y entramos en la escena. Tuve la oportunidad de trabajar junto con Juan Fazzini para diseñar una arquitectura que escalaría a medida que Doppler siguiera creciendo con todas las futuras características que obtendrá. Entonces, en una tarde de viernes, un pizarrón en blanco, una notebook como grabadora para todo lo que decíamos (ya saben, la documentación es importante), comenzamos a idear y pensar sobre cómo Doppler Reports trabajaría.
¿Cómo está diseñada la arquitectura?
 { :align-right}
{ :align-right}
Cada parte de Doppler funcionará como un módulo independiente, que puede tener varias instancias funcionando al mismo tiempo. Hay un módulo en especial que se encargará de interconectar a los demás entre ellos, pero estos módulos de interconexión pueden trabajar de forma independiente también.
Esto significa que ahora tenemos mayor tolerancia a errores catastróficos. Si un servidor deja de funcionar, las otras instancias de los módulos seguirán trabajando, manteniendo al sistema con funcionamiento normal. Los usuarios no se darán cuenta, apenas puede que noten una demora pequeña en la aplicación.
También significa que si tenemos mucha carga por uso intensivo, podemos crear nuevas instancias de un módulo y los módulos de interconexión automáticamente balancearán la carga.
Tener estos módulos ahí afuera no es poca cosa para la seguridad. La seguridad tiene que ser tan estricta como es posible. Por eso, desarrollamos un protocolo de comunicación que le permitiría a cada módulo verificar si el que llama al mismo es una aplicación autorizada y si está bien devolver datos a la misma. Si todo funciona bien, la llamada se realiza y los datos se devuelven. Si algo no sale bien, como si se provee un token de autorización incorrecto, nunca se sabrá qué pasó. Sabemos que esto no es particularmente transparente para los programadores, pero es lo más seguro que podemos realizar para prevenir intentos de hacking.
El resultado de esta característica es que, incluso cuando los módulos estén disponibles en Internet (no todavía, pero quizás en algún momento lo estén), no cualquiera puede acceder a ellos. Incluso si saben en dónde están o cómo llamarlos, ellos no harían nada hasta que los clientes le provean un token de seguridad auténtico.
También significa que las claves de seguridad para acceder a este módulo se pueden generar y, en el futuro, podría resultar en una API para ciertos módulos de Doppler que cualquiera (o algunos usuarios) podrían utilizar. _ ¿Imaginas crear una aplicación para tu propia empresa que automáticamente trabaje con los datos que Doppler generó para tí?_
Más que una decisión arquitectural, esto fue un desafío. Ya se sabe que estamos manejando toneladas de datos. ¿Cómo cargarlos rápidamente? ¿Cómo obtener una buena performance? Para eso, decidimos que algunos objetos trabajarían internamente como proxies, de forma que sólo se obtendría la información que se ve.
Esto significa que ahora al entrar a la pantalla de Resumen de Métricas para una de tus campañas, podrías ver (cuidado… se viene un listado grande):

*toma aire* ¿Saben cuánto tiempo le toma a Doppler Reports obtener y mostrar toda esa información? Menos de 5 segundos. Pongo énfasis en ello: Menos. De. Cinco. Segundos. Ese es el tiempo que me toma leer las primeras tres líneas de la página. Quizá cuatro, quizá cinco. Pero antes de que haya terminado de hacerlo, la página está completamente cargada y funcionando. Y debo aclarar, mi conexión a internet no se destaca por su velocidad.
Por supuesto, también usamos caching. Esto agrega una capa más de interacción hasta los datos, pero nuestro sistema de caching nos asegura que tengamos los datos listos para el usuario en el momento que los pida. Los datos de una campaña no cambian mucho, a menos que se acabara de enviar, por lo que, para la gran mayoría de los casos, podrías ver los datos de tu campaña tan rápido como cualquier otra página web.

Mencioné antes que Doppler ha comenzado a ser más y más complejo, y ahora está siendo diseñado de una forma modular. De esta forma, los módulos trabajan independientemente y a la vez, delegan responsabilidad en el módulo que sabe cómo resolver un cierto problema o cómo tratar cierto conjunto de datos. Tener un diseño modular es un aspecto terriblemente importante para cambios futuros. Le permite a nuestro equipo paralelizar el trabajo, y le permite a nuestro equipo (y a nuestra aplicación) crecer.
Esto tiene importantes consecuencias. Para el lado que el usuario logra ver, esto significa que muchas características estarán disponibles más rápidamente. Nuevas características, más mejoras, más robusto, más rápido, mejor. “Harder, faster, better, stronger.”, como Daft Punk recomienda construir el software.
Por supuesto. Estas nuevas características ya están disponibles para todos los usuarios que tengan una cuenta de Doppler. Si no tienes una, puedes crearte una de forma gratuita y probar el producto por tí mismo: http://www.FromDoppler.com/.
…Quería decir que considero un logro personal haber podido formar parte de todo esto. Intentamos lograr algo radical y hoy tenemos un producto radical. Creo que el Equipo Doppler está muy orgulloso de lo que han logrado. Yo ciertamente lo estoy.
Ah, y este post ha llegado hasta el blog de GetCS. Visitenló, puede que les interese.
I’m really glad to announce that since some time ago, I had the opportunity to work along with the Doppler team for a new project, something that since that time was evolving, called Doppler Reports. This project finally became active and working publicly on July 27th. Let me tell you a little more about it.
{ :align-left}
For those that are not aware of it, Doppler is a online email-marketing tool. It’s really complex, but explaining it just at a glance, you can use it to create email content online (template-based or editing it yourself online), and sending it massively to one or many of your pre-entered mailing lists. However, there is much more to it, and one of the big powers enclosed in such a tool is the ability to analyze the customer’s reaction to your mail campaigns. When you have ten, maybe twenty, fifty, or even a hundred customers, this is something you could easily do with lists. You check for your contacts, you see who opened the email you sent, you see who click on which link, and that’s all the information you need to go on.
Things have changed a lot in the business since that morning in 2005. What happens when you’ve got a thousand contacts. A million? No, I’m not exagerating. That’s part of our everyday work, maintaining a tool that daily sends millions of emails. How do we get results and present them to the users? The obvious answer is: reports.
Summarizing reports will give you the information youneed without having to scan for each of your contacts (because, of course, the system does it for you). And as technologies evolve, and as customer behavior evolves, and as marketing evolves, our tools needs to evolve too.
That’s where the Doppler Team saw the necessity of creating a new brand report application, in order to fulfill a lot of requests that our customers had from the previous version of our reporting tool. But this one would have to be thought for millions of emails, thousands of users, real time information and at the same time elegant and data-rich reports.
Then we entered the scene. I had the chance to work closely along with Juan Fazzini to design an architecture that would scale as Doppler would get bigger with all future features that it will get. So, in a Friday afternoon, a big white board, a notebook as recorder to keep track of everything we said (you know, documentation is important), we started brainstorming and dreaming about what Doppler reports would work like.
{ :align-right}
Every part of Doppler will work as a separated module, that can have many instances working at the same time. There is a special module which will take care of connecting all of the others between them, but these interconnection modules may work independently as well.
This means that we now have more catastrophic-error tolerance. If one server fails down, the other instance of the module will keep on working, and users will notice nothing, but maybe some little delay on the application.
This also means that if we have too much load, because of intensive use, we can just create new module instances and the interconnection modules load balancing will automatically take care of the load.
Having this modules out on the wild is no little thing for security. So, security had to be strong as possible, and we developed a communication protocol that would allow each module to check if the caller is in fact an authorized application and that it is ok to return data to it. If everything goes right, then the call is made and the results are returned. If something goes wrong, as like if you provided an incorrect token, you would never know what happened. This is not transparent at all for the end developer (and we know that), but it is as secure as it gets to prevent hackers.
This means that even when modules are out in the internet (not right now, but maybe someday), not anyone can access them. Even if they knew where they are and how to call it, it would just do nothing until clients provide an authorized token.
This also means that the keys that allow access to this module can be generated and in the future, the API for certain Doppler modules would be available for everyone (or just some users) to use. Do you imagine creating an application for your business that would automatically work with the data Doppler generated for you?
More than an architectural decision, this was a challenge. You already know that we are handling tones of data. How to load it quickly, how to achieve a high performance? For that, we decided to make some internal objects proxy-like, so that you would only get the information you request.
This means that you can now enter the dashboard screen summary report for one of your campaigns, and you would see (beware… long list coming):
*breathes for air* Do you know how much time takes to Doppler Reports gather and show all that information? Less than 5 seconds. Let me emphasize that: **Less. Than. Five. Seconds. **That’s what takes me to read the first three lines of the page. Maybe four, maybe five. But before I finished doing that, all the page is completely loaded and working. And I have to say, mine is not a premium connection.
Of course, we also use caching. This adds another layer of interaction until we get to the data, but our caching framework provides us with the ability of habing the data ready for the user right away. Campaign data does not change very often unless you have just sent it, so for most of the cases, you will be able to check your campaign data as quick as any webpage would load up.
I mentioned before that Doppler had started to become more complex, and is now being designed with a modular approach. In this way, modules work independently and at the same time, they rely responsibilities on the module that really knows how to solve a certain problem, or to treat certain data. Having a modular design is terribly important for future changes. It allows our team to parallelize work, it allows our team (and application) to grow.
This has great consequences. On the users side, new features will be available sooner. New features, new improvements. Harder, faster, better, stronger. (As Daft Punk suggests we build our software.)
Of course, this new features are available to all users that have a Doppler account. If you don’t have one, you can even create one free and try the product for yourself: http://www.FromDoppler.com/
…I just want to say that I consider a personal achievement having been part of all of this. We tried to do something radical, and we have a radical product today. I think that all of the Doppler Team is very proud of what they have today, and I sure am too.
Oh, and this post has made its way into the GetCS blog. Make sure to check it out.
A couple of days ago, one internet link surfaced between all of the popular ones for being one-big-and-for-all resource for online safety. This safety I’m talking about is not only the kind of safety where you want to protect your data, but the one where you want to protect yourself and your family. If you’re close to technology, and if you live part of your life online, this is surely something you must think of sometime.
SimpleK12 posted a resourcefull guide called Internet Safety Resources, where it covers different topics, as preventing online bullying, avoiding inappropriate content, how to deal with children in difficult situations, identity theft, internet addiction, online gambling, pornography, data security, viruses, browsers, fraud, phishing, gaming sites, hoaxes, forums, netiquette, online journalism and blogging, cellphones, social networks, download sites, P2P, copyright and piracy, plagiarism, laws, and further more. That big list I just mentioned is a quick scan I did on the titles of some articles.
So, quite complete, right? Between the articles, there are some resources which you may interact with, organizations available to help you with your doubts or personal problems, and even to take you as part of them. Make sure to be safe.
I’m a safe little skunk.
El título no es novedoso de por sí, todos sabemos que los intérpretes o compiladores de código se escriben también con algún tipo de código. A veces, y eso es lo que puede ser nuevo para nosotros, es en el mismo código. Por ejemplo, el famoso compilador de GCC está escrito en C.
Pero lo que quería mostrarles hoy es una característica de .NET no tan conocida, o al menos no tan utilizada, y se trata de la compilación de código on-the-fly, basado en el ejemplo muy bien explicado que pueden ver en el artículo de Rick Strahl, llamado Executing Dynamic Code in .NET. Dicha presentación explica (con buenos ejemplos y detalles) cómo sólo con una entrada de texto podemos generar las clases y métodos que serían representados por ese código. No sólo eso, sino formas alternativas de compilarlo, separándolo o no de nuestro dominio de aplicación, y cómo se pueden utilizar clases de scripting para ello.
Yo en realidad encontré eso mientras buscaba otra cosa, estaba buscando algo equivalente al famoso ClassLoader de Java. No sólo encontré un buen ejemplo, simple y claro llamado C# - Dynamic Class Loading, sino que encontré un muy buen artículo para aquellos que comenzaron en C# desde Java: C# From a Java Developer’s Perspective. Este es el famoso “C# vs Java” que muchas veces se menciona.
Soy un zorrinito dinámico.
Hace un tiempo me puse a investigar sobre cómo utilizar alguna técnica que me permitiera rankear contenidos. Es decir, tener algún feedback de parte de los usuarios para saber qué contenido gustaba más y cuál no tanto. “Copiémosnos de los grandes”, pensé yo, y busqué algún ranking de estrellas, al mejor estilo Youtube.
Encontré un plugin de jQuery llamado Star Rating, un sistema que basado en AJAX, y dos o tres imágenes, podemos tener un sistemita de ranking por estrellas muy simpático. Es muy personalizable y fácil de implementar, también muy fácil de acomodar según los distintos layouts que dispongamos para nuestro contenido, y finalmente, algo personalizable en funcionalidad también (por ejemplo, podemos hacer que muestre un promedio o un valor determinado, podemos hacer que sólo se pueda votar una vez o que se pueda cambiar el voto, o que se puedan votar varias veces, etc.)
Fue no mucho después que leí un artículo llamado Youtube Like Rating with jQuery & Ajax, y ahí fue en donde me dí cuenta que los grandes ya no utilizan el sistema de estrellas. Por si se dieron cuenta, Facebook tiene sólo un “Like” (o “Me gusta”, en español), y Youtube ahora tiene un “Like” y un “Don’t like”. ¿Por qué tan simplista?
La respuesta estaba en un artículo del blog oficial de Youtube, llamado Five Stars Dominate Ratings, en donde básicamente explican que de las 5 estrellas, rara vez alguien utilizaba la número 2, 3 y 4. Generalmente, si a alguien le gustaba un video, lo rankeaba como 5 estrellas, y si no le gustaba para nada, simplemente lo abandonaba o lo rankeaba con una estrella. ¿Y en el medio? Una minoría.
Y sobre ese mismo tema encontré un artículo muy interesante, también analítico de la gente de Steepster, Brewing a Better Rating System, en donde explican cuáles fueron las distintas aproximaciones que tuvieron para que la gente rankeara la información de su blog. Es interesante leer esta versión porque a la vez ellos creen que el sistema de sí/no no es del todo apropiado para expresar lo que uno piensa de un artículo, y entonces ellos permitieron una variabilidad en el puntaje.
¿Qué piensan ustedes? ¿Cuál sería la mejor forma de pedirle a alguien que opine, fácilmente, de un artículo/contenido que ustedes hayan generado?
Soy un zorrinito de feedback.
Quizá para muchos sea un concepto totalmente básico y muy simple de comprender, pero para aquellos que no lo tenemos tan asimilado, seguramente no estemos apreciando el importantísimo concepto que representa.
A/B Testing es una forma de probar las aproximacinoes de marketing de forma de poder tomar una decisión correcta con la aproximación final que va a hacerse al público en general. Muchas empresas grandes la utilizan para tomar decisiones, y se trata básicamente de probar distintas posibilidades, seleccionando siempre la que mejor resultados haya dado.
Adrián Paenza contaba en uno de sus libros una forma de ganar inversores. Decía que de una lista de emails de 130 personas les envíaba a 64 un mensaje que decía “mañana el dolar subirá su precio”, y a otras 64 “mañana el dólar bajará su precio”. (Eso suma 128, dejemos a 2 de lado.) Con 64 se habrá equivocado, con las otras no. Entre las que acertó, volvería a enviar un mail al día siguiente, haciendo lo mismo, pero dividiéndolas en 32 y en 32. Lo mismo al día siguiente: 16 y 16. Llegado a este punto ya existen 16 personas que durante 3 días consecutivos vieron como él acertó la varianza del dólar. Estas personas ya están muy seguras de que Adrián sabe lo que hace en sus finanzas, y muy seguramente, aceptarían un negocio con él.
Esa forma de aprovechar el A/B testing es muy similar a como se hace en la realidad, identificando qué formas de mensajes o de campañas publicitarias tiene mejor efecto.
Jeff Atwood hace una reseña de la película Atrapado en el Tiempo, una película en donde el personaje está condenado a repetir el mismo día siempre. Tras ir intentando distintas combinaciones de su día, él llega a lograr el día perfecto. él lo considera deshonesto, y lo relaciona con otra técnica de marketing llamada Ghetto testing, porque el resultado que llega al usuario final está “pensado y probado” para que realmente le guste. ¿Es realmente deshonesto, o es perfectamente válido?
A/B Testing tiene algunas alternativas. Una de ellas es llamada A/B/N testing, en donde se utilizan varias iteraciones. Otra es A/B/A testing, en donde se repite la primer prueba para verificar que los resultados fueran realmente consistentes y no mera casualidad, etc.
Para más información, pueden visitar los artículos de Wikipedia sobre Choice Modelling, Adaptive Control, y Multivariate Testing.
Como extra, debo aclarar que la reseña de Atrapado en el Tiempo es impecable.
Soy un zorrinito testeado.
**UPDATE 28/7/2010: **Marc Von Brockdorff escribió un artículo sobre la medición de la validez estadística de un test A/B: AB testing Statistical Significance. Por otro lado, me encontré en WebDesignerDepot una muy buena guía llamada A Complete Guide to A/B Testing.
I just found out that the “Start page” for Visual Studio can really provide nice interesting articles and news. It’s there where I found a link to an unfinished series of posts called Parallel Programming. These are part of the C# Frequently Asked Questions blog, one of the very interesting blogs around the MSDN.
These specific posts I mentioned are some techniques that we can take advantage of in C# (of course, VB also applies) to easily develop multi-thread applications without struggling with the bared thread objects. Of course, being based in .NET Framework 4, we have a lot of new features we can take advantage of.
Happy Friday to all!
I’m a parallel little skunk.
Hace pocas horas Peteris Krumins (@pkrumins) anunció que en poco tiempo estará saliendo al público su nuevo proyecto con James Halliday.
Dicho proyecto, llamado StackVM, tiene como propósito poder insertar máquinas virtuales en páginas web, darles conectividad entre ellas con simple pasos como drag & drop, y la cantidad de usos que esto podría tener son miles.
Entre los ejemplos que él menciona en su anuncio, están la posibilidad de dar una demo “live” de un software (que podría incluir por detrás todo el entorno necesario para mostrarlo, incluyendo servidores de bases de datos, incluyendo routers, etc). Podría demostrar online (sí, en la misma página web) el funcionamiento de un software cliente servidor, de un software firewall, o cosas que por lo general son muy complejas de demostrar.
Otro de los ejemplos es la enseñanza, testeos de seguridad, o la posibilidad de que los estudiantes realmente interaccionen con entornos virtuales sin otra necesidad que un navegador.
Otro de los ejemplos es el testeo de aplicaciones. Imaginen probar su software en un entorno Linux, un Mac OS, un Windows en distintas versiones, sin más que un navegador.
Actualmente están de a poco liberando muestras para distinta gente, solo tienen que apuntarse para ser tenidos en cuenta si es que lo quieren probar.
Soy un zorrinito virtual.
Gracias a @Analton llegué a un artículo llamado Never user $_GET again, que habla de cómo ya no deberíamos utilizar más las archi-conocidas variables globales de GET y POST al programar en PHP. No sólo eso, sino que explicando los conceptos de validación y sanitización nos deja como paso siguiente ir al manual de PHP, y explorar una sección que quizá muchos ya no tengamos del todo frescas.
Esta sección es la de Filtering, en donde nos vemos introducidos a distintas funciones que ya efectúan validaciones de determinados tipos de entrada en particular, y nos permiten filtrar el resto de lo ingresado para obtener valores correctos, o al menos, lo suficientemente corregidos como para que no dañen nuestro código.
” ¿Desde cuando está eso ahí?”, algunos preguntarán. Desde PHP 5.2, de forma que ya tiene un ratito ahí, no sé como a muchos se nos pasó de largo. Aprovechen a reaprenderlo y será más fácil programar la entrada de datos!
Soy un zorrinito preprocesado.
Esperemos que pronto podamos volver a la frecuencia común de los links del día. Mientras tanto, intentemos mantenerlos cortitos para que no tomen demasiado tiempo.
Hoy los dejo con SQL Dumpster, un sitio con una muy buena idea, pero desafortunadamente, algo abandonado. La idea del sitio es que podamos agregar nuestro script SQL con los datos que queramos compartir al mundo. Cualquiera, nosotros incluidos, podemos navegar por los scripts disponibles según lo que necesitemos. Por ejemplo, ¿necesitamos un listado de países? No hace falta más que ir a la sección de scripts geográficos y lo encontraremos listo para ejecutar en nuestra base de datos. ¿Queremos un listado de tipos de empleo? Ahí están.
Como esos podrían haber muchos más que no sean útiles, y si el sitio se hiciera conocido, sin duda tendría muchos scripts muy útiles.
Soy un zorrinito compartido.
Probablemente conozcamos ya el concepto de recursividad. Si no lo conocen, para entenderlo van a tener que entender el concepto de recursividad. =P
La recursividad, según la define la Wikipedia, es un método de resolución de problemas que se basa en su propia definición. Para decirlo de forma más tangible, un problema se puede reducir a más de un problema de la misma naturaleza pero de más fácil resolución. (El típico ejemplo es el factorial: n! = 1 × 2 × 3 × … × n puede resolverse como n × (n-1)!, que se puede resolver como n × (n-1) × (n-1-1)!, hasta que (n-…) = 1 y entonces 1! = 1, 2! = 2 × 1 = 2, 3! = 3 × 2 = 6, 4! = 4 × 6 = 24, etc.).
Lo curioso es que esto no solo aplica a la matemática, ni a la forma de programar algoritmos. Pensemos en una especie de recursividad conceptual. Por ejemplo, la definición de la palabra definición. O en un método para mostrar cómo se resuelve ese método.
Y ese último caso que queremos ver es el que trataremos hoy. Russ Cox publicó en su blog research!rsc un artículo llamado Zip Files all the way down, en donde cuenta cómo generó un archivo zip que se contenía a sí mismo. (Por supuesto, está ahí para que lo bajemos y revisemos a gusto.) También cuenta cómo es que se embarcó en la empresa de generar un programa que escribiera su propio código fuente. Cómo lo hizo? Hay que leer el artículo. ;)
Soy un zorrinito de zorrinito de zorrinito de zorrinito de …
¿Recuerdan los posts viejos sobre cómo convertir un texto en una expresión regular acorde (Text2RE), y sobre cómo visualizar las expresiones regulares (ReAnimator)?
Bueno, si esas les gustaron o les fueron útiles, vamos a dar dos nuevas utilidades para trabajar con expresiones regulares.
La primera de ellas es Regular Expression Library (o RegexLib). Como su nombre lo indica, es básicamente una librería de distintas expresiones regulares para distintos usos. Podemos buscar también por categoría o palabra clave, y tras eso, elegir del listado aquellas que tienen una mejor puntuación, o la que mejor se adecúe a nuestras necesidades. Por supuesto también podemos contribuir con las nuestras, y al mismo tiempo probarlas en el mismo sitio.
La segunda herramienta es RegExr, de GSkinner (gracias Seinkraft!), una herramienta basada en Flash que nos permitirá experimentar con expresiones regulares, basándonos en nuestro propio texto, o en expresiones de ejemplo pre-armadas que podemos seleccionar para utilizar. Podemos luego guardar las que hayamos construido para su posterior uso, y también ver las que otra gente ha construido.
Soy un zorrinito regular.
Quizá muchos sepamos que existen varios agregadores de datos para la vida web. Lo que hacen es coleccionar datos de distintos lugares y mostrarlos en uno solo. Muy bueno para poder mantener toda nuestra actividad web concentrada, y poder mostrarnos de alguna forma en ese lugar en particular.
Ha habido varios intentos de esto, pero uno de los más interesantes para probar es Pubwich, una aplicación web open source creada en PHP que nos permite incorporar varios servicios. Según parece, tiene actividad muy reciente, por lo que de a poco iremos encontrando mejores funcionalidades, más integraciones y menos bugs. Los servicios que actualmente son soportados son Delicious, Dribble, Facebook, Flickr, Github, Goodreads, LastFM, Readernaut, Reddit, Slideshare, StatusNet, Twitter, Vimeo, Youtube, y pronto estarán sumados Digg, Ffffound, y Foursquare. Como extra, podemos integrar cualquier feed RSS o Atom, con lo que incluso si nuestro servicio no se encuentra definido, de alguna forma podemos darle más funcionalidad.
Y este servicio solo requiere Apache y PHP5. Podemos bajar el código para usarlo desde su repositorio en Github, o ver un demo online. Personalmente, creo que estaría mucho mejor si es que guardara datos viejos y nos permitiera visualizarlos.
Alguno lo utiliza? Qué opinan ustedes?
Soy un zorrinito integrador.
Jarlsberg (un tipo de queso) es el nombre de una aplicación hosteada en Google App Spot dedicada al entrenamiento informático. Esta herramienta nos provee de una plataforma libre en donde podemos probar ataques de seguridad y no romper nada. Al mismo tiempo, los tutoriales también nos irán explicando los distintos conceptos y la forma en que deben de ser aplicados en este caso en particular. Es decir, tenemos tanto teoría como práctica.
Por supuesto que esta aplicación también forma parte de Google Code University, el cual se encuentra repleto de distintos cursos relacionados (y no tanto también) al desarrollo.
Pero si es que quieren trabajar con entornos hackeables para experimentar / jugar / aprender, siempre tienen a WebGoat, las aplicaciones “Hacme” de Foundstone, y otras varias más linkeadas desde IronGeek (BadStore, Damn Vulnerable Web App, Moth, Mutillidae, Standford Security Bench, Vicnum y WebMaven).
Soy un zorrinito seguro.
Me gusta cuando las aplicaciones son capaces de encerrar mucha complejidad detrás de algo simple de entender y fácil de usar. Este es uno de esos casos. La finalidad de esta aplicación, llamada Soluto (“Anti-Frustration Software”), es de permitir monitorear el inicio de las distintas aplicaciones (sólo Windows por ahora), elegir cuáles deben cargar y cuáles no, cuáles deben ser demoradas para un momento posterior y de esa forma mejorar el tiempo de inicio.
La interfaz es totalmente intuitiva, y muy atractiva. Aviso que para lograr esto hacen uso de la tecnología .NET (dependencia que debemos de tener instalada, o será instalada por nosotros). Tras instalarlo vamos a reiniciar y ver cómo Soluto monitorea nuestro inicio. Luego podremos verificar cuáles son los programas o servicios que están cargando al inicio y que podrían removerse para mejorar esta velocidad.
Y cómo saber cuál remover y cuál no? Soluto lo muestra claramente en dos formas distintas. La primera forma es una clasificación que hace, en donde existen tres grandes categorías: lo que sin duda podemos remover, lo que podemos dudar o debemos ser más interiorizados como para decidir, y los que son requeridos y no podemos tocar.
En el fondo todo se basa en la segunda forma de clasificación, que es a través de la configuración de los distintos usuarios. Soluto nos va a mostrar qué porcentaje de usuarios ha hecho qué cosa con cada uno de los programas. Nosotros también podemos brindar nuestras sugerencias.
Por último, Soluto también nos muestra un historial de “velocidades” de inicio, para que podamos ver de qué forma ha mejorado o empeorado nuestra performance de booteo desde que lo hemos instalado y a través de las distintas configuraciones e instalaciones.
La web: http://www.soluto.com/
Soy un zorrinito optimizado.
Hace no mucho se hizo popular un script llamado pdf.js, un agregado sobre node.js que permite la generación de archivos PDFs directamente desde el navegador. Más allá de la novedad, parece que este es solo un proyecto de los muchos que tiene Marak Squires, un ingeniero de software que publica cosas muy interesantes, sin mentir (como lo dice él).
En su blog encontraremos cosas de verdad interesantes para los que se desarrollen en este área, como por ejemplo Front-End Developer Manifesto, una guía práctica de puntos a seguir para aquellos que desarrollan HTML/JavaScript.
Por si no fuera poco, me encontré con su sitio en GitHub, y ahí podemos ver la enorme cantidad de proyectos que tiene, muchos de ellos relacionados íntimamente al JavaScript. Unos ejemplos de su autoría son machine.js (un convertidor de hojas de estilo CSS a máquinas de estado), JSLINQ (una migración de LinQ a node.js), node_mailer (una utilidad para el envío de emails desde el browser), say.js (un text-to-speech en JavaScript), play.js (para reproducir sonidos), o asciimo (sitio web - para crear arte ASCII).
Tenemos mucho para ver, pero seguro que algo de todo eso nos será útil, y por qué no, quizá podamos extenderlo.
Soy un zorrinito JavaScript.
Xyle es un debugger HTML/CSS para Safari (ya que seguramente todos los que utilicen Firefox estarán muy contentos con Firebug). Cabe destacar que si bien Xyle es solo para entornos Mac, la forma de presentación de la información es bastante distinta, algo novedosa. Personalmente, me parece algo intuitiva a la vez de elegante, con lo cual con mucho gusto lo probaría.
Para leer un review al respecto (y una pequeña comparación con Firebug), pueden leer un artículo de DesignShack sobre HTML & CSS Debugging Tools, o un review de Xyle Scope en el blog de Carsonified.
Soy un zorrinito debugger.
Hemos venido escuchando hace tiempo la idea de colaboración online, con distintas aplicaciones de distinta índole y orientadas a distinto tipo de usuarios.
Por un lado tenemos a HyveWorks, un sitio de colaboración para empresas, a modo de comunicación interna para toda la gente que forme parte de la misma. La integración con Kenai de NetBeans es otra idea orientada a desarrolladores y su colaboración online, real-time. Y sé que ejemplos como estos hay miles, pero vamos a pasar a uno en particular, que encontré hace poco.
Esta aplicación en particular se llama Kohive, y es una aplicación que se integra a los navegadores y proveerá aplicaciones de escritorio para colaborar online con otras personas. Lo interesante es la flexibilidad que ofrece: la capacidad de crear distintos perfiles, la capacidad de tener varios entornos de trabajo separados, y por supuesto, búsqueda, comparación y trabajo con documentos dentro de dichos entornos de trabajo. Pronto vendrá la integración con Growl y con iPhone, y por lo que sabemos, gran parte de la aplicación se encuentra en desarrollo todavía, pero parece ser usable.
Alguno ha tenido una experiencia con ella? Qué piensa al respecto?
Soy un zorrinito colaborativo.
Anteayer hablábamos de un sitio con distintos tutoriales, y muchos de estos estaban orientados al diseño gráfico, fotografía o diseño web. Hoy tenemos un sitio muy similar, llamado 1st Web Designer, que se orienta más al desarrollo web o incluso a otras cosas no relacionadas. (De hecho, el logo se parece mucho al de Debian Linux, verdad?)
Yo encontré ese sitio tras haberme cruzado con un tutorial llamado How to create your first Wordpress theme - part 1, pero estoy viendo que hay cosas muy variadas. How to make a sleek Wii controller, 35 Tutorials to get your awesome design print-ready, A crash course in creating e-Commerce websites in Wordpress, son algunos ejemplos.
Ya que estamos hablando de tutoriales y manuales, podemos ver también este sitio llamado Top PDF Manuals, otro sitio de búsqueda de PDFs o eBooks, como hemos visto antes en otros sitios ([1], [2]).
Soy un zorrinito tutorial.
I’ve been looking into some documentation on how testable code should be written. They all say pretty much the same, but I found this article by Isa Goksu which is quite extensive on some particular points, and also provides a good linking to other related articles. He mentions concepts that are closely related to testing and test-driven development, like The Simplest Thing that Could Possibly Work, or Law of Demeter (which is a good design pattern too), some not-as-spread-as-they-should-be Principles of Object Oriented Design, and so on.
Remember we also have Google Testing blog where sometimes guidelines about testing and good testable code is engineered.
Hope it’s a testable Friday for you!
I’m a testable little skunk.
Esta noticia llegó a mí gracias a un tweet de @offsectraining, el usuario de Twitter de Offensive Security, que decía: “Quieren ganar un ticket gratuito de BlackHat a las Vegas? Vengan y hackeen por caridad!”.
El link que daban era el de su blog, que nos cuenta en una nota sobre el concurso HSIYF #2 (How Strong Is Your Fu?) que la primera edición de este concurso fue un éxito, que están esperando que mucha gente participe, y que los fondos recaudados por las donaciones serán enteramente derivadas a obras de caridad.
Fuera de eso, he estado leyendo el blog de Offensive Security Training, y revisando un poco los resultados del concurso HSIYF #1. Como vemos, hay que dedicarle un buen par de horas para tener una versión andando, pero los desafíos no parecen realmente tan imposibles (o será eso una ilusión ahora que veo la solución?). Si ustedes piensan igual que yo, se animarían a participar?
Sólo necesitan un buen tiempo pegado en la silla, la mente agudizada, las herramientas preparadas y una buena conexión a internet (eso ya me dejó afuera).
Alguno va a participar? Alguno se anima?
Soy un zorrinito ofensivo.
Este link es un video, al cual llegué gracias al blog de Thalskarth Maëlstrom (a quién en algún momento comenzaré a llamar “T”), el cual muestra de forma divertida cómo es que un profesor dando una clase sorprende a sus alumnos interactuando con su propia sombra y les da el saludo de vacaciones de pascua.
Fuera de lo divertido y novedoso que resulta (lo cual podemos profundizar en un video donde él nos cuenta cómo lo hizo), hay que destacar algo muy interesante: la sorpresa fue la clave de esta presentación. El concepto novedoso, semi gracioso les permitió a todos mantener la atención centrada en lo que él hacía, sin sentir cansancio ni aburrimiento.
Por supuesto, la presentación no fue muy informativa, pero supongamos que haciendo los mismos pasos, el profesor se hubiera dedicado a enseñarle a sus alumnos cómo es el manejo básico de Windows.
(A partir de aquí voy a contar cosas del video, no lo lean si prefieren ver la sorpresa ustedes mismos.)
El profesor podría haber dicho cosas como “Está borrando mis documentos dejándolo en la papelera!” o “Ahora desde aquí apagaré el sistema para que no moleste más”, o “Quizá si minimizo una ventana ya no la verá y no podrá usarla” (este último es hipotético). Si ese hubiera sido el caso, el profesor estaría enseñando su manejo básico de Windows, orientado a lo práctico, y en una situación tal que los alumnos agudizaran la atención dirigida para asimilar más rápidamente lo dicho.
¿No es eso, acaso, lo importante de una buena presentación?
Soy un zorrinito sorprendido.
Sabemos que los cuatro componentes mencionados (jQuery, MySQL, AJAX y PHP) deben de ser unos de los más comunes para generar aplicaciones web. Cada uno tiene una gran variedad de tutoriales o aproximaciones, podemos buscar y encontrar manuales, libros, ejemplos en abundancia.
Sin embargo, hay algo que resulta muy atractivo, que es lograr buenas aproximaciones, y con “buenas” me refiero a atractivas, usables y novedosas. Ya varios lo han logrado, como es el caso de Facebook, Twitter, Digg y tantos otros servicios con conceptos como el scroll infinito, la manipulación inline del contenido, interfaces avanzadas, etc. Muchos ejemplos pueden servirnos para hacer nuestra propia versión, y como ya alguien me dijo “fijate cómo lo hizo alguien que ya lo haya hecho”.
Para eso el artículo de hoy nos viene muy bien, es jQuery, Ajax, PHP and MySQL projects, de 9Lessons, un compilado de muchos artículos de sus blogs que muestran ejemplos de cosas comunes que querremos lograr, y que, por supuesto, podemos adecuar a nuestras necesidades particulares. Una suerte de cheatsheet pero algo extenso y complejo.
Soy un zorrinito web.
A pedido de JF que está luchando con la performance de algunas aplicaciones web, hago un compilado de ciertos links que fui encontrando hace tiempo, y que de seguro serán útiles a más de una persona para mejorar la velocidad con la que funciona una web application. Especialmente ahora que es tenido en cuenta para su Page Ranking.
Comenzamos!
Eso es todo por hoy, pero seguramente tengo más por ahí guardado que hoy no logré encontrar. A apurar los websites!
UPDATE 21/05/2010:
Agrego los siguientes links que me mandó El Hombre Gris, para optimización de PNGs, parte I y parte II, de la misma idea que el de la optimización de JPEG que vimos antes.
Soy un zorrinito rápido.
In a past link of the day, I have already talked about some distributed NoSQL systems, and the benefits it could bring. I think now it’s time to dive a little deeper in one of them, probably one of the most popular of these days, which is Cassandra.
But instead of going through a long, technical book, lets take this article from Eric Evans called Cassandra By Example, where he gets off all of the theorization and technicisms about these systems, and instead, provides us with a nice example to start from scratch: Twitter. He first explains how would the relational approach should be, and then how the NoSQL approach would be, using Cassandra.
Not only that, we will see some code implementing Twitter features, which is not functional but totally understandable as an example. Then we’ll be able to grasp concepts like keyspaces, column families, reversed columns and so on.
Also, remember that there are already a variety of implementations for Thrift (the client interface) and lots of articles to check out.
I’m a little skunk by example.
Llamó mi atención un artículo en SixRevisions llamado Five Things IE9 is (Actually) Doing Right, y me sorprendió leer que este navegador está tomando un rumbo muy interesante. Más allá de personalmente creer que no llega al nivel de usabilidad que logran otros navegadores (aunque es una opinión personal), realmente está dando un giro refrescante.
Entre las cosas que menciona el artículo (sobre las cuales no me extenderé) quiero resaltar el hecho de soportar los nuevos estándares, cosa sin precedentes, tener una performance realmente increíble, la integración de herramientas de depuración (developer tools) y como extra, la transparencia de los desarrolladores.
Uno de los puntos mencionados allí es el hecho que Microsoft nos permita dar un vistazo a la plataforma de IE9 para probarla, cosa que podemos hacer desde IE9 TestDrive, una experiencia sorprendente, en lo especial para mí. No he hecho mucho más que ejecutar varias de las pruebas en IE9 y en comparación con otros navegadores (Chrome, Firefox) y realmente la forma en la que IE9 está trabajando parece ser la mejor.
Por supuesto, lo que tenemos disponible hoy por hoy es solamente la plataforma de renderizado de IE9. ¿Qué pasará cuando se anexen todas las posibilidades que el navegador nos brinda? ¿Mantendrá su performance y su estabilidad? El tiempo nos responderá.
Soy un zorrinito beta.
Las URLs son un elemento que usamos en nuestro día a día, más seguramente si trabajamos o estudiamos en algo relacionado a la informática. URLs para sitios web, URLs para aplicaciones 2.0, URLs para web services, URLs para todo. Y sin embargo, es posible que usándolos tanto, aún no sepamos cómo se componen en detalle.
Para eso, no es necesario que vayamos a leer el RFC 2396, sino que con leer un artículo de Alan Skorkin titlulado What Every Developer Should Know About URLs, ya sabremos responder gran parte de las preguntas que nos pueden haber surgido, y haber aprendido más de lo que sabíamos al respecto. De hecho, yo me encontré con varias cosas que no sabía de antemano, y yo pensaba que tenía los conceptos bastante conocidos.
Por ejemplo, nunca me había enterado de los Path Parameters, elemento que me parece muy aprovechable. En una pequeña conversación que tuve, me aconsejaron no usarlos por cuestiones de SEO o user-friendliness al momento de compartir URLs.
Soy un zorrinito web.
I spend the first days of this week searching for a good issue tracker with hosted services. Unfortunately, I couldn’t find any that wasn’t paid, or that didn’t force you to share your code with everyone and/or upload the code as well. I ended up using Flyspray, a PHP-based issue tracker, even when I would have preferred another options (like Bugzilla or Trac).
Anyway, that led me to a Wikipedia page called Comparison of Issue Tracking Systems, which is a good way to make a decision based on what you need and what you can use/pay.
Of course, there’s also a Comparison of Project Management Software, and among the products listed there, a lot of them are open source and free. Masters In Project Management (Mr Master) also makes a review of the Top 25 Open Source Project Management Apps.
I’m a managed little skunk.
Hace muy poco tiempo fue que en f8 se anunciaron varios de los proyectos de Facebook para el futuro de la web. Causaron conmoción noticias como la colaboración de enormes empresas (por ejemplo CNN, MTV, Microsoft) y más específicamente, la presentación de OpenGraph, que intenta volver social a la web completa.
Como tal, ya podemos comenzar a utilizarlo. La especificación del OpenGraph Protocol posee un sitio propio que sin duda se irá expandiendo en detalles a medida que pase el tiempo. Hasta que Facebook reconozca a los recursos sociales que existen en la web, muy seguramente nos sirva utilizar integración social de otro tipo en nuestras websites. Por supuesto, no es el único tipo de integración que podemos usar, y para eso podemos interiorizarnos dentro de la documentación para desarrolladores de Facebook.
Sobre OpenGraph, también existe una pequeña presentación que Mark Kinsey publicó en la web Facebook Developers, titulada After f8: Implementing the OpenGraph protocol around the web. Muy simple y muy claro.
Soy un zorrinito social.
Un tiempo atrás tuvimos una lectura que trataba de una visión simple de la arquitectura REST. Sin embargo, hay mucho más por comprender en esta arquitectura.
En este caso me dediqué a leer el artículo de Ivan Zuzak, llamado Why understanding REST is hard and what we should do about it (Por qué comprender REST es difícil y qué deberíamos hacer sobre eso). El artículo es extenso en demasía, pero quisiera dejar alguna suerte de resumen para que no tengan que lidiar completamente con él sin conocimientos previos:
El artículo explica cómo bajo una interfaz simple como REST se esconde una arquitectura muy difícil de modelar. Un sistema que tiene sus puntas desconectadas de a momentos y todavía debe mantener estados puede ser representado con distintos modelos matemáticos, pero ninguno se ajusta a la exactitud. Una vez que se logre modelar y generar una representación formal de esta arquitectura, pueden establecerse estándares que facilitarán el avance. Más que esto, la existencia de un modelo matemático preciso permitirá predecir sus limitaciones y sus capacidades.
Como extra, la especificación de una arquitectura correcta permitirá también concebir buenas prácticas y conceptos de seguridad para la utilización de este tipo de comunicación que de a poco logrará volver a la web semántica.
Soy un zorrinito semántico.
últimamente se ha puesto de moda una buena idea que la gente de PasswordCard ha propuesto. PasswordCard es la idea de tener una tarjeta de colores y símbolos y una combinación de letras mayúsculas, minúsculas y números.
¿Cuál es la idea? Nosotros podemos elegir nuestro password de cualquier punto de la tarjeta. Podemos recordar en dónde se encuentra gracias a los colores y a los símbolos de la primera línea. (Por ejemplo, rojo-triángulo, o celeste-dólar.) Dicha combinación nos dará un símbolo con el que podemos comenzar a escribir nuestro password, copiando los que sigan a continuación. Sólo tenemos que recordar dicha combinación, que es ciertamente más fácil de recordar que el password en sí, y con esta tarjeta nos podemos acordar.
La tarjeta la podemos llevar a todos lados, porque, por supuesto, nadie más que nosotros sabe la combinación con la que comienza nuestro password, de forma que esta tarjeta puede mostrarse públicamente sin miedo a que roben tus passwords.
¿Qué ocurre si perdemos nuestra tarjeta? Podemos simplemente volver a imprimirla. Existe un código hexadecimal que identifica a cada tarjeta. Podemos guardar este código por cualquier problema, para reimprimir nuestra tarjeta si es que la perdemos o se arruina. Por supuesto, el código no indica para nada cuál es el password que elegimos, de forma que aún así no lo estaremos revelando.
Como consideración extra, suponiendo que nuestra tarjeta cayera en malas manos, cada una de las tarjetas tiene 29 columnas y 8 filas. Esto significa, nuestro password podría comenzar en 232 posiciones distintas. Asumiendo que nuestro password sólo se utiliza hasta el final de la línea, existen sólo 232 passwords posibles para esta tarjeta, con lo cual, sería fácil para cualquiera crackear nuestro password. Suponiendo que eligiéramos un límite que no es el final de la tarjeta, tendríamos 8 × 29 × 28 × 27 … × 2 × 1 = 8 × 29! ≈ 70 × 1022 combinaciones. Ya es un poco más seguro. Si comparáramos contra cualquier password de la misma longitud que inventáramos nosotros (es decir, sin uso de una tarjeta), utilizando los mismos caracteres, la combinación sería de 62 (10 números + 26 minúsculas + 26 mayúsculas) × 62… × 62 = 6229 ≈ 951, (y esto es, sin considerar la incertidumbre del tamaño del password) con lo que, en el fondo, la buena memoria está más segura que las tarjetas.
Pero para aquellos que, como yo, tengan dificultad en recordar este tipo de cosas, sin duda las tarjetas serán de buena utilidad.
Soy un zorrinito tarjetero.
I don’t know if you agree with me, but graphics programming is something I always wanted to learn – and will eventually do it someday. For that, we need a book that is as explicative as possible and detailed, going through every concept and being insightful on the concepts. Luckily, I found a web holding a full online version of Graphics Programming Black Book, a full featured book with really deep explanations and concepts.
It goes through optimization techniques and source code examples, even with 3D rendering and known examples as Doom or Quake graphic engines. You may see that the book is quite extensive, and good it is, for 70 short chapters we can really grasp the concepts and get hands to work on C++ and ASM in order to make our graphic programming.
I’m a graphic little skunk.
Nunca viene mal otro link extra sobre HTML5, sabemos que es algo que ya está empezando a tomar fuerza, y de alguna forma todavía es novedad. Mientras esperamos que se decida qué es lo que va a ocurrir con los códecs de video, podemos ir entrenándonos y aprovechando otras features que gran cantidad de navegadores ya aprovechan.
Dejando de lado los links que ya hemos publicado sobre el tema, como HTML5 Test o Dive into HTML5, hoy podemos ver una presentación sobre HTML5 hecha en HTML5, demostrando en vivo y en directo gran parte de las bondades de este nuevo lenguaje, junto con CSS3. El link está en ApiRocks, bajo el título de HTML5 Presentation. Y como si no fuera poco, tenemos una gran variedad de sites mostrando las cosas que se pueden hacer con él.
¡No nos quedemos atrás!
Soy un zorrinito5.
Seguro ya aprendimos que todo lo que comience con una jota minúscula viene relacionado con la familia de jQuery. Y aunque no sean todos los casos así, este sí lo es.
jStorage es un plugin de jQuery que nos permite aprovechar una de las bondades de HTML5, que es el uso de bases de datos a través de JavaScript. Si es que el navegador es viejo y el plugin no tiene la oportunidad de grabar nada, no hay errores de por medio, sino que simplemente al recuperar información veremos que no hay nada. Esto es bueno para lograr compatibilidad con muchos navegadores que puede que todavía no soporten HTML5 Storage o que sean versiones desactualizadas y, por ende, no lo soporte tampoco.
En el fondo es un tipo de almacenamiento de tipo key-value, algo a lo que seguramente estaremos acostumbrados desde el uso de cookies o parámetros, y siendo JavaScript e información de cliente, por supuesto, vamos a tener que tener muchos recaudos respecto a la seguridad y el tipo de información que vamos a guardar.
Lo bueno es que ya podemos proveer de mucha interacción del lado del cliente, y con datos semi-persistentes, lo cual nos amplia un poco el horizonte de opciones, en donde no necesariamente necesitamos ir al servidor para que la sesión no se pierda por accidente.
Soy un zorrinito almacenado.
Ya hace tiempo venimos mencionando lo nuevo que se viene con HTML5 y CSS3, de cómo van a hacer más fácil la vida de los usuarios de internet, de cómo van a hacer más fácil la vida de los desarrolladores y diseñadores web, de cómo van a volver a la web un entorno semántico de información, etc. Sabemos también que aunque estamos algo lejos todavía de que el estándar se apruebe completamente, muchos navegadores ya han comenzado a implementar sus características. Si mal no recuerdo, fue noticia hace bastante tiempo ya que Firefox comenzó a aceptar los tags
Si queremos verificar cuánto acepta de estas nuevas tecnologías nuestro navegador en cuestión, no tenemos más que visitar la página del HTML5 Test, que nos dará un puntaje para nuestro navegador, dependiendo en la cantidad de elementos que soporte. Yo ando usando Chrome 5.0 y me da un puntaje de 142. Y a ustedes?
Soy un zorrinito 5.
Well… sort of. It’s not anything new these days, but a while ago, Google published it’s own security testing tool for website security testing, called Skipfish. Of course, this is not the first tool that Google releases for this purposes, as many related are already out there (like ratproxy, the Browser Security Handbook, and so on…). However, the new thing today is skipfish.
Skipfish is an active website scanner that will test the web applications for XSS, SQL Injection, Shell injection, XML Injection (that one’s new for me), SSL, insecure cookies, correct MIME headers, server errors, invalid links… etc. The complete list is enormous, and one of the main things is that this tool is being developed on C for high performance. It claims to be able to run with 2000 requests per second on remote servers (of course, if the servers answers in time).
I haven’t had the chance yet to give it a try but I probably will these days. These are the kind of reports that you may see from it, see a skipfish screenshot.
This all came from Google’s Online Security Blog. It is worth a reading, updates are not too much common nor too much big, so you can keep easily up to date with your favorite RSS reader.
I’m a secure little skunk.
Para quién no lo sabe, una Máquina de Turing es una máquina conceptual que consta de una “cabeza” sobre una “cinta” que puede moverse a izquierda o derecha, y leer o escribir. Se supone que con esas cuatro operaciones básicas, la máquina conceptual de Turing es capaz de realizar cualquier algoritmo computable existente. Sí, desde sumar dos números hasta calcular los dígitos de π. Desde revertir una cadena de texto hasta ser un servidor web (aunque lo veo como poco eficiente para eso). Para diagramar los algoritmos que ejecutan, se utilizan estados sobre los pasos que están ejecutando, y lo que se puede leer o escribir trata de un alfabeto en particular (es decir, algún conjunto de símbolos que se le llama alfabeto de esa máquina).
Lejos de ser una metáfora a la publicidades de pasta dental, el Castor Ocupado es un algoritmo para máquinas de Turing que, dada una cantidad de estados y una cantidad de elementos de alfabeto, debe correr tanto tiempo como sea posible para luego detenerse. ¿Qué significa esto en términos de computabilidad? Significa que debe de ser, bajo una cantidad limitada de condiciones, el algoritmo más largo no-infinito, lo cual, de alguna forma es un desafío para encontrar aquello que tome más tiempo de computación y no sea interminable.
¿La razón? No es pura búsqueda por el buscar como muchos pueden suponer (y como muchos lo buscan, por simple diversión), sino que detrás de esto existe la teoría de la computación, en cuanto a qué algoritmos son computables (por ejemplo, parece que los que se encuentran sí, pero el algoritmo para encontrarlos no), qué orden de computación tienen, y seguramente también se relaciona con el tipo de problemas que son computables y no computables, pero dejaré eso para el futuro.
Hubo alguien más, Peteris Krumins, que le encontró una veta artística. Por un lado, hay un video en Youtube de una máquina de Turing (construida) corriendo el castor ocupado, y por otro lado, Peteris mismo hizo un programita que va dejando un archivo con el estado de la cinta a medida que la máquina va ejecutando, y de ahí, generar una imagen en donde se vea gráficamente. En su blog, en el artículo del Problema del Castor Ocupado, habla de los algoritmos y los resultados que obtuvo ejecutándolos. Curiosas las imágenes, e impresionante la imagen de 5 estados y2 símbolos, para verla completa hace falta una bueeeeeeeena pantalla.
Soy un zorrinito ocupado.
A aquellos que programamos SQL nos encontramos muchas veces con lo que se encuentra cualquiera que programa cualquier otra cosa: tener que resolver un problema que seguro ya alguien resolvió. Para esto están los fotos, Google, sitios de soporte, StackOverflow, ExpertSexChange (a drede) y tantos otros lugares.
Hoy dejaré otro lugar que es de buena referencia para varios problemas comunes en SQL, algo que a muchos puede costarnos porque seguramente todos aprendimos a programar imperativamente y el álgebra relacional puede que no sea nuestro fuerte. El link en cuestión se trata de Common Queries Tree, que dice ser una extensión de Common MySQL Queries, y de los manuales de referencia de Artful Software.
A mi me ha ahorrado varias horas y dolores de cabeza, espero que a ustedes también.
Soy un zorrinito relacional.
I know that Google has products for everything, and they’re still creating new things, making more and more enemies in different business. Besides that, we have the user’s data concern: what about privacy? What about having other options? What happens to our Google data?
Well, Google has made a step forward into that, creating DataLiberation.org, or, known by it’s full name, The Data Liberation Front (politics, anyone?). The mission for this project is that all users should be able to control the data they store in any of Google’s products. And to approach that mission, you may check for instructions on how to import or export data from any of Google products, and how to make it compatible with different options.
For example, you may as well want to download your Google Docs to use Microsoft Word. Or maybe you want your AdWords data in HTML. Or maybe you want to download back your videos from Youtube.
There are plenty of options, and ideally, each of Google’s products should have a way to back up your data and use it in another service or any way you like. It is supposed that it’s your data. (However, licenses may state else.)
I’m a compatible little skunk.
Si bien ya alguna vez publiqué un link en donde había un listado de software libre ordenado por categorías, estoy seguro que ese listado ni es extensivo, ni es completo, ni cubre las necesidades de todos. El software gratuito y libre abunda y, aunque opino que no existe software de calidad necesaria para reemplazar a todo el software prioritario, no podemos decir que nuestras necesidades no se encuentran cubiertas bajo el paraguas del no-pagar.
Aviso que no quiero hablar aquí de la mentidad del software libre contra la del software cerrado (en la cual, mucho del freeware posiblemente caiga). Sé que existe la diferencia pero no quiero remarcarla aquí, yo quiero afrontar esto ahora desde el punto de vista de los usuarios, nosotros, quiénes lo que queremos es “una alternativa gratis”.
Y para alternativas gratis, tenemos muchas. Dónde buscar? Mi primera aproximación es siempre SourceForge.net, seguida de Google Code (quien está lejos del primero). Pero a veces estaría bueno poder browsear por categorías y es aquí en donde voy a dejar algunos listados que pueden sernos útiles, al menos para ver alternativas de nuestro software actual y, quién sabe, descubrir alguna alternativa gratis que nos guste más. (Eso a mí me pasó con Notepad++, por ejemplo. Ya no sé con qué reemplazarlo.)
El primer listado está bien ordenado según funcionalidad. “I want a freeware utility to…” y completar la frase con aquello que nos interese. Otro de ellos es simplemente un listado que alguien hizo en un foro, pero no deja de ser una buena fuente (aunque es más seguro que con el tiempo pase a estar desactualizado - y ya debe de estarlo ahora, sabiendo que el post es del 2006).
El tercero y último que puedo compartir hoy es llamado el OSSWin Project: OpenSource Software for Windows. En el fondo, no todo es para Windows (como FreeDOS, por ejemplo, jeje), pero no deja de ser otro buen punto de partida, especialmente si este es nuestro sistema operativo.
Soy un zorrinito gratuito.
Gracias a DG quien me compartió este artículo en Google Reader, me enteré que Twitter va a estar migrando sus servidores de datos desde un modelo relacional (que en este caso se trata de MySQL) a un modelo no relacional, en este caso, un family-value non-relational database management system (digan eso cinco veces, bien rápido).
Básicamente de lo que se trata es que ya los datos no se encuentran “atados” por relaciones, o disgregados según los datos relacionados que poseen (lo cual se conoce como leyes de la normalización). Dejemos de ser relacionales por un momento y pensemos las grandes ventajas que esto nos puede traer. Más allá de lo raro que se nos puede hacer, la escalabilidad que esto permite es impresionante.
Para que tengan una idea, este sistema en particular, llamado Cassandra, comenzó a desarrollarlo Facebook, lo compró Google y lo hizo Open Source. Está pensando especialmente para sistemas con muchísima información y para escalar y replicarse fácilmente, agregando, quitando, o moviendo nodos que formen parte de todo el sistema de almacenamiento.
Muchos de los sistemas bajo esta denominación de NoSQL cumplen con estas premisas, los invito a visitar el artículo de Wikipedia sobre NoSQL y ver lo que se dice de varios de estos.
Soy un zorrinito no-relacional.
Yo me enteré mucho tiempo atrás de TopCoder cuando se hizo famoso casi comenzando (y cuando el diseño del sitio era totalmente distinto), por las competencias entre programadores, y como una especie de entrenamiento para mejorar. Todo el tiempo se están realizando competencias de programación. Antes eran solamente de desarollo, pero ahora se pueden hacer competencias de diseño de arquitecturas, de diseño de programas, de suites de testeo, en fin, de un montón de cosas relacionadas al desarrollo de software.
Yo hace mucho tiempo me había anotado, pensando en que algún día encontraría tiempo para experimentar una comptencia, pero nunca lo encontré. Ahí está mi usuario todavía juntando polvo.
Lo que me hizo volver a este sitio es ver otro aporte que ellos dan que se volvió muy famoso, y son los TopCoder Algorithm Tutorials. A diferencia de lo que parece decir el título, no son tutoriales sobre algoritmos pre-armados, sino que hablan de una gran variedad de cosas, desde cómo planificar eficientemente las tareas de desarrollo, hasta distintas técnicas a utilizar para el desarollo.
Muy interesante, y muy bien explicados algunos, vale la pena pegarse una mirada porque seguramente algo de lo que leamos sea aplicado en el día a día.
Soy un zorrinito olvidado.
I think that most of you already know the story: Google started as an academic project, and in that project, they introduced several new ideas that were used to detect the “relevant” pages among a great number of them. That is what we today know as PageRank.
However, have any of you read the original paper they made? If not, you can take a look at it here, it is called The Anatomy of a Large-Scale Hypertextual Web Search Engine.
Besides that, the Wikipedia holds a great amount of information and examples on PageRank, and how does the algorithm works. We know that this has been improved over the years and that not all the details are public until now, but Google helps us by uploading lots of information on different sites, like GoogleWebMasterHelp user profile on Youtube, Google Webmaster Central (home of the webmaster tools), and the Google Official Webmaster Central Blog.
I know, yes, they help us to do something on they way they like to be on a listing they made. Sounds circular, but they’ve done lots of things and if we want to get to the people, they are a really good shot.
I’m a Googler little skunk.
Gracias a kangrejo, quién me compartió la noticia a través de Google Reader (pero que leí en Google Buzz), me enteré que hace unos dos o tres días, Microsoft publicó la especificación de los archivos PST, es decir, de las carpetas personales de Outlook. Microsoft los publica bajo una licencia que básicamente dice: “te digo de onda que no te voy a hacer problema si lo usás… pero igual tengo la posibilidad de hacerlo.”
Independientemente de eso, siguiendo el link y llegando a la especificación llegué a la mencionada especificación en MSDN, y me enteré que no solo se encuentra allí dicho formato, sino que muchos otros formatos se encuentran publicados para hacer uso de ellos de la forma que más queramos. Podemos verlos en Microsoft Office File Format Documents, en donde encontraremos especificaciones de formatos como OpenXML (como era de esperar), PPT, PPTX, XLS, DOC y más…
Por si fuera poco, podemos visitar también una sección más arriba llamada Open Specifications, que es desde donde tenemos acceso a todas las especificaciones que Microsoft ha publicado. Tenemos muchas cosas, como protocolos de Windows (ejemplos: Front Page Server Extensions: Website Management Specification, Message Queuing: ActiveX Client Protocol Specification, Shell Link (.LNK) Binary File Format, etc), o Protocolos de Exchange, o Protocolos de SQL.
En fin, mucho para mirar para quien quiere meterse del lado de adentro de Microsoft y operar con sus datos.
Soy un open zorrinito.
It’s been a while now I’m following the RSS feed of a site called Exploit-DB. In fact, this site was created by Offensive Security, the same guys that are the creators of Backtrack, the widely-known Linux distribution for penetration testing and security auditing.
What I like most of the site are the papers. Most of them are truly enlightening and even inspiring. The last ones I’ve read are Inyección SQL en MSSQL - HackTimes, [Spanish] PFD - Partial Function Disclosure and The (in)security of Omegle - What Omegle users should know. All of the papers are easy to understand and well documented, even with pictures and examples of what they talk about.
Not so far from here, I found the site called HackTimes, with lots of articles to read about security measures, hacking techniques, ideas and more. I’ve just read an article about Fuzzy Hashing and it seems totally interesting.
I’m a secure little skunk.
Ayer Xyborg compartió un link llamado jQuery and general Javascript Tips to improve your code. No sólo me encantaron los consejos que ahí aparecían, sino que me encontré con que dicho artículo tiene una secuela, llamada More jQuery and General Javascript Tips to improve your code.
Ambos artículos son muy detallados y concisos, con un montón de items interesantes que se pueden utilizar a modo de check-list para tunear finamente el código que hayamos hecho en jQuery. Algunos consejos probablemente no los vayamos a utilizar en el momento, pero sabiéndolos, en el futuro podremos mejorar un poco nuestras prácticas. Por ejemplo, quizá no usemos la consola o no usemos el almacenamiento de datos en los objetos, pero conociendo eso, a futuro podríamos hacer las cosas de forma más simple.
Otros consejos los podemos aplicar siempre: utilizar siempre IDs en lo posible para las búsquedas (o anteponer un ID en la búsqueda de clases), otros están apuntados a la performance, a la elegancia de código o a la reutilización del mismo, otros son snippets que podemos reutilizar para nuestras necesidades y otros son consejos para proyectos que pueden volverse demasiado grandes para verificar fácilmente.
Quien trabaje con jQuery no tiene excusa para no conocer lo bueno de estos consejos.
Soy un zorrrinito JavaScript.
El artículo de WebDesignerWall llamado Using HTML Symbol Entities nos muestra cuáles son las principales ventajas de usar entidades HTML (ya saben, esas que se escriben con su código, como "), y cómo utilizarlas de forma que se vean elegantes y apropiadas. Nos previene de varios errores comunes y luego, cosa que no era menos, nos deja links a otros artículos relacionados de otros sitios.
Los que más me interesaron de esos linkeados fueron el de Big Baer llamado Character Entity Reference HTML 4, y el de W3 Schools llamado HTML Symbol Entities Reference (cabe aclarar que al momento de escritura este link no se encuentra funcionando).
Por último, quiero mostrar algo que había encontrado tiempo atrás, relacionado, y que me pareció terriblemente interesante. En un artículo de Ask the CSS Guy, llamado The Details are in the Symbol Fonts, donde muestra cómo varios diseños han utilizado characteres de Wingdings como imágenes (sí, recuerdan esa fuente? La de los simbolitos?) para crear diseños elegantísimos y muy adecuados.
Soy un zorrinito entidad.
LastPass es un sistema centralizador de passwords que se integra con una gran variedad de navegadores para que autocomplete nuestros datos en los sitios que visitemos. De esta forma, podemos tener una buena cantidad de passwords de alta complejidad sin necesidad de tener que recordarlos de memoria, pudiendo sólo utilizar un password que usaremos en LastPass.
Por supuesto, sabemos que de esta forma, nuestro punto débil puede ser el password de LastPass, pero por supuesto existen medidas de seguridad adicionales para asegurar que no cualquiera acceda como nosotros a la información que este sistema almacena, donde podemos centralizar todo.
Entre las características que posee, existen:
Incluso hay muchos features más ya incluidos que podemos ver desde la sección de FAQs, pero si es que alguno se anima a probarlo y poner su información ahí, no dudo que va a tener una buena experiencia.
Soy un zorrinito centralizado.
I found this article at LifeHacker (which does have lots of interesting articles about technology and life-improving techniques) called Geek to Live: Take great notes - Capture Tools, and, as simple as it gets on the advices that it gives, it is amazingly interesting to share and to start working on.
The main article focuses on some techniques to take notes quickly and not loosing any detail when you’re doing it at a meeting or hearing a lecture, etc. It is also great feedback if you are the one giving a lecture of speaking publicly about something and want someone to take notes about what you said. You may use it to study, to improve your speaking abilities, and make great summaries.
I know this is something we all have got a place to apply it, so take a peek and improve your note-taking abilities!
I’m a note-taking little skunk.
Uno de los lenguajes que más furor está haciendo en estos días es Ruby. De hecho, es el lenguaje en el que está programado Twitter. Para curiosos como yo que les gustaría probarlo, se encontrarían con la desventaja de que no es del todo fácil la instalación en algún sistema de los intérpretes (excepto que estés usando alguna distribución de Linux para tus tareas diarias, o que puedas utilizarlo sin problemas). Si es el caso, entonces es cuando TryRuby.org se amolda perfectamente an nuestras necesidades.
TryRuby es un intérprete online de Ruby que nos lleva a través de un tutorial para aprender las cuestiones más básicas del lenguaje y nos permite experimentar con ellas online, solo desde el navegador. Por supuesto, esto no nos dejará estar guardando archivos ni generar proyectos, pero por lo pronto, es suficiente como para probar un poco y ver qué ocurre.
Yo he tenido problema ingresando algunos caracteres (como queriendo borrar errores de tipeo o queriendo ingresar caracteres que no están directos en el teclado y que requieren teclas adicionales - como corchetes, llaves y cosas así), pero si es el mismo caso el de ustedes, con utilizar el código ASCII de ellos se soluciona.
Soy un zorrinito rojo rubí.
Me encontré con un artículo en Adminx Web llamado 17 Javascript Animation Frameworks Worth Checking Out, una muy buena compilación de frameworks JavaScript que, más o menos fácil (depende de cada uno) podemos integrar a nuestras aplicaciones web para hacerlas más usables, o simplemente más lindas.
Hubo uno de estos que yo ya había publicado en el pasado, tratándose de GX, y a pesar que muchas de las otras opciones son muy atractivas, me sigue agradando en GX la forma totalmente natural en que se hacen las instrucciones para asignar los pasos de las animaciones. Hay otros que no son tan simples de implementar, pero cada uno tiene sus ventajas y desventajas.
Pasen por la sección de demostraciones o ejemplos de cada una, la verdad es que algunos son increíbles!
Soy un zorrinito animado.
Si es que no han tenido la suerte de probarlo, Greasemonkey (sí, “mono de grasa”) entonces les cuento que es básicamente un plugin de FireFox que permite “agregar plugins” extras. En realidad lo que hace es algo ligeramente distinto: en lugar de modificar la estructura de Firefox, permite inyectar Javascript en las páginas, agregándole / quitándole funcionalidad o automatizando tareas que preferiríamos no hacer a mano. Ya alguna vez comenté de un script de Greasemonkey que funcionaba como CAPTCHA decoder para Megaupload.
Lo maravilloso de esto es que abre un mundo nuevo de posibilidades, es casi como si tuviéramos a una persona invisible frente al navegador haciendo tareas extras o agregando cosas que nos gustaría que las páginas tuviesen.
Resulta que ahora la novedad es que Chrome en su versión 4 (verifiquen cuál tienen) soporta scripts de Greasemonkey sin necesidad de ningún plugin. Es decir, solo con instalar el script ya Chrome lo detecta como una extensión y lo anexa al sistema. La gente está maravillada con esto (ciertamente, yo también lo estaría), pero no he tenido la posibilidad de probarlo en mi caso. Yo tengo en este momento la versión5 (de la rama de desarrollo) y los scripts parecen no funcionar o no hacer nada. Será un problema mío?
Fuera de eso, si quieren probarlo, así sea en Firefox + Greasemonkey o en Chrome 4, solo tienen que pasarse por UserScripts, una comunidad de extensiones para Greasemonkey y elegir lo que más les guste para comenzar a darle esteroides a su navegador.
Soy un zorrinito grasoso.
Hace rato ya que vengo hablando de nuevas tendencias para la web, como SVG, por ejemplo. No fue hasta hace poquito que terminé de leer un libro online introductorio a HTML5, llamado Dive Into HTML5. Me tomó poco tiempo leerlo, debo confesar, porque el libro aún no se encuentra terminado. Verán, de hecho, que los links en la tabla de contenidos se encuentran incompletos, e incluso la sección sobre Canvas se encuentra sin terminar.
El punto es que este libro introductorio nos explica claramente cómo fue la historia de HTML, qué distintos conceptos debemos tener para entender lo nuevo que nos plantea HTML5, y a medida que se van demostrando las nuevas características, nos muestra la forma de usarlas y qué exploradores lo soportan, y cómo soportar nosotros a los exploradores que no.
Mi parte favorita fue What Does It All Mean?, en donde explica los nuevos elementos semánticos, pero no solo eso, sino que toma una página común de HTML4, y nos explica de qué forma podemos ir convirtiendo nuestras páginas para hacerlas HTML4 y HTML5 compatible al mismo tiempo. De esa forma, estaremos listos para actualizarnos cuando los navegadores comiencen a soportar toda esta nueva tendencia.
Soy un zorrinito HTML.
Aquellos que diseñan o programan aplicaciones web saben que, por un lado, se tienen que acortar a ciertos estándares. La innovación demasiado lejana podría confundir a los usuarios. Por otro lado, saben que es muy refrescante innovar y crear formas de interacción nuevas, y la web les permite muchas variantes.
Sin embargo, al momento de ir a trabajar, no siempre es buena idea reinventar la rueda y hacer todo desde cero. Quizá la necesidad de su cliente es cierto trabajo, sin importar la forma en la que se haga, o la forma en la que se vea. Es entonces en donde una solución pre-armada para interfaz gráfica sería muy útil, y es aquí en donde toma sentido el proyecto de Mocha UI, que trabaja sobre MooTools.
Lo único a tener en cuenta (que puede ser peligroso hoy por hoy) es que Mocha UI anda en etapa de desarrollo y, según dicen, puede que sufra cambios algo drásticos en el futuro. Fuera de eso, se ve bastante estable y robusto en la forma en la que trabaja.
Podemos ver los demos de cómo funciona aquí, y haciendo uso del menú de ese demo acceder a varios más.
Soy un zorrinito web.
Muchas veces la usabilidad de un sistema es un requerimiento tan primordial como el funcionamiento en sí, y más en un mundo como puede ser el mundo web, en donde tenemos miles de competidores para servicios similares que podemos estar ofreciendo online. Quien publica primero tiene la ventaja, pero quien hace el servicio lo más fácil de usar y de forma más cómoda e intuitiva es quien logra hacer la diferencia.
El problema es, cómo probar este tipo de cosas? Muchas veces se usan equipos de testing que no tengan conocimiento alguno de la herramienta; muchas veces también se utiliza gente que no está relacionada con el proyecto para nada, o incluso se terceriza este tipo de testeo. Otro problema es que, dado que estos testeos de usabilidad se basan en tratar de ver qué cosas son fáciles y cuáles no, cuáles son intuitivas y cuáles no… cómo obtener resultados homogéneos para cada persona que lo haya probado? Y un tercer problema es: cómo ver fácilmente los resultados en nuestra aplicación?
Usabilla es una aplicación web que quiere encargarse de esto. Tras registrarnos (con sus planes gratuitos o pagos), podemos crear pruebas de usabilidad contra sitios / aplicaciones web, imágenes o diseños. Las pruebas las generaremos en forma de consignas que le pediremos al usuario que realice sobre ese algo que queremos testear. Por ejemplo: “En dónde haría click para registrarse?” o “Qué elementos le llaman la atención de esta página?”
Tras probar con muchos usuarios, podemos visualizar nuestros resultados de forma gráfica, o en la misma página.
Recuerden que como competidor de este servicio alguna vez hablamos de Loop11, que parecía tener la ventaja de permitir la navegación a través de las pruebas, y de esa forma evaluar la navegabilidad de un sitio. No sé si Usabilla lo permita, aunque por lo que ví en las demos parecería que no.
Soy un zorrinito usable.
SVG son las siglas de Scalable Vector Graphics, algo que no es relativamente nuevo (siendo su primera versión en el 2001), pero algo que hace no mucho comenzaron a aceptar los exploradores (qué les tomó tanto tiempo?). Dejando de lado a Internet Explorer, que aún no parece soportarlo de forma nativa (aunque hay plugins), la gran mayoría de los exploradores ya lo soportan, dando la posibilidad de que podamos insertar gráficos interactivos y hasta dinámicos en nuestras aplicaciones web, sólo escribiendo XML.
Con una aplicación que publiqué el otro día pueden verificar en dónde aplicarlo y dónde no para que lo soporten la mayoría de los exploradores, pero si les interesa indagar en cómo funciona y qué cosas se pueden hacer, pueden visitar una guía paso a paso que escribieron en la W3C llamada An SVG Primer, en donde tienen una guía extensa de cómo trabajar con SVG, cómo agregarle comportamiento, cómo agregar animaciones, como usar JavaScript, e incluso tenemos un apéndice con introducción a HTML e introducción a JavaScript si es que no lo tenemos del todo claro.
Soy un zorrinito escalable.
Aquellos que trabajamos en C# y hemos jugueteado un poco con el lenguaje de LINQ sabemos lo interesante que es poder fácilmente trabajar con datos. Hacer una búsqueda por algún campo de un array antes podía ser algo tan trabajoso como recorrer uno por uno, poner en una lista nueva los que cumplían con este criterio, luego utilizar la nueva lista y volver a filtrar si es que lo necesitamos. Ni hablar de trabajar con dos o más listas al mismo tiempo. Sin embargo, LINQ nos permitió realizar trabajos como ese en códigos de una línea como lista.Where(condicion).Select(campo).
LINQ se jacta de ser transparente y poder ser aplicado a cualquier fuente de datos, y acá hubo gente que quizo llevar eso más allá, para hacerlo trabajable de la misma forma en JavaScript, para la programación de cualquier aplicación web, y el manejo de datos listas de JSON. A esto llamaron jLinq, un trabajo de Hugo Bonacci, que en su web publica varios de sus proyectos e ideas.
La verdad es que no sé qué performance tendrá, pero si queremos simplificar un poco el procesamiento de datos de nuesto JavaScript (especialmente si mostramos cosas como tablas, listas o mucha información que se pueda ordenar, filtrar, etc.), esta parece ser una buena aproximación.
Soy un zorrinito mezcla-lenguajes.
Todos saben lo mucho que me apasiona poder encontrar lugares online en donde se den cursos gratuitos de forma medianamente seria, con profesionales que sepan del tema que hablan, y a veces hasta con exámenes que permitan evaluar y certificar que uno sabe lo que estudió. Mi primera aproximación a uno de estos fue con el programa Desarrollador 5 Estrellas de Microsoft (del cual todavía estoy debiendo un par de exámenes), y luego Sun Learning Connection (el cual vi muy completo pero nunca tuve tiempo suficiente de hacer cursos). Ahora me encuentro con otro más, aparte de la cantidad de links que ya he provisto antes, como el proyecto de Academic Earth, o la compilación de Free Lectures, pero no es el caso de ellos.
En este caso, se trata de la Microsoft Virtual Academy, otro de los proyectos educativos de Microsoft para mantener a la gente informada y capacitándose sobre distintas temáticas, muchas, por supuesto, relacionadas a las tecnologías que ellos desarrollan. Está relacionado al resto de la red de TechNet que ellos han creado, por lo cual todos los estudios que desarrollemos con Microsoft se van relacionando a nuestro Live ID, que utilizaremos en todos estos servicios por igual para identificarnos.
Soy un zorrinito alumno.
De casualidad me crucé con un link de un sitio llamado Mic-ro.co(s)m (el paréntesis es porque la URL no tiene la s), que es básicamente una colección de links de este lugar, en alemán. Sin embargo, la sección que más famosa se hizo de este sitio prácticamente estático es la sección de eBooks, que ofrece una buena cantidad de eBooks para bajar y leer (o para leer online) sobre distintas temáticas:
Y por si no fuera poco con eso, hay una buena colección de links en la homónima sección, sobre temas variados también, y si queremos una colección extra de links con cosas relacionadas a los viajes, podemos visitar la sección viajes de este sitio.
Pero por último yo quería mostrar algo que me hizo acordar a los viejos metabuscadores de sitios que alguna vez todos usamos. Si queremos revivir esa nostalgia, podemos usar el metabuscador de mic.ro-cosm.
Soy un zorrinito linkeado.
Alguna vez comenté de los beneficios de un sistema llamado Crossloop, que tenía la ventaja de ser un programita que bajamos, instalamos, y en dos clicks ya estamos compartiendo nuestro escritorio. Esto hacía muy fácil la posibilidad de ayudar a alguien o brindar servicio técnico a distancia (y de hecho, es el uso primario que se le está dando y lo están mejorando para avanzar en esa dirección), pero a veces no necesitamos tanto control, sino solo poder mostrar la pantalla en tiempo real a alguien más, y queremos alguna herramienta que solo con un click, ya tengamos funcionando eso.
Para eso tenemos una nueva tecnología que LogMeIn hace pública, LogMeIn Express. Esta afamada empresa con sus productos de administración remota ahora nos permite bajar un programita de 700 k, que solo con ejecutar ya estamos compartiendo nuestra pantalla, y con pasar un código numérico a alguien más, esta persona no tiene más que ingresar esos dígitos en esa web y ya estará viendo nuestra pantalla en tiempo real. No sólo eso, tambien podemos darle el control y que esta persona maneje nuestro teclado y nuestro mouse, permitiéndole trabajar por nosotros, mientras nosotros miramos lo que ellos hacen.
En fin, lo que me interesa destacar de esto es la simplicidad: un click, y funciona. Así deberían de ser las cosas.
Soy un zorrinito exigente.
Hace un tiempo anduvimos en búsqueda de un buen plugin / framework / herramienta web que me permitiera utilizar gráficos en una aplicación web que nos encontrabamos desarrollando. Pasamos por varias opciones, algunas de las más interesantes siendo jqPlot para jQuery, o flot (también para jQuery), pero terminamos decidiéndonos por OpenFlashChart.
Sin embargo, encontré luego una opción muy útil para sitios estáticos que quizá necesiten solo un poco de HTML, o sitios dinámicos que no quieran incorporar la complejidad de generar gráficos en su código. Esta opción es la que Google Chart API ofrece. Y es tan fácil como hacer un link a una imagen que tenga ciertos códigos que van a determinar el gráfico que mostremos.
Opciones hay muchas, distintos tipos de gráficos, colores, opciones, aunque siendo imágenes, les falta algo que las otras opciones tienen, que es la interactividad. Pero nuevamente, si lo importante es el diseño simple y la tecnología a usar (o tiempo) es limitada, esta puede ser la mejor opción.
Soy un zorrinito graficado.
Para algunos servicios en donde se comparten links, como redes sociales, o como simple comodidad para compartirlos, es muy útil que las URLs sean acortadas. Es decir, que en lugar de tener un http://www.example.com/posts.php?postid=2313&searchterm=search&l=en, podemos tener algo como http://bit.ly/6bCxjl, que lleva al mismo lugar. No sólo eso, muchos servicios de acortamiento de URLs (como Bit.Ly, que acabo de mencionar), ofrecen URL-tracking, que nos permite saber cuánto o de dónde se han usado las URLs que hayamos compartido.
Más allá de eso, quería comentar de un servicio que vi funcionando la semana pasada (ya no, pero tengo esperanzas de que vuelva a funcionar) llamado http://to/. Sí, tal cual, no tiene nombre de dominio. Este acortamiento de URLs parece que lo introdujo el gobierno de Tonga (habrán sido ellos realmente?) y podría acortar nuestra URL de ejemplo a algo como http://to/EVFaj. (No la prueben, no funciona, incluso aunque redireccione, no va a ningún lado).
Pero hasta que ese funcione, podemos probar cualquier cantidad de otros servicios disponibles hoy por hoy, algunos ya muy conocidos:
Cabe destacar que algunos consideran que las URLs cortas “rompen” la internet, porque como usuario, uno no sabe a dónde va a parar, y como bot (como los de Google que surfean la internet), se encuentran con que en realidad los links llevan a un lugar que no es el destinado (ya que estos en realidad funcionan haciendo redirecciones). Para revertir estas situaciones existen servicios como Real-URL, LongURL, Untiny.me y PrevURL.
Soy un zorrinito acortado.
Para cerrar la semana vamos a ver un poquito de nuevas tecnologías web que están aflorando desde hace un tiempo. Comencemos por CSS 3, HTML 5, SVG o Canvas, que son cosas que últimamente están ganando mucho la atención de los desarrolladores multimedia. La pregunta es: cuándo sabremos que esto está disponible para usarse y en donde? Para responder de forma fácil esa pregunta es que tenemos a una aplicación web llamada When can I use…, en donde podemos filtrar según nuestros deseos de compatibilidad y ver qué tan cerca estamos de poder usar estas posibilidades sabiendo que será soportado por el público al que apuntamos.
Como extra (y compensando el link del día de ayer que faltó), les dejo una guía muy didáctica, detallada al extremo llamada Creating a Web App from Scratch. Eso es, cómo se construye una aplicación web, desde que se tiene la idea hasta que se termina y se publica. Muy interesante, y con muchas buenas ideas para aprender cómo organizar un proyecto de este tipo.
Soy un zorrinito web.
Creo que ya éramos varios los que estábamos en busca de alguna aplicación al estilo agenda, pero sin horarios (es decir, no es una agenda). Algo al estilo de listado de cosas pendientes, que pudiéramos acceder y actualizar de distintos lados. Que fuera simple, que fuera fácil de entender, que no haya que rellenar muchas cosas.
Finalmente encontré algo que se acerca muchísimo a eso que buscábamos y, creo yo, que lo voy a estar usando para poder actualizar el listado de cosas pendientes. La idea es básicamente no olvidarse de las cosas que uno debe hacer, no importa exactamente (o no importa tanto) cuándo se tengan que hacer, sólo cuáles son y cuáles ya están hechas.
Les dejo que visiten entonces a Teux Deux, una aplicación web encargada de eso. (via NQB, via swissmiss). Será el nombre una forma rara de decir “To Do”?
Soy un zorrinito atareado.
{kind=link}